Introduzione
Molti di voi probabilmente conosceranno già il concetto di database a grafo, un’alternativa al classico modello di database relazionale che risulta particolarmente efficiente quando si ha a che fare con delle relazioni complesse, mutevoli e gerarchicamente strutturate tra le entità, come potrebbero essere i dati tipici di un social media. L’aspetto forse un po’ meno noto è che anche Management Studio, dalla sua versione del 2017, supporta la creazione di un DB a grafo completamente integrato nel SQL Engine, nonostante da tempo già ci fossero delle soluzioni che in qualche modo cercavano mimarne il comportamento, come le CTE ricorsive o il tipo HierarchyId.
In un DB relazionale abbiamo righe, tabelle, chiavi esterne e relazioni, mentre le entità tipiche del DB a grafo sono note come nodi (nodes) e archi (edges). Mentre i nodi non sono dissimili dal concetto di tabella come la potremmo incontrare in un normale DB, l’entità più interessante sono proprio gli archi, delle specie di relazioni “arricchite” che definiscono il rapporto tra i nodi e che sono contraddistinte a loro volta da attributi e proprietà. Per usare una definizione intuitiva, anche se non troppo precisa, possiamo considerare i nodi come “oggetti” (prodotti, luoghi, clienti etc.), e gli archi come “azioni” (vive a, comprato a, lavora per).
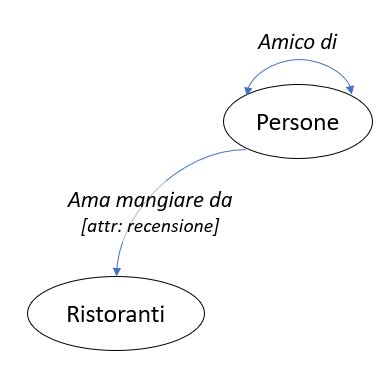
Ecco un esempio di DB a grafo molto semplice ma che rende già l’idea
La peculiarità del DB a grafo è proprio la possibilità di associare degli attributi direttamente alla relazione (cioè all’arco), che in questo modo supera il suo semplice compito di mettere in rapporto una tabella con un’altra, diventando dato essa stessa. Sfruttando questa struttura possiamo scrivere delle query dall’aspetto molto sintetico, che utilizzando un DB relazionale sarebbero estremamente più complesse e di difficile lettura. Grazie alle peculiarità del DB a grafo potremo tradurre in poche righe di codice interrogazioni come questa: “Trova tutte le persone nate a Torino nel 1990 che hanno valutato 5 stelle il McDonald di piazza dell’VIII Agosto di Bologna e hanno un amico, tifoso dei Los Angeles Lakers, che vive a Cagliari”.
Un esempio pratico
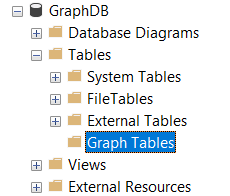
Non c’è cosa migliore per entrare nel vivo della questione che vedere un esempio pratico e cominciare a fare qualche prova. Se creiamo su SSMS un nuovo database ed espandiamo il menu delle tabelle, possiamo notare la presenza dell’entità Graph Tables, sotto alla quale troveremo tutte le tabelle create nel perimetro del nostro DB a grafo (il che comprende sia i nodi sia gli archi).
Per questo esempio prenderemo in considerazione una porzione ridotta del diagramma mostrato all’inizio dell’articolo, ovvero quