1. Introduci la tua esperienza professionale dall’università fino all’ingresso in Orbyta.
Dopo un percorso di studi in Informatica al Politecnico di Torino, ho iniziato subito a lavorare presso una piccola realtà locale, nel modo dello sviluppo software e servizi per gli ospedali e le strutture mediche private.
Mentre apprendevo nuove conoscenze nell’ambito informatico e in quello medico, l’azienda è entrata a far parte di una realtà multinazionale. Questa fase è stata un’occasione di crescita, sia da un punto di vista tecnico che personale: oltre allo sviluppo software ho potuto occuparmi di gestione progetti, sia in Italia che all’estero, e di collaborazione diretta con i clienti.
Dopo diversi anni, di fronte anche alla possibilità di trasferirmi per lavoro all’estero, ho deciso di rimanere a Torino e cercare una realtà in cui poter seguire e coordinare un progetto software da zero. Questa possibilità si è concretizzata con la mia presenza presso un importante gruppo di centri medici in Piemonte. Durante questa esperienza ho collaborato con molte persone, ho affrontato le difficoltà e sfide di un software usato regolarmente da centinaia di utenti ed ho approfondito le mie competenze, in particolare per gli aspetti di architettura software, back-end e front-end.
A maggio 2021 sono entrato a far parte della realtà Orbyta, portandomi dietro il bagaglio di conoscenze ed esperienze acquisito durante gli anni.
2. Di cosa ti occupi e che valore porti all’azienda?
In Orbyta ricopro il ruolo di Technical Leader per la divisione Process Automation Open, che si concentra sulla parte back-end dei progetti, facendo uso di linguaggi e tecnologie open-source, in particolare Java. Mi occupo di analisi, sviluppo e gestione di progetti software collaborando da un lato con gli sviluppatori impegnati sui singoli progetti e dall’altro con il team di sviluppo business.
Ancora prima di iniziare il percorso di studi universitario, l’informatica ha sempre attirato la mia attenzione e curiosità, portandomi a studiare ed approfondire numerose tecnologie. Il percorso lavorativo che ho affrontato dopo gli studi mi ha permesso di integrare le competenze tecniche con la capacità di interagire con colleghi e clienti, soprattutto in ambito internazionale. Sono felice di portare in azienda il mio bagaglio di competenze, la passione per i dettagli e l’attenzione per la precisione.
3. Perché ti piace lavorare in Orbyta?
In Orbyta, fin da subito, ho trovato un gruppo di persone affiatate, disponibili e simpatiche. Poiché penso che il lavoro di gruppo ed i rapporti interpersonali siano molto importanti, apprezzo molto l’ambiente che trovo in Orbyta. L’attività che svolgo mi consente di conoscere numerose realtà ed ambiti, mettendo alla prova le mie competenze e permettendomi di apprendere nuove tecnologie e incrementare le mie conoscenze.
Introduzione
Il New York Times presenta la data science come il settore che promette di rivoluzionare tutte le imprese e associazioni: dal governo, all’assistenza sanitaria, dal mondo accademico, alle aziende. Tuttavia, i ruoli all’interno di questa branca sono svariati e in questo articolo vi daremo una panoramica sulle principali figure professionali attualmente presenti nel campo:
BI developer e Data Analyst
Back-end developer
Data Scientist e AI Engineer
(Big) Data Engineer e Data Architect
Ogni azienda dà definizioni proprie di questi impieghi e delle responsabilità che a loro competono, ma mettendo insieme le concezioni più chiare e comuni su questo tema, iniziamo a descrivere cosa fa un BI Developer.
BI developer e Data Analyst
Uno sviluppatore di Business Intelligence (BI) è incaricato di sviluppare, distribuire e mantenere le interfacce BI. Questi includono strumenti di interrogazione e modellizzazione dati, nonché visualizzazione delle informazioni tramite report ad hoc o dashboard interattive. Una piattaforma per la BI ha 3 livelli: origine dati, warehouse e reporting.
Nel livello dell’origine dati vengono archiviati i dati grezzi. Essi possono essere dati strutturati o non. I dati strutturati vengono archiviati in un formato predefinito e vengono comunemente archiviati nei data warehouse (DWH). I dati non strutturati invece (per esempio, video e immagini) vengono archiviati solitamente invece nei data lake (DL). Entrambi hanno un potenziale di utilizzo del cloud, ma i dati strutturati consentono meno spazio di archiviazione.
Il livello warehouse comprende tutte le tecnologie che facilitano il processo di storage per tutti i dati aziendali e gli strumenti che eseguono l’estrazione, la trasformazione e il caricamento (ETL). In questo modo i dati vengono spostati in un unico database così da standardizzare i dati in formati coerenti in modo che possano essere interrogati efficacemente. La sua implementazione e manutenzione è un campo di responsabilità per gli sviluppatori di database/ETL e gli analisti/ingegneri di dati.
Il livello di reporting è l’effettiva interfaccia BI che consente agli utenti di accedere ai dati, per esempio tramite tool come Power BI, Qlik Sense, Tableau.
I tool di visualizzazione e analisi dati devono essere padroneggiati anche da un buon Data Analyst, colui che consente alle aziende di ottimizzare il valore dei propri asset di dati utilizzando anch’essi dashboard e report ad hoc.
Essi interrogano ed elaborano i dati, fornendone visualizzazioni, aggregazioni e interpretazioni che permettono di trasformarli in informazioni utili al business e al processo decisionale. Hanno quindi meno dimestichezza a livello tecnico per quel che riguarda l’architettura generale che prepara i dati prima dell’ultimo layer, ma hanno forti competenze di analisi e nel dare valore pratico ai dati ottenuti.
Lavorando sull’ultimo layer devono, inoltre, avere le competenze necessarie per interrogare agilmente i dati finali, per questo sono anche responsabili di apportare migliorie ai report e dashboard indicando al BI Developer anche l’eventuale esigenza di implementare o modificare i flussi dati.
Seguono alcuni importanti tool del settore e alcune certificazioni di interesse.
Viene definito back end tutto ciò che opera dietro le quinte di una pagina web, in contrapposizione al front end, che indica invece gli elementi visibili agli occhi dell’utente, elaborati lato client (client side).
Le mansioni di questa figura sono molteplici e possono differire sia rispetto al livello di intervento sul codice, sia sul piano dei processi che portano un prodotto digitale.
Per diventare Back End Developer è essenziale soprattutto conoscere un’ampia gamma di linguaggi di programmazione. Spesso infatti le aziende ricercano Sviluppatori Back End a partire proprio da questo requisito, richiedendo competenze di coding nel linguaggio impiegato nei propri sistemi informatici.
Tra i linguaggi più diffusi e richiesti troviamo: Ruby, Python, C++, SQL, Java e Javascript.
A questi devono aggiungersi anche i framework già predisposti per la programmazione come Spring o Hibernate, nonché competenze di creazione e organizzazione di database digitali (tramite Oracle, MySQL, NoSQL, MongoDB, ecc.), poiché in genere le aziende dispongono già di un database digitale e cercano sviluppatori che siano in grado di operare.Inoltre bisogna tenere conto della velocità impressionante con cui si evolvono questi linguaggi, per cui è bene che uno sviluppatore si mantenga costantemente aggiornato sulle novità in termini di coding e programmazione. Proprio per questo aspetto, consigliamo delle certificazioni focalizzate sulla conoscenza dei linguaggi di programmazione:
I back-end developer lavorano in tutti i settori dell’informatica, e molto spesso, quelli che lavorano all’interno di un team focalizzato nella data science finiscono con lo specializzarsi su metodologie e librerie padroneggiate dai data scientist o data engineer.
Data scientist e AI Engineer
Il Data Scientist è colui che analizza e interpreta dati complessi, combinando più campi, tra cui statistica, AI e analisi dei dati. Il loro lavoro può andare dall’analisi descrittiva, all’analisi predittiva. L’analisi descrittiva valuta i dati attraverso un processo noto come analisi esplorativa dei dati (EDA). L’analisi predittiva viene usata in ambito di Machine Learning per applicare tecniche di modellazione in grado di rilevare anomalie o modelli.
L’analisi descrittiva e quella predittiva rappresentano solo un aspetto del lavoro dei data scientist. Come prerequisito essenziale emerge la capacità di programmare, per esempio usando Python e R, ma anche la capacità di implementare algoritmi sofisticati di ML.
Adesso chiariamo un’importante differenza che spesso viene tralasciata: quella tra un data scientist e un AI engineer.
Gli AI Engineer sono responsabili dello sviluppo di nuove applicazioni e sistemi che utilizzano l’Intelligenza Artificiale per migliorare le prestazioni e l’efficienza, prendere decisioni migliori, ridurre i costi e aumentare i profitti. Un esperto di intelligenza artificiale deve essere in grado di analizzare e associare i principi dell’IA al ragionamento e all’incertezza in qualsiasi ambiente prospettico, saper applicare queste tecniche per l’analisi e la ricostruzione delle immagini, risolvere una varietà di problemi o scenari complessi ma anche per modellare il comportamento umano nello svolgimenti di compiti complicati o completare processi complessi. La valutazione e il miglioramento delle prestazioni delle applicazioni nei domini di intelligenza artificiale e machine learning è un requisito importante che un AI Engineer deve avere ed è importante aver sviluppato consapevolezza e competenza su queste attività principali poiché chiunque lavori nell’IA o nell’apprendimento automatico verrà chiesto di gestire questo tipo di responsabilità quasi quotidianamente. Si tratta di una professione complessa che richiede una grande quantità di conoscenze tecniche ed esperienze specifiche.
Un AI Engineer aiuta le aziende a creare nuovi prodotti di AI efficacemente funzionanti, mentre un data scientist implementa strumenti che utilizzando i dati promuovono un processo decisionale redditizio sfruttando anche l’AI se necessario. Queste figure lavorano a stretto contatto per creare prodotti utilizzabili per i clienti. Un data scientist per esempio potrebbe implementare i modelli di machine learning su IDE mentre un AI engineer potrebbe crearne una versione distribuibile del modello creato dal data scientist integrando i suoi modelli nel servizio finale.
Gli AI Engineer sono anche responsabili della creazione di API di servizi Web sicure per la distribuzione di modelli. In altre parole, un data scientist utilizza l’IA come strumento per aiutare le organizzazioni a risolvere i problemi mentre un AI Engineer per servire i clienti guardando però al business da un punto strategico più basso. Entrambi devono lavorare in modo collaborativo per creare una soluzione che funzioni con la più alta efficienza e precisione possibile quando implementata nella vita reale.
Il Data Architect è specializzato nella progettazione di sistemi informatici per la gestione e la conservazione di dati e informazioni. Egli si occupa di organizzare i dati, impostare i criteri di accesso e coordinare le varie fonti, il tutto con lo scopo di rendere i dati stessi fruibili e funzionali al raggiungimento degli obiettivi aziendali. Utilizzano la loro conoscenza dei linguaggi informatici orientati ai dati per organizzare e mantenere i dati in database relazionali e repository aziendali, sviluppando strategie di architettura dei dati per ogni area tematica del modello dati aziendale.
Le competenze professionali comuni dei data architect comprendono competenze tecniche avanzate (in particolare in linguaggi come SQL e XML), un eccellente acume analitico, una visualizzazione creativa e capacità di problem-solving, e un forte orientamento al dettaglio. Ne consegue che l’Architetto dei Dati, raccogliendo ed elaborando dati derivanti sia da fonti interne, sia da fonti esterne, può essere visto come una sorta di anello di congiunzione tra l’area IT e le altre aree dell’organizzazione.
Chiariamo qua un’altra differenza spesso non sottolineata: i Data Architect progettano la visione e il progetto del framework dei dati dell’organizzazione, mentre il Data Engineer è responsabile della creazione di tale visione.
I data engineer si occupano del provisioning e della configurazione delle tecnologie di piattaforma dati, in locale e nel cloud. Gestiscono e proteggono il flusso di dati strutturati e non strutturati da più origini. Devono anche avere un forte background tecnico con la capacità di creare e integrare API e comprendere le pipeline dei dati e l’ottimizzazione delle prestazioni. Le competenze tecniche desiderate includono la conoscenza dei sistemi Linux, la competenza nella progettazione di database SQL e una solida padronanza di linguaggi di codifica come Java, Python, Kafka, Hive o Storm.
Le piattaforme dati usate possono includere database relazionali e non relazionali, flussi di dati e archivi di file. I data engineer verificano inoltre che i servizi dati siano integrati in modo sicuro e trasparente.L’ambito di lavoro di un data engineer va oltre la gestione di un database e del server in cui questo è ospitato e probabilmente non include la gestione complessiva dei dati operativi.
Un data engineer può aggiungere un notevole valore sia ai progetti di business intelligence che a quelli di data science. Quando il data engineer raccoglie i dati, operazione spesso detta di data wrangling, i progetti avanzano più rapidamente, perché i data scientist possono concentrarsi sulle proprie aree di lavoro. Un BI developer collabora a stretto contatto con un data engineer per assicurarsi che sia possibile accedere a una vasta gamma di origini dati, strutturate e non, a supporto dell’ottimizzazione dei modelli di dati, che sono in genere forniti da un data warehouse o un data lake moderno.
Di seguito alcune certificazioni possibili per un data engineer:
I professionisti che si occupano di Big Data in particolare si specializzano nel trattare set di dati troppo grandi o complessi per essere gestiti dai tradizionali software applicativi di elaborazione dati. I dati con molti campi (righe) offrono una maggiore potenza statistica, mentre i dati con una maggiore complessità (più attributi o colonne) possono portare a un tasso di false discovery più elevato. Le sfide dell’analisi dei big data includono l’acquisizione di dati, l’archiviazione dei dati, l’analisi dei dati, la ricerca, la condivisione, il trasferimento, la visualizzazione, l’interrogazione, l’aggiornamento, la privacy delle informazioni e l’origine dati. L’analisi dei big data presenta sfide nel campionamento, consentendo quindi in precedenza solo osservazioni e campionamenti. Pertanto, i big data spesso includono dati con dimensioni che superano la capacità del software tradizionale di elaborare entro un tempo e un valore accettabili. Ecco un percorso di certificazione per iniziare a studiare il problema: https://intellipaat.com/big-data-hadoop-training/
Conclusioni
Dopo questa panoramica sulle figure professionali del settore analytics speriamo possiate averne un’idea più chiara e, perchè no, di avere ispirato alcuni di voi nella costruzione/proseguimento della propria carriera in questo settore.
Articolo a cura di Lucia Campomaggiore (MS BI Developer) e Carla Melia (Head of Analytics), 14.03.2022
1) Introduci la tua carriera professionale fino al ruolo di CEO Infogest.
Ho iniziato la mia carriera lavorativa nel 1988, quando ero ancora studente, proprio nella quasi “neonata” Infogest , come tecnico informatico. Un rapporto, quello con Infogest e con i suoi soci fondatori, che non si è mai interrotto e che in seguito alla mia fuoriuscita, si è trasformato, è cresciuto e ci ha tenuti uniti con l’amicizia, fino a quando sono recentemente rientrato, per volontà degli stessi, per prenderne il timone.
Dal 1992, rapida carriera nell’information tecnology, con ruoli crescenti, prima sviluppatore, poi project manager e quindi ICT manager presso diverse multinazionali del settore manifatturiero.
La mia intraprendenza ed il mio desiderio di crescita hanno fatto sì che allargassi i miei interessi al controllo di gestione, alla gestione delle risorse umane ed ai processi aziendali. Alle responsabilità nel settore dell’ICT si sono aggiunte quelle sull’organizzazione e sul controllo di gestione. Ormai da quindici anni il mio lavoro è quello di amministratore delegato di aziende PMI nei settori ICT e metalmeccanico.
2) Qual è il valore che Infogest ha portato al Gruppo ORBYTA?
Orbyta è una splendida realtà fatta di giovani ambiziosi e molto competenti; è nata recentemente ma si fonda su solide esperienze pregresse fatte dai soci fondatori, che hanno messo a fattor comune realtà preesistenti con grande potenziale di sviluppo. Orbyta, con grande determinazione, chiarezza d’intenti e competenza, sta costruendo un sistema che funziona bene sia internamente che per i Clienti.
In questo preciso disegno Infogest è andata a colmare uno dei tasselli che contribuiscono a rendere ancora più solida l’offerta ICT di Orbyta Tech. Un valore aggiunto sia per i Clienti che per l’Azienda, ovvero la certezza di comprare l’ Hardware alle migliori condizioni di mercato, non solo di prezzo. Condizioni raggiungibili solo dopo tanti anni di presenza sul mercato, contraddistinti da una condotta sempre seria con risultati sempre positivi e clienti sempre soddisfatti.
3) Quali sono le prospettive per Infogest e come pensi di affrontarle?
Infogest, grazie all’ingresso nel gruppo Orbyta, è destinata a crescere in modo importante nei volumi di vendita e questa prospettiva indica chiaramente una necessità di strutturare opportunamente la nostra organizzazione in modo da riuscire a rispondere alle esigenze di un maggior numero di Clienti con lo stesso livello di qualità che ci ha permesso di restare sul mercato in tutti questi anni, fidelizzando anche i nuovi clienti come abbiamo fatto con quelli che ci premiano con la loro fedeltà ormai da molti anni.
1. Introduci la tua esperienza professionale dall’università fino all’ingresso in ORBYTA.
Mi avvicino al mondo informatica fin dall’adolescenza scegliendo di spianarmi la strada in questo settore studiando e conseguendo il diploma di perito informatico con specializzazione in telecomunicazioni.
Successivamente decido di trasferirmi dalla mia amata Puglia per studiare al Politecnico di Torino. Un percorso di studi piuttosto impegnativo ma mirato a costruire la forma mentis adatta a quella che poi sarebbe stata la mia futura professione. Dopo aver conseguito la laurea triennale in Ingegneria Informatica, proseguo gli studi seguendo la specializzazione in Computer Networks. Mi riavvicino allo sviluppo software durante il periodo di tesi; qui infatti, scelgo una tesi sperimentale in un gruppo di ricerca del Politecnico di Torino in modo da entrare nelle dinamiche di un team di sviluppo.
Terminati gli studi, ho l’opportunità di entrare a far parte di una software house di una prestigiosa multinazionale dove ho avuto il piacere di lavorare con colleghi esperti nello sviluppo web orientato ai servizi finanziari. Col passare degli anni e l’aumentare dell’esperienza sono stato coinvolto maggiormente in tutte le fasi di un progetto: dall’analisi di fattibilità e la stima economica fino al design di applicativi più o meno complessi.
Passano circa 4 anni, prima che decida di iniziare a guardarmi attorno per poter mettermi in gioco in contesti differenti. In questo periodo ricevo la chiamata di Daniele Sabetta, l’attuale CTO che conoscevo e stimavo da tempo, per illustrarmi le potenzialità di Orbyta e l’obiettivo di creare una software house aziendale sempre più stabile e con un maggiore afflusso di progetti chiavi in mano. Da qui, l’inizio della mia avventura in Orbyta e che ad oggi conta circa 3 anni e mezzo di esperienza fianco a fianco.
2. Di cosa ti occupi e che valore porti all’azienda?
Attualmente ricopro il ruolo di Technical Leader della business unit Process Automation Microsoft. Sono coinvolto nei processi aziendali che riguardano l’analisi, lo sviluppo e gestione di progetti che prevedono l’uso di tecnologie mappate sullo stack Microsoft.
Cerco inoltre di destreggiarmi nella gestione del team impegnato su diverse attività in modo da fare da collante tra il team di tecnici e il team impegnato nello sviluppo business.
In pochi anni in Orbyta ho dimostrato di credere in un progetto davvero accattivante affrontando sfide più o meno impegnative e che grazie ad un’ottima guida abbiamo superato sempre brillantemente. Ecco, da parte mia sicuramente c’è sempre stato un entusiasmo positivo anche nelle difficoltà ed una gestione attenta del team per limitare al massimo le pressioni dovute ai diversi impegni e alle esigenze dei vari clienti. Pertanto per concludere, il valore che porto in Orbyta è sicuramente un oculato senso di responsabilità.
3. Perché ti piace lavorare in ORBYTA?
In Orbyta sono circondato da persone altamente qualificate e con molta esperienza. Soprattutto nell’ultimo anno la nostra realtà è stata capace di attrarre professionisti navigati nel mondo dell’Information Technology. Questo mi fa capire che nonostante i successi e i traguardi raggiunti, Orbyta non è appagata ma pronta più che mai a superarsi continuamente per raggiungere brillanti obiettivi.
1. Introduci la tua esperienza professionale dall’università fino all’ingresso in ORBYTA.
Ho iniziato a lavorare nel mondo dell’informatica immediatamente dopo le superiori su attività di data-entry, per poi affrontare una vera e propria gavetta. Partendo dal supporto tecnico end users, passando dal supporto lato server sino ad arrivare a gestire sistemi complessi e ampi per clienti internazionali.
Poco prima di approdare in ORBYTA sono stato service manager dell’end users services di una multinazionale e, complice la mia passione videoludica, ho avuto l’occasione di frequentare un workshop presso un’azienda di videogiochi che ha sviluppato uno dei MOBA più giocati al mondo.
Grazie a queste esperienze ho potuto accrescere le mie competenze lato sistemistico vedendo diverse realtà e settori, dall’automotive al bancario, dall’assicurativo al gaming e alle telecomunicazioni.
Queste realtà variegate hanno aumentato la mia curiosità e passione dandomi lo slancio per certificarmi su diverse tecnologie.
2. Di cosa ti occupi e che valore porti all’azienda?
Ad oggi sono Tech Lead del gruppo infrastrutture, mi occupo di coordinare le attività di natura sistemistica su vari clienti di ORBYTA e fornire consulenze specifiche sulla virtualizzazione di ambienti, hardening e gestione infrastrutturale.
Posso serenamente dire che il mio team è grintoso e coraggioso, poiché lavoriamo perennemente su ambienti produttivi e ci occupiamo di garantire la stabilità, l’efficienza e l’affidabilità delle infrastrutture affrontando problemi di diversa natura.
Mi sono sempre definito un professionista quindi mi sento di dire che il valore che porto è una grande professionalità, attenzione nei confronti dei clienti e dell’azienda in cui credo moltissimo.
3. Perché ti piace lavorare in ORBYTA?
Ho visto vari ambienti di lavoro nella mia vita ma raramente ho notato un’attenzione verso la crescita professionale del dipendente così come in ORBYTA.
L’ambiente è giovane, stimolante, divertente e costruttivo. Il tutto senza mai perdere di vista la professionalità e la serietà che contraddistingue un’azienda di valore.
Di solito sono caratteristiche che uno non considera come prioritarie, ma lo diventano subito quando le trovi e ti ci trovi dentro come in ORBYTA!
1. Introduci la tua esperienza professionale dall’università fino all’ingresso in ORBYTA.
Il mio percorso professionale inizia con il conseguimento del diploma da perito informatico presso un istituto tecnico.
Successivamente ho voluto fare un’esperienza di lavoro all’estero per migliorare l’uso della lingua inglese e per capire come andasse il mondo ICT fuori dall’Italia.
Al mio ritorno ho iniziato a lavorare presso un’azienda di software gestionale nel reparto R&D dove sono rimasto per 4 anni, per poi spostarmi su Milano in un’altra società nello stesso settore. Tuttavia, mi sono reso conto che lavorare in un ambito così specifico poteva limitare la mia crescita professionale ed è così che è iniziata la mia vita da consulente presso un cliente enterprise nel settore automotive.
Durante questa esperienza ho avuto l’opportunità di fare anche qualche trasferta in giro per il mondo entrando a contatto con realtà molto differenti. Dopodiché ho conosciuto il mondo ORBYTA e mi sono appassionato all’idea di imparare a lavorare in ambiti diversi, portando in cambio la mia esperienza professionale.
2.Di cosa ti occupi e che valore porti all’azienda?
Attualmente in ORBYTA ricopro il ruolo di Tech Leader per la BU Digital e Mobile, gestendo un piccolo team di sviluppatori in AREA 51 (la nostra software house interna) per diversi clienti e progetti.
Il mio contributo alla causa di ORBYTA consiste nel portare la mia esperienza e la mia passione per l’ambito in cui lavoro per cercare di introdurre sempre nuove tecnologie e affrontare tutte le sfide quotidiane insieme al team.
3.Perché ti piace lavorare in ORBYTA?
In ORBYTA ho trovato l’ambiente che ho a lungo cercato in altre aziende. Un ufficio di giovani professionisti con grandi competenze, ma anche con tanta voglia di mettersi sempre in gioco e a volte uscire dalla comfort zone per affrontare nuove sfide e imparare cose sempre nuove.
1. Introduci la tua esperienza professionale fino al tuo ruolo in Orbyta.
Ho iniziato a lavorare appena finiti gli studi facendo la più classica delle gavette. Partendo dall’assistenza tecnica allo sviluppo di siti web. Con gli anni e l’acquisizione di nuove competenze, ho svolto la mansione di sistemista, seguendo progetti di grosse dimensioni e lavorando in alcuni dei più grossi CED del nord Italia.
Nel tempo ho iniziato ad interessarmi alle applicazioni e questo mi ha permesso di supportare le grosse aziende in quella che ora è la trasformazione digitale.
In Orbyta porto la mia esperienza di Architect ed esperto del mondo collaborativo della suite Office e più in generale del Cloud.
2. Visto il recente ingresso di Infogest e la tua partecipazione nella società, qual è il valore che quest’ultima porta al Gruppo ORBYTA?
Infogest è una Società storica nel panorama torinese, fondata da mio padre nel 1984, nonché il mio trampolino di lancio nel mondo ICT. Il fatto che grazie ad Orbyta riesca ad avere una seconda giovinezza mi rende estremamente felice e orgoglioso.
Sono sicuro che l’ingresso possa dare maggiore forza all’attività più classica di rivendita ed assistenza sistemistica, andando ad aggiungere un importante tassello al già completo ecosistema Orbyta.
3. Perché ti piace lavorare in Orbyta?
Il primo contatto che ho avuto con Orbyta è stato estremamente positivo. Ambiente dinamico, persone giovani e determinate, tutti molto affiatati e con tanta voglia di spingere e di investire sulle persone.
L’azienda ha visto il mio potenziale oltre alle mie competenze, ed è così che mi ritrovo, soddisfatto, a collaborare con questa splendida realtà.
Negli articoli precedenti abbiamo introdotto la teoria dei giochi (https://orbyta.it/teoria-dei-giochi/) e la teoria dei grafi (https://orbyta.it/teoria-dei-grafi/) e abbiamo visto come quest’ultima possa essere usata per risolvere giochi dall’equilibrio controintuitivo.
In questo articolo approfondiremo le reti andando a studiare i giochi dinamici e situazioni più complesse che ci permetteranno di analizzare la propagazione delle strategie all’interno di un network.
Giochi dinamici
Consideriamo i giochi in cui l’interazione tra i giocatori è intrinsecamente dinamica, cioè in cui i giocatori sono in grado di osservare le azioni degli altri giocatori prima di scegliere la loro miglior risposta [6].
Questo genere di giochi rientra nella categoria dei cosiddetti giochi dinamici insieme a quelli detti sequenziali nei quali i partecipanti prendono decisioni osservando a turno l’azione dell’avversario e stabilendo di conseguenza l’azione ottimale da adottare.
Si noti che l’attenzione non è posta all’alternanza sequenziale dei turni, bensì al fatto che i giocatori effettuano la loro scelta dopo che altri giocatori hanno già mosso, come nel gioco della briscola dove l’alternanza dei turni è stabilita di volta in volta in funzione di chi si è aggiudicato la mano precedente.
Si intuisce che la caratteristica principale di questi giochi è il fatto che le azioni di un giocatore possano influenzare le azioni ottimali degli altri, e questo incrementa il numero delle loro possibili strategie che adesso non coincidono più con le possibili azioni, infatti, a queste vanno aggiunte le cosiddette strategie condizionali.
È importante che i giocatori successivi abbiano informazioni sulle scelte precedentemente effettuate dagli altri giocatori, altrimenti la differenza di tempo non avrebbe alcun effetto strategico.
Esempio dinamico delle aziende
Finora abbiamo lavorato con quella che è chiamata forma normale di rappresentazione di un gioco in cui si specifica un insieme di giocatori e per ognuno di essi un insieme di strategie con i relativi payoff. Per descrivere un gioco dinamico necessitiamo, per esempio, di esplicitare quando e come i vari giocatori possono muovere.
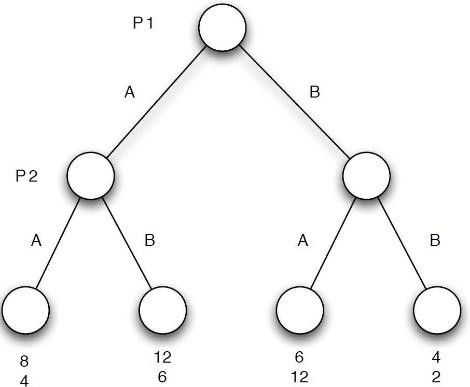
Utilizziamo a tale scopo la cosiddetta forma estesa (o ad albero) della rappresentazione del gioco.
Immaginiamo che ci siano due aziende, P1 e P2, ognuna delle quali sta cercando di decidere in quale, tra due regioni A e B disponibili, focalizzare la propria pubblicità. P1 può decidere prima e supponiamo che:
Se P2 scegliesse di seguire P1 nella stessa regione allora P1 otterrebbe i 2/3 del profitto ricavabile da tale regione, mentre P2 solo il rimanente terzo;
Se P2 scegliesse l’altra regione allora entrambe le aziende otterrebbero il massimo ricavabile dalle zone.
Si assuma però che A abbia un potenziale di guadagno di 12 mentre B di 6. Rappresentiamo tale gioco col seguente diagramma ad albero da leggere dall’alto verso il basso.
Il nodo superiore rappresenta la mossa iniziale di P1 che può essere o A o B, da cui i due rami. I nodi sul secondo livello rappresentano le scelte di P2 che sono a loro volta A e B. I nodi inferiori coincidono con le possibili conclusioni del gioco e sotto di essi vengono riportati i rispettivi payoff di P1 e P2.
Notiamo che, una volta che P1 ha fatto la prima mossa, il comportamento di P2 è facilmente prevedibile:
Se P1 avesse scelto A, a P2 converrebbe scegliere B (questo perchè P2 compara gli output 4 e 6);
Se P1 avesse scelto B, P2 avrebbe dovuto scegliere A.
Ora cerchiamo di prevedere la mossa iniziale di P1.
Se P1 scegliesse A allora ci si aspetterebbe che P2 scelga B e quindi un guadagno di 12;
Se P1 scegliesse B, P2 sceglierebbe A e otterrebbe un guadagno di 6.
Concludiamo perciò che P1 sceglierà A e P2 B.
Generalizziamo ora la metodologia di risoluzione appena usata. Tale risoluzione, utile allo studio dei giochi dinamici, consiste nei seguenti passaggi:
Costruito l’albero iniziamo a considerare i penultimi nodi partendo dall’alto (backward induction). In essi il giocatore che muove ha diretto controllo sul risultato delle vincite. Questo ci permette di prevedere ciò che l’ultimo giocatore farà in tutti i casi;
Ci si sposta al livello superiore e, ragionando nello stesso modo, cerchiamo di capire cosa farà il giocatore nella mossa precedente;
Itero il processo fino ad arrivare a stabilire il comportamento del primo giocatore.
Può sembrare strano, ma il precedente risultato implica che teoricamente il vincitore di un incontro di scacchi (o un eventuale esito di parità) sia noto a priori. Siccome un tale albero ha un numero di nodi al di là di ogni possibile rappresentazione e computazione, la procedura ricorsiva delineata non è fattibile e quindi il gioco degli scacchi continua a mantenere il suo interesse.
In alcuni casi, come in questo esempio, possiamo descrivere il gioco dinamico tramite una forma normale di rappresentazione. Purtroppo, il voler convertire una rappresentazione di tipo esteso in una di tipo normale a volte provoca la perdita di alcune informazioni e non permette, dunque, di preservare la struttura del gioco.
In generale, possiamo assumere che la forma normale sia più usata nel caso di giochi a mosse simultanee, mentre quella estesa sia spesso più opportuna nella descrizione di giochi sequenziali [15].
In riferimento all’esempio, per la conversione ragioniamo come segue.
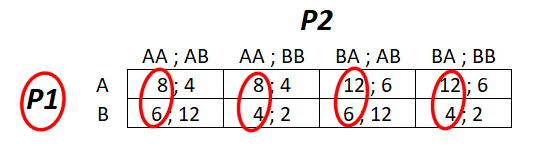
Supponiamo che, prima che la partita inizi, ogni giocatore faccia un piano per capire quali mosse effettuare considerando ogni possibile evenienza. Tutte le possibili modalità di gioco sono (indicando con XY il fatto che P2 sceglierà X se P1 sceglie Y) (AA, AB), (AA, BB), (BA, AB) e (BA, BB).
A questo punto possiamo calcolare le vincite risultanti dalle varie combinazioni di strategie e otteniamo il seguente schema:
Notiamo che per P1 A è la strategia strettamente dominante, mentre P2 non ha una strategia del genere ma le sue migliori risposte sono (BA,AB) e (BA,BB). Poiché P1 sceglierà A avremo che, proprio come ci aspettavamo, P2 sceglierà B.
Diffusione di una strategia
Potremmo in prima approssimazione pensare che l’importanza di un nodo in una rete sia data meramente dal suo grado, cioè dal numero di archi a esso collegati.
L’esempio della seguente figura ci fa notare che ciò non è necessariamente vero, infatti se si vuole far passare un’informazione nella rete, abbiamo che il comportamento del nodo centrale è fondamentale per il raggiungimento o meno del nostro scopo anche se ha un grado basso rispetto a quello di altri nodi.
La centralità di un nodo può essere più proficuamente usata come misura dell’importanza di un nodo nella rete e tale concetto è formalizzato da quello di betweeness. La betweeness di un nodo i è il numero dei cammini minimi passanti da i. In particolare la betweeness centrality del nodo v è la somma, al variare della coppia di nodi s e t, dei rapporti tra il numero di cammini minimi tra s e t passanti per v e il numero di cammini minimi totale tra s e t.
A seguito di quando detto, supponendo di essere un’azienda che voglia diffondere il più possibile una nuova tecnologia A, per scegliere i “nodi chiave” (ovviamente limitati) a cui fornire gratuitamente il prodotto affinché si diffonda in tutto il territorio, dovremmo tenere in considerazione la betweeness centrality dei vari nodi a disposizione.
Il concetto di connessione (o densità) di una rete è esplicato da quello di coefficiente di clustering[11]. Il coefficiente di clustering del nodo i, Ci∈ [0, 1] rappresenta la densità di connessioni nelle vicinanze del nodo stesso, in particolare Ci= 1 se tutti i nodi a esso collegato sono tra loro connessi a due a due e Ci= 0 se tutti i nodi a esso connessi sono tra loro isolati.
Si può calcolare un coefficiente medio di clustering per i nodi della rete per avere una visione più generale della stessa. Se C è piccolo ci aspettiamo un grafo con poche connessioni.
Vedremo che, per il diffondersi di una nuova tecnologia, in generale è auspicabile che la rete non sia fortemente connessa (a differenza di quanto avveniva per il sorgere di una rivolta negli articoli precedenti).
Presentiamo alcuni esempi.
Esempio di reazione a catena [9]
Supponiamo di avere un grafo in cui ogni nodo possa scegliere tra due possibili comportamenti e che se due nodi sono tra loro collegati essi sono incentivati ad adottare la stessa strategia, in particolare se entrambi
scegliessero A otterrebbero un guadagno individuale di a, se entrambi scegliessero B di b, ma se scegliessero strategie distinte di 0. Se ci fossero più nodi vicini, per esempio d, e una percentuale p di loro usasse A, mentre la restante (1-p) usasse B, avremmo che A risulta una strategia efficace da usare se dpa > d(1 − p)b ossia sela somma dei payoff individuali (a) ottenuti dai nodi (d*p) che scelgono A, è maggiore della somma dei payoff individuali (b) ottenuti dal gruppo di nodi d*(1-p) che sceglie B. In sintesi, la strategia A è vincente se p> b/(a+b) , cioè la percentuale di nodi che scelgono A deve superare la percentuale del payoff b rispetto al guadagno totale possibile (a+b). Chiameremo p valore soglia.
Quindi più la connessione di un grafo aumenta (mantenendo fisso il numero di nodi) più è difficile che una nuova strategia, che segue queste regole di profitto, si diffonda partendo da pochi iniziatori.
Si pensi al caso in cui, nel grafo in questione, una parte di nodi scelga A e la restante B. Seguendo il ragionamento precedente alcuni nodi potrebbero cambiare comportamento e si innescherebbe di conseguenza un processo di mutazione della strategia dei nodi della rete che terminerebbe al raggiungimento di una condizione di stabilità.
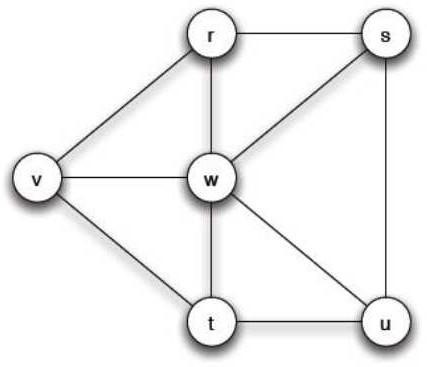
Si prendano per esempio a=3 e b=2 e si consideri il seguente grafo
dove all’istante iniziale tutti i nodi scelgono B, tranne v e w che scelgono A. Denotando con p il
valore soglia b/(a+b) notiamo che q = 0.4, quindi se almeno il 40 per cento dei vicini di un nodo avesse una data strategia anch’esso la adotterebbe.
Notiamo che r ha come vicini v, w, s. Di questi ne abbiamo 2 su 3 che scelgono A (cioè il 66 per cento), quindi r passerà alla strategia A e a quel punto farà la stessa cosa anche s (avendo 2 vicini su 3 che scelgono A) e di conseguenza w e v la manterranno. Si arriverà rapidamente alla propagazione totale del comportamento A. Otteniamo dunque una “reazione a catena”.
Esempio di non-propagazione
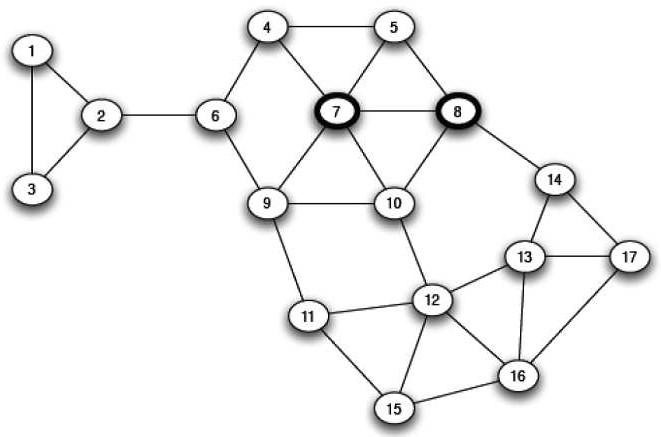
Si consideri la situazione precedente ma in riferimento al grafo sottostante, in cui i nodi evidenziati hanno adottato la strategia A.
E’ facile verificare, con l’iterazione del ragionamento precedente, che non vi sarà una cascata ma solo i nodi 4, 5, 6, 7, 8, 9 e 10 avranno, una volta stabilizzata la situazione, scelto A.
Per ampliare la diffusione di A quel che si può fare è
Diminuire il valore di q, per esempio aumentando a;
Focalizzarsi su alcuni nodi chiave a cui far adottare la strategia A, ma come sceglierli?
Un cluster di densità P è un insieme di nodi tali che ognuno di loro ha almeno una frazione P dei suoi vicini in tale insieme. Una cascata si conclude quando entra in un cluster sufficientemente denso.
Si consideri un insieme iniziale X di individui che adottano la strategia A con una soglia q, definita come prima, che se superata porta i nodi rimanenti (raggruppati nell’insieme Y) ad adottare anch’essi tale strategia. Se e solo se Y contiene un cluster di densità maggiore a 1-q, l’insieme X non riuscirà a realizzare un effetto a cascata completo e quindi a diffondere la strategia A.
Esempio di massimizzazione della soglia
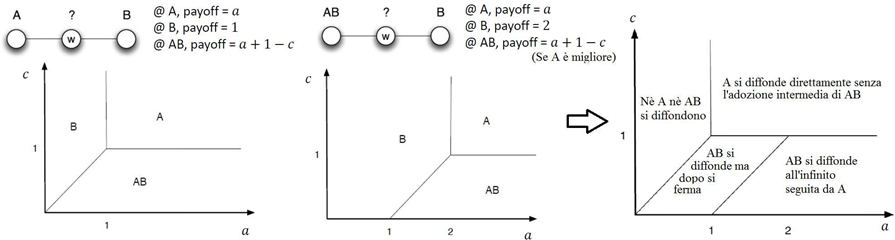
Data una rete possiamo chiederci quale sarà la soglia q più elevata che a essa si potrà applicare ottenendo comunque un effetto a cascata. Questa quantità è chiamata capacità di diffusione, per esempio la capacità di diffusione della seguente rete, in cui i nodi che hanno adottato la nuova strategia A sono indicati in nero, è 1/2 (se raggiunta, infatti, farà sì che A si diffonda come un’onda sulle code).
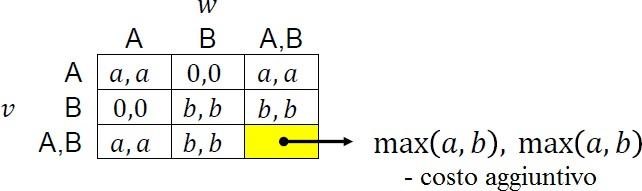
In particolare si può dimostrare che nessuna rete può avere capacità maggiore a 1/2. Supponiamo ora di avere la seguente matrice di payoff
ove ogni nodo può scegliere se adottare la tecnologia A, la B o entrambe. Nel caso in cui lui e un suo vicino scelgano entrambi la strategia AB il payoff per entrambi sarà del massimo tra a e b meno un costo aggiuntivo c.
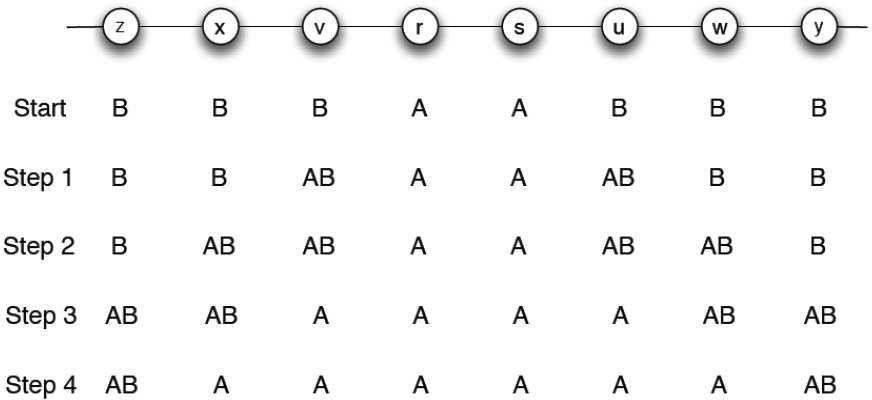
Prendiamo per esempio c=1, a=2 e b=3. Partendo dalla situazione START sottoindicata abbiamo i seguenti sviluppi:
e quindi la strategia A si diffonderà sempre di più all’aumentare delle iterazioni. È intuitivo aspettarsi che se a è molto maggiore di b la tecnologia A si diffonderà rapidamente, ma come influisce c? La sua influenza, in relazione a quella di a è sintetizzata nelle immagini sottostanti.
I giochi ripetuti
Oltre ai giochi sequenziali menzioniamo brevemente che all’interno dei giochi dinamici esistono anche i giochi ripetuti che si ripetono più volte con gli stessi giocatori e le stesse azioni/strategie tra cui scegliere. Possiamo per esempio riprendere il dilemma del prigioniero descritto nel precedente articolo sulla teoria dei giochi (https://orbyta.it/teoria-dei-giochi/). In uno scenario “one-shot” il dilemma si risolve con un equilibrio di Nash non pareto-ottimale, infatti i due prigionieri si tradiscono a vicenda, subendo entrambi la condanna. Se invece il gioco venisse ripetuto, vengono prese in considerazione la reputazione dei giocatori, basata sulle decisioni da loro prese in passato, e la punizione/reazione dell’avversario nel turno successivo. L’esito finale in questo caso dipende dal numero di turni nel gioco. Se il numero di turni è predefinito, si può dimostrare che il gioco si conclude esattamente come nel scenario “one-shot”, in un equilibrio non-pareto efficiente, perché gli giocatori sono spinti comunque a tradire. Se invece il numero di turni è sconosciuto, i giocatori sono incentivati a cooperare temendo la reazione dell’avversario nel turno successivo arrivando così ad una conclusione di equilibrio pareto-ottimale.
In questo articolo abbiamo studiato i giochi dinamici e come si risolvono tramite la metodologia di backward induction. Abbiamo visto inoltre i concetti di centralità (betweeness centrality) e del coefficiente medio di clustering per i nodi all’interno di una rete. In particolare abbiamo visto tramite alcuni esempi che per la diffusione di una strategia è importante che la rete non sia fortemente connessa. Infine abbiamo introdotto i giochi ripetuti e come si può arrivare ad una risoluzione pareto-ottimale al loro interno.
Bibliografia e Sitografia
[1] R. Dawkins, Il gene egoista, I edizione collana Oscar saggi, Arnoldo Mondadori Editore, 1995.
[2] D. Easley e J. Kleinberg, Networks, Crowds, and Markets: Reasoning about a Highly Con- nected World, Cambridge University Press, 2010.
[3] R. Gibbons, Teoria dei giochi, Bologna, Il Mulino, 2005.
[4] E. Martìn Novo e A. Mendez Alonso, Aplicaciones de la teoría de grafos a algunos juegos de estrategia, numero 64 di Suma, Universidad Politécnica de Madrid, 2004.
[5] S. Rizzello e A. Spada, Economia cognitiva e interdisciplinarità, Giappichelli Editore, 2011.
[6] G. Romp,Game Theory: Introduction and Applications, Mishawaka, Oxford University Press, 1997
[7] T. C. Schelling, The Strategy of Conflict, Cambridge, Massachusetts: Harvard, University Press, 1960.
[8] P. Serafini, Teoria dei Grafi e dei Giochi, a.a. 2014-15 (revisione: 28 novembre 2014).
[9] I. S. Stievano e M. Biey, Cascading behavior in networks, DET, Politecnico di Torino, 2015.
[10] I. S. Stievano e M. Biey, Interactions within a network, DET, Politecnico di Torino, 2015.
[11] I. S. Stievano, M. Biey e F. Corinto, Retie sistemicomplessi… , DET, Politecnico di Torino, 2015.
[12] A. Ziggioto e A. Piana, Modello di Lotka-Volterra, reperibile all’indirizzo http://www.itismajo.it/matematica/Lezioni/Vecchi%20Documenti%20a.s.%202011-12/Modello
%20di%20Lotka-Volterra.pdf, consultato il 15/05/2015.
[13] http://it.wikipedia.org/wiki/Equilibrio_di_Nash consultato il 12/05/2015.
[14] http://www.oilproject.org/lezione/teoria-dei-giochi-equilibrio-di-nash-e-altri-concetti-introduttivi-2471.html consultato il 13/05/2015.
[15] http://web.econ.unito.it/vannoni/docs/thgiochi.pdf consultato il 14/05/2015.
[16] https://www.youtube.com/watch?v=jILgxeNBK_8 consultato il 19/01/2021.
Articolo a cura di Carla Melia (Head Data Scientist), Augusto Cadini (IT Business Analyst) e Angeni Uminga (Software Developer), Orbyta Tech, 10.07.2021
Introduci la tua esperienza professionale fino all’ingresso in ORBYTA.
Già da bambina avevo capito che la creatività era la mia strada, quando a 7 anni alcuni problemi di salute mi hanno costretta a trascorrere molte ore di degenza in ospedale.
Per non annoiarmi ho cominciato a disegnare le pubblicità prese dalle riviste di moda che venivano lasciate sul mio comodino. Così la mia mente ha cominciato a strutturarsi sempre di più nel comprendere la pubblicità e da lì è nato il mio stile. Una volta dimessa ho abbandonato i disegni, che poi successivamente ho scoperto essere esposti nelle sale d’aspetto.
Ho poi studiato grafica e mi sono diplomata in comunicazione pubblicitaria. Dopo le primissime esperienze lavorative, ho deciso di specializzarmi e intraprendere la mia carriera nel mondo della comunicazione: il mio grande trampolino di lancio è stato lavorare per l’azienda cosmetica Kelemata, dove mi sono affermata da subito come creativo di spicco lavorando con due direttrici francesi. Non capivo nulla di francese, ma ho capito, invece, che la creatività è una lingua universale.
Poi il passo nelle grandi agenzie dove ho avuto l’onore di lavorare per importanti clienti internazionali, Johnson & Johnson, L’Oreal, Conserve Italia, Amadori, Condorelli, Banca Zurich, sono alcuni dei grandi marchi per cui ho lavorato in 10 anni di carriera.
In tutte queste esperienze ho avuto la fortuna di apprendere da grandi Art Director, facendo una dura gavetta dal punto di vista tecnico e gestionale.
All’arrivo dei miei bellissimi figli decido di cambiare: mi metto in proprio e fondo la mia realtà. Ad oggi questa decisione mi ha portata ad essere Direttore Creativo di CREO, agenzia del Gruppo ORBYTA.
2. Di cosa ti occupi e che valore porti all’azienda?
In ORBYTA il mio compito è quello di portare un’eccellenza, fatta di anni di esperienza, competenza e di imbattibile senso estetico ed emotivo.
Nella parte più pratica gestisco i clienti nella comunicazione, dal brand al web design, dal packaging al social media management. La mia è una figura di riferimento, che deve capire le necessità del cliente e aiutarlo a guardare oltre, il tutto coordinando le varie competenze e risorse che sono di supporto nello sviluppo dei progetti.
3. Perché ti piace lavorare in ORBYTA?
Mi piace lavorare in ORBYTA perché ci accomuna l’entusiasmo, il fare parte di un gruppo forte e dinamico, inoltre è un’azienda che si pone obiettivi vincenti e uno spazio dove poter “fare”.
Introduzione
Un sistema esperto (o basato sulla conoscenza) è un software in grado di riprodurre in modo artificiale le prestazioni di una o più persone “esperte” in un determinato campo di attività e trova la sua applicazione nella branca dell’intelligenza artificiale.
Una delle particolarità di un sistema esperto è quella di essere in grado di mettere in atto autonomamente delle procedure di inferenza, un processo induttivo o deduttivo che permette di giungere a una conclusione a seguito dell’analisi di una serie di fatti o circostanze adeguate alla risoluzione di problemi particolarmente complessi.
Un tipico sistema esperto ha due funzioni principali: quella di trarre delle conclusioni e quindi compiere o suggerire delle scelte (COSA) e quella di spiegare in che modo, con quale ragionamento è pervenuto a quelle conclusioni (CONTROLLO).
Un sistema esperto è composto da una base di conoscenza, una memoria di lavoro, un motore inferenziale e un’interfaccia utente.
Nella base di conoscenza sono contenute le regole deduttive e i dettami procedurali di cui il sistema si serve nel suo operato. Il motore inferenziale è necessario per indirizzare il programma a interpretare, classificare e applicare la base di conoscenza e le relative regole per ogni singolo aspetto o scenario dello specifico campo disciplinare. La memoria di lavoro, o memoria a breve termine, contiene i dati e le conclusioni raggiunte dal sistema. Infine, l’interfaccia utente permette l’interazione fra il soggetto umano e il programma che deve dare risposta ai suoi problemi.
Queste informazioni sono piuttosto generiche ed estremamente flessibili. Il programma non è un insieme di istruzioni immutabili che rappresentano la soluzione del problema, ma un ambiente in cui rappresentare, utilizzare e modificare una base di conoscenza.
Caratteristico dei sistemi esperti è imitare l’esperto umano non solo nelle prestazioni ma anche nel modo di eseguire inferenze. La maggior parte di essi fa uso del cosiddetto ”ragionamento di superficie” o fuzzy logic, basato sull’impiego di un gran numero di strategie o regole empiriche, dette euristiche, che legano direttamente i fatti noti con quelli da inferire, senza una vera comprensione del tipo di legame esistente.
Subentra lo stratagemma dell’euristica qualora le componenti che presiedono alle procedure di inferenza, non riescono ad ottenere il rigore connaturato ad un algoritmo, in quanto nelle situazioni altamente complicate sarebbe troppo dispendioso analizzare ogni possibilità.
È nella natura stessa delle euristiche il fatto che non si possa dimostrare che siano corrette in quanto ciò sacrificherebbe risultati altamente probabili, ma comunque fallibili, non dando sempre nella pratica il risultato migliore; tuttavia consentono agli esperti di prendere decisioni quando non sono disponibili criteri più ”forti”.
Come già detto in precedenza, per elaborare le proprie conclusioni, i sistemi esperti possono fare affidamento su una base di conoscenza, la conoscenza viene immagazzinata nella memoria a lungo termine del sistema ed è organizzata e rappresentata sotto forma di regole, ad esempio definite come strutture “if-then” (“se-allora”), che comprendono una premessa o condizione (if) e una conclusione o azione (then), e descrivono la risoluzione di un dato problema.
Un sistema esperto basato su alberi, invece, parte da un insieme di dati ed alcune deduzioni per poi creare un albero di classificazione attraverso il quale i nuovi dati verranno analizzati portando alla deduzione rappresentata dal nodo di arrivo.
Ora ci focalizzeremo sui sistemi esperti basati sulle regole. E’ quindi doverosa un’introduzione alla logica matematica.
Sistemi esperti e logica matematica
La logica ha lo scopo di formalizzare i meccanismi di ragionamento. Faremo un breve accenno sulle proposizioni, cioè espressioni che rappresentano affermazioni che nell’ambito di questo articolo potranno essere solo o VERE o FALSE. Per quanto ciò possa sembrare scontato, esistono in verità settori in cui si può attribuire a ciascuna proposizione un grado di verità diverso da 0 e 1 e compreso tra di loro (ovvero che usano logica sfumata).
Ad ogni proposizione elementare viene associata un variabile proposizionale. Per esempio:
P1: Se fa caldo ed è umido, allora pioverà.
P2: Se è umido ed è estate, allora fa caldo.
P3: Adesso è umido.
P4: Adesso è estate.
Se chiamo A = FA CALDO, B = È UMIDO, C = È ESTATE, D = PIOVERÀ.
La rappresentazione in formule diventa
F1: A ∧B →D,
F2: B ∧C →A
F3: B
F4: C
Si può voler dimostrare che da questi 4 fatti segue logicamente P5: Pioverà, ovvero F5: D. Di ciò si può occupare un sistema esperto.
Come vediamo una formula è composta da formule atomiche (o atomi) (ovvero A, B, …) e connettivi logici.
I connettivi logici più comunemente usati sono:
¬(NOT: negazione)
∨(OR: disgiunzione)
∧(AND: congiunzione)
→(IMPLIES o IF…THEN…: implicazione)
↔(IF AND ONLY IF: bi-implicazione)
Una formula è ben formata (FBF) se e solo se essa è ottenibile applicando le seguenti regole:
un atomo è una FBF
se F è una FBF, allora (¬F) è una FBF
se F e G sono FBF, allora (F∨G), (F∧G), (F→G), (F↔G) sono FBF
Semplificando in questa trattazione una FBF è una formula a cui è possibile attribuire un valore di verità, vero o falso.
Le regole viste esprimono la SINTASSI (vincoli strutturali) delle formule del calcolo proposizionale. Stabilendo un ordinamento tra i connettivi è possibile eliminare alcune parentesi. L’ordine che verrà adottato è il seguente:
¬
∧, ∨
→, ↔
Così, La formula ((((A∨B)∧C)→D)↔(((¬D)→A)∨E) può essere riscritta (eliminando le parentesi esterne) come ((A∨B)∧C→D)↔(¬D→A)∨E.
La SEMANTICA della logica proposizionale richiede l’introduzione dei valori di verità. L’insieme dei valori di verità (che indicheremo con B) include VERO e FALSO, rappresentati da B= {T, F}.
Un’interpretazione I consiste in un mapping tra l’insieme delle formule e B (specificando cioè, per ogni formula, se essa è vera o falsa).
Come si può ricavare il valore di verità di una formula?
Per esempio se ci chiediamo se (P ∧Q) ∨R →(P ↔R) ∧ Q possiamo porre
α= (P ∧Q) ∨R
β= (P ↔R) ∧Q
e quindi chiederci se α →β consultando la seguente classica tavola di verità (intuitivamente, ogni riga di una tabella di verità corrisponde ad una diversa possibile situazione (interpretazione)).
Alcune formule sono vere in tutte le interpretazioni. Esse sono dette formule valide o tautologie. Altre formule sono false in tutte le interpretazioni. Esse sono dette formule inconsistenti o contraddizioni.
Poiché ogni formula è finita e quindi contiene un numero finito di formule atomiche, è sempre possibile determinare se essa è valida, inconsistente o né l’una né l’altra. La logica proposizionale è quindi decidibile.
Alcune formule valide sono controintuitive (e sono chiamate paradossi). In esse compare il connettivo →.
Un esempio è ¬P→(P →Q) che è sempre vera.
Due formule F e G sono equivalenti (scritto F ⇔G) se e solo se esse hanno lo stesso valore di verità in tutte le interpretazioni.
Il modus ponens (MP) è una semplice e valida regola d’inferenza, che afferma in parole: “Se p implica q è una proposizione vera, e anche la premessa p è vera, allora la conseguenza q è vera”, ovvero (p ∧(p →q)) →q.
Si ribadisce che l’implicazione non ha nulla a che vedere con la causalità. La logica proposizione infatti si occupa solo di “combinazioni” e non di significati di “causa-effetto”.
Non ci addentreremo nella logica dei predicati in quanto, seppur sia uno strumento più potente e flessibile, è anche molto più complicato e non adatto alle finalità di questo articolo.
Per poter trattare in modo meccanico, le fbf devono essere poste in forma a clausole. I passi da seguire sono
Eliminazione delle implicazioni
Riduzione del campo dei segni di negazione
Standardizzazione delle variabili
Eliminazione dei quantificatori esistenziali: ogni variabile esistenzialmente quantificata è rimpiazzata con una funzione di Skolem
Conversione in forma prenessa
Trasformazione della matrice in forma normale congiuntiva
Eliminazione dei quantificatori universali
Eliminazione dei segni di congiunzione
ESEMPIO
Si applicano in successione alcune operazioni, illustrate mediante il seguente esempio: ( ∀x){P(x) →{( ∀y){P(y) →P(f(x,y))} ∧ ¬ ( ∀y){Q(x,y) →P(y)}}}
1) Eliminazione delle implicazioni, ovvero A → B è sostituito da:
(∀x∀y) è detto prefisso e {¬P(x)∨{{¬P(y)∨P(f(x,y))}∧{Q(x,g(x))∧¬P(g(x))}}} è detta matrice Intelligenza
6) Trasformazione della matrice in forma normale congiuntiva: la matrice viene scritta come congiunzione di un numero finito di disgiunzioni di predicati e/o negazioni di predicati (forma normale congiuntiva). (In parole povere, AND di OR, ovvero prodotti di somme, ovvero, maxterm).
7) Eliminazione dei quantificatori universali: resta la sola matrice in cui, essendo le variabili legate, sono tutte universalmente quantificate.
8) Eliminazione dei segni di congiunzione. I segni di congiunzione (cioè ∧; esempio: A ∧ B) sono eliminati dando luogo a due fbf (nell’esempio, A e B). Applicando ripetutamente questo rimpiazzo si ottiene una lista finita di fbf, ognuna delle quali è una disgiunzione ( ∨) di formule atomiche e/o di negazioni di formule atomiche.
Esempio trasformazione in clausola “Tutti i romani che conoscono Marco o odiano Cesare o pensano che tutti quelli che odiano qualcuno sono matti”
Una clausola di Horn è una disgiunzione di letterali in cui al massimo uno dei letterali è positivo. Esempio: ¬L∨¬B e ¬L∨¬B∨C sono clausole di Horn, ¬L∨B∨C non lo è. Sono importanti perché si possono scrivere come implicazioni la cui premessa è una congiunzione di letterali positivi e la cui conclusione è un singolo letterale positivo. Ad esempio, ¬L∨¬B∨C è equivalente a (L∧B)→C.
Per risolvere i problemi di logica esistono molti modi, useremo il modus ponens come esempio.
La risoluzione è un processo iterativo che, ad ogni passo, confronta (risolve) due clausole genitori e permette di inferire una nuova clausola. Per la risoluzione si considerano due clausole che contengono la stessa formula atomica, una volta affermata e una volta negata. La risolvente è ottenuta combinando tutte le formule atomiche delle clausole genitori eccetto quelle che cancella. Se si produce la clausola vuota, si ha una contraddizione. Il tentativo sarà quello di trovare una contraddizione, se esiste. Se non esiste, la procedura può non avere mai termine.
Risoluzione nella logica proposizionale usando il MP: il procedimento è il seguente:
Procedimento:
Trasformare tutte le proposizioni in F in forma a clausole.
Negare S e trasformare il risultato in forma a clausole. Aggiungerlo all’insieme di clausole ottenute al passo 1).
Ripetere fino a quando viene trovata una contraddizione o non si può più andare avanti i passi seguenti:
Selezionare due clausole. Chiamarle clausole genitori.
Risolverle insieme. La clausola risultante, chiamata la risolvente, sarà la disgiunzione di tutte le formule atomiche di entrambe le clausole genitori con la seguente eccezione: se vi sono coppie di formule atomiche L e ¬L, tali che una delle clausole genitori contenga L e l’altra contenga ¬L, allora eliminare sia L che ¬L dalla risolvente.
Se la risolvente è la clausola vuota, allora è stata trovata una contraddizione. In caso contrario, aggiungerla all’insieme di clausole a disposizione della procedura.
ESEMPIO
siano dati i seguenti assiomi:
Assiomi:
p
(p ∧ q) → r
(s ∨ t) → q
t
Convertiti in forma a clausole:
p
¬p ∨ ¬q ∨ r
¬s ∨ q
¬t ∨ q
t
Si voglia dimostrare r.
Dopo aver trasformato gli assiomi in forma a clausola, si introduce nella lista ¬r (già in forma a clausola).
Poi si selezionano le clausole a 2 a 2 e si risolvono (conviene scegliere clausole che contengono la stessa forma atomica una volta affermata e una volta negata).
Si ottiene, ad esempio:
Nota: la proposizione 2 è vera se sono vere ¬p, ¬q, r
Al primo passo si assume che ¬r sia vera, insieme alla preposizione 2.
Ciò può accadere solo se è vera
¬p oppure ¬q.
È quello che afferma la risolvente!
Conclusione:
per provare r, si prova che ¬r crea contraddizione. Si inserisce quindi ¬r nella lista di forme a clausola e si cerca, mediante risoluzione, se esiste questa contraddizione (metodo della refutazione).
Ci siamo concentrati per semplicità su un esempio di meccanismo performato da un SE usando la logica classica ma i tipi di ragionamento sono tanti, per esempio, potremmo utilizzare:
La logica non monotona: permette di cancellare e aggiungere enunciati alla base dati. In questa logica la credenza in un enunciato si può basare sulla mancata credenza in qualche altro enunciato (ragionamento by default).
Il Ragionamento probabilistico: rende possibile rappresentare inferenze probabili ma incerte.
La Logica sfumata (fuzzy logic): permette di rappresentare proprietà di oggetti continue (non binarie) o sfumate.
Il Concetto di spazi di credenza: permette di rappresentare modelli di insiemi di credenze inserite l’uno nell’altro.
Concludiamo l’articolo dando qualche indicazione sul problema della rappresentazione della conoscenza, fondamentale in questo ambito.
Rappresentazione delle conoscenza
La rappresentazione della conoscenza è una branca dell’intelligenza artificiale che studia il modo in cui avviene il ragionamento umano, e si preoccupa di definire dei simbolismi o dei linguaggi che permettano di formalizzare la conoscenza al fine di renderla comprensibile alle macchine, per potervi fare dei ragionamenti automatici (inferendo le informazioni presenti) ed estrarre così nuova conoscenza.
Attraverso il linguaggio scelto si andranno ad effettuare una serie di asserzioni sul mondo, che andranno insieme a costituire una base di conoscenza (KB, Knowledge Base). È inoltre importante che il linguaggio scelto per fare le asserzioni sia anche in grado di operare sulla KB per estrarre nuova conoscenza e per aggiungerne di nuova.
I metodi di rappresentazione della conoscenza schematicamente si suddividono in impliciti ed espliciti. In generale occorre rappresentare: collezione di oggetti, collezione di attributi (proprietà degli oggetti) e insiemi di relazioni (tra gli oggetti). La scelta della rappresentazione influenza lo sforzo di ricerca, in quanto può permettere di riconoscere concetti semplificanti (simmetrie, analogie, ecc.) e formare macro operatori (può essere utile utilizzare variabili nella descrizione degli stati).
Un problema connesso, detto problema del contorno o frame problem, è quello di rappresentare un mondo in cui ci sono cose che cambiano e cose che non cambiano. Per ovviare il problema si può, per esempio, tenere traccia solo dei cambiamenti (lo stato di partenza è descritto in modo completo) o modificare lo stato iniziale con operatori “invertibili” in modo che si possa tornare indietro “annullando” i passi effettuati.
Caratteristiche di un buon sistema di rappresentazione:
Adeguatezza rappresentativa: poter rappresentare tutti i tipi di conoscenza relativi a un dominio.
Adeguatezza inferenziale: poter manipolare le strutture rappresentative in modo da inferire nuova conoscenza
Efficienza inferenziale: poter incorporare informazioni in più da usare come guida verso gli obiettivi nei meccanismi di inferenza (focalizzazione dell’attenzione/euristica)
Efficienza nell’acquisizione: capacità di acquisire facilmente nuova conoscenza.
Occorre che il sistema possieda e sappia manipolare una grande quantità di conoscenza del mondo (semantica e pragmatica) e conosca la sintassi e possieda il vocabolario del linguaggio. E’ desiderabile ma complicato tenere separati i due livelli (ma alcune interpretazioni sintattiche non sono possibili se non si conosce il contesto).
Classificazione delle tecniche:
metodi dichiarativi: la conoscenza viene rappresentata come collezione statica di fatti, affiancata da un piccolo insieme di procedure generali per la manipolazione (esempio: logica dei predicati). Vantaggi:
Ogni fatto va immagazzinato solo una volta, indipendentemente dal numero di modi in cui può essere usato.
È facile aggiungere nuovi fatti al sistema, senza cambiare né gli altri fatti né le procedure.
metodi procedurali: la conoscenza viene rappresentata come procedure per il suo uso. Vantaggi:
È facile rappresentare la conoscenza su come fare le cose
È facile rappresentare la conoscenza che non si inserisce facilmente in molti schemi dichiarativi semplici, come ad esempio il ragionamento per default e quello probabilistico
È facile rappresentare la conoscenza euristica su come fare le cose in modo efficiente
La maggior parte dei sistemi funzionanti usa una combinazione dei due metodi.
La descrizione delle strutture di conoscenza avviene mediante schemi, ovvero un’organizzazione attiva di relazioni passate, o di esperienze passate, che devono supporre siano operanti in ogni risposta organica adattiva. Senza entrare nel dettaglio elenchiamo di seguito alcuni tipi di schemi.
Frame (quadri), spesso usati per descrivere una collezione di attributi che un determinato oggetto, per esempio, una sedia, in genere possiede.
Script (copioni), usati per descrivere sequenze di eventi comuni, come ad esempio ciò che succede quando si va al ristorante.
Stereotipi, usati per descrivere insiemi di caratteristiche che spesso nelle persone sono presenti contemporaneamente.
Modelli a regole, usati per descrivere caratteristiche comuni condivise all’interno di un insieme di regole in un sistema di produzioni.
In questo articolo abbiamo visto alcuni concetti base dei sistemi esperti, estremamente potenti anche se poco conosciuti nell’ambito dell’IA. Abbiamo anche introdotto in maniera intuitiva concetti propri della logica matematica e del problema della rappresentazione della conoscenza. Per approfondire l’argomento consigliamo i seguenti testi:
Stuart J. Russell, Peter Norvig, “Intelligenza Artificiale. Un approccio Moderno”, Pearson Education Italia, Milano.
E. Rich, “Intelligenza artificiale”, McGraw Hill, Milano.
N.J. Nilsson, “Metodi per la risoluzione dei problemi nell’intelligenza artificiale”, Angeli, Milano.
Nils J. Nilsson, “Intelligenza Artificiale”, Apogeo,Milano.
I. Bratko, “Programmare in prolog per l’intelligenza artificiale”, Masson Addison Wesley, Milano.
FONTI:
Slide del corso GESTIONE DELLA CONOSCENZA E INTELLIGENZA ARTIFICIALE, Politecnico di Torino, Elio Piccolo, 2017.
https://it.wikipedia.org/wiki/Sistema_esperto, consultato il 20.05.2021
Roger Schank e Robert Abelson, Scripts, Plans, Goals, and Understanding: An Inquiry Into Human Knowledge Structures, Lawrence Erlbaum Associates, Inc., 1977.
https://www.treccani.it/enciclopedia/sistemi-esperti_%28Enciclopedia-della-Scienza-e-della-Tecnica%29/#:~:text=Insiemi%20di%20programmi%20software%20in,’ambito%20dell’intelligenza%20artificiale, consultato il 09.07.2021.
Articolo a cura di Carla Melia, Lucia Campomaggiore e Ludovico Dellavecchia, 01.08.2021
Su questo sito utilizziamo cookie tecnici necessari alla navigazione e funzionali all’erogazione del servizio. Utilizziamo i cookie anche per fornirti un’esperienza di navigazione sempre migliore, per facilitare le interazioni con le nostre funzionalità social.
Puoi esprimere il tuo consenso cliccando su ACCETTA TUTTI.
I cookie necessari sono assolutamente essenziali per il corretto funzionamento del sito web. Questi cookie garantiscono le funzionalità di base e le caratteristiche di sicurezza del sito web, in modo anonimo.
Cookie
Durata
Descrizione
__hssrc
session
This cookie is set by Hubspot whenever it changes the session cookie. The __hssrc cookie set to 1 indicates that the user has restarted the browser, and if the cookie does not exist, it is assumed to be a new session.
cookielawinfo-checkbox-analytics
11 months
Questo cookie è impostato dal plug-in GDPR Cookie Consent. Il cookie viene utilizzato per memorizzare il consenso dell'utente per i cookie nella categoria "Analytics".
cookielawinfo-checkbox-functional
11 months
Il cookie è impostato dal consenso cookie GDPR per registrare il consenso dell'utente per i cookie nella categoria "Funzionali".
cookielawinfo-checkbox-necessary
11 months
Questo cookie è impostato dal plug-in GDPR Cookie Consent. I cookie vengono utilizzati per memorizzare il consenso dell'utente per i cookie nella categoria "Necessari".
cookielawinfo-checkbox-others
11 months
Questo cookie è impostato dal plug-in GDPR Cookie Consent. Il cookie viene utilizzato per memorizzare il consenso dell'utente per i cookie nella categoria "Altri.
cookielawinfo-checkbox-performance
11 months
Questo cookie è impostato dal plug-in GDPR Cookie Consent. Il cookie viene utilizzato per memorizzare il consenso dell'utente per i cookie nella categoria "Prestazioni".
JSESSIONID
session
Utilizzato da siti scritti in JSP. Cookie di sessione della piattaforma per scopi generici che vengono utilizzati per mantenere lo stato degli utenti attraverso le richieste di pagina.
viewed_cookie_policy
11 months
Il cookie è impostato dal plug-in GDPR Cookie Consent e viene utilizzato per memorizzare se l'utente ha acconsentito o meno all'uso dei cookie. Non memorizza alcun dato personale.
I cookie funzionali aiutano a eseguire determinate funzionalità come condividere il contenuto del sito Web su piattaforme di social media, raccogliere feedback e altre funzionalità di terze parti.
Cookie
Durata
Descrizione
__cf_bm
30 minutes
Questo cookie, impostato da Cloudflare, viene utilizzato per supportare la gestione dei bot di Cloudflare.
__hssc
30 minutes
HubSpot imposta questo cookie per tenere traccia delle sessioni e per determinare se HubSpot deve incrementare il numero di sessione e i timestamp nel cookie __hstc.
bcookie
2 years
LinkedIn imposta questo cookie dai pulsanti di condivisione di LinkedIn e aggiunge tag per riconoscere l'ID del browser.
lang
session
Questo cookie viene utilizzato per memorizzare le preferenze di lingua di un utente per fornire contenuti in quella lingua memorizzata la prossima volta che l'utente visita il sito web.
lidc
1 day
LinkedIn imposta il cookie lidc per facilitare la selezione del data center.
I cookie per le prestazioni vengono utilizzati per comprendere e analizzare gli indici di prestazioni chiave del sito Web che aiutano a fornire una migliore esperienza utente per i visitatori.
I cookie analitici vengono utilizzati per capire come i visitatori interagiscono con il sito web. Questi cookie aiutano a fornire informazioni sulle metriche del numero di visitatori, della frequenza di rimbalzo, della sorgente del traffico, ecc.
Cookie
Durata
Descrizione
__hstc
1 year 24 days
This is the main cookie set by Hubspot, for tracking visitors. It contains the domain, initial timestamp (first visit), last timestamp (last visit), current timestamp (this visit), and session number (increments for each subsequent session).
_ga
2 years
Il cookie _ga, installato da Google Analytics, calcola i dati di visitatori, sessioni e campagne e tiene anche traccia dell'utilizzo del sito per il report di analisi del sito. Il cookie memorizza le informazioni in modo anonimo e assegna un numero generato casualmente per riconoscere i visitatori unici.
_gat_gtag_UA_162571803_1
1 minute
This cookie is set by Google and is used to distinguish users.
_gid
1 day
Installato da Google Analytics, il cookie _gid memorizza informazioni su come i visitatori utilizzano un sito web, creando anche un report analitico delle prestazioni del sito web. Alcuni dei dati raccolti includono il numero di visitatori, la loro fonte e le pagine che visitano in modo anonimo.
CONSENT
16 years 3 months 10 days 7 hours 5 minutes
Questi cookie vengono impostati tramite video di YouTube incorporati. Registrano dati statistici anonimi su ad esempio quante volte viene visualizzato il video e quali impostazioni vengono utilizzate per la riproduzione. Nessun dato sensibile viene raccolto a meno che non accedi al tuo account google, in tal caso le tue scelte sono legate al tuo account, ad esempio se fai clic su "mi piace" su un video.
hubspotutk
1 year 24 days
Questo cookie viene utilizzato da HubSpot per tenere traccia dei visitatori del sito web. Questo cookie viene passato a Hubspot all'invio del modulo e utilizzato durante la deduplicazione dei contatti.
I cookie pubblicitari vengono utilizzati per fornire ai visitatori annunci e campagne di marketing pertinenti. Questi cookie tengono traccia dei visitatori sui siti Web e raccolgono informazioni per fornire annunci personalizzati.
Cookie
Durata
Descrizione
bscookie
2 years
Questo cookie è un cookie ID del browser impostato dai pulsanti di condivisione collegati e dai tag degli annunci.
IDE
1 year 24 days
I cookie di Google DoubleClick IDE vengono utilizzati per memorizzare informazioni su come l'utente utilizza il sito Web per presentargli annunci pertinenti e in base al profilo dell'utente.
test_cookie
15 minutes
Il test_cookie è impostato da doubleclick.net e viene utilizzato per determinare se il browser dell'utente supporta i cookie.
VISITOR_INFO1_LIVE
5 months 27 days
Un cookie impostato da YouTube per misurare la larghezza di banda che determina se l'utente ottiene la nuova o la vecchia interfaccia del lettore.
YSC
session
Il cookie YSC è impostato da Youtube e viene utilizzato per tenere traccia delle visualizzazioni dei video incorporati nelle pagine di Youtube.
yt-remote-connected-devices
never
YouTube imposta questo cookie per memorizzare le preferenze video dell'utente utilizzando il video YouTube incorporato.
yt-remote-device-id
never
YouTube imposta questo cookie per memorizzare le preferenze video dell'utente utilizzando il video YouTube incorporato.
yt.innertube::nextId
never
Questi cookie vengono impostati tramite video di YouTube incorporati.
yt.innertube::requests
never
These cookies are set via embedded youtube-videos.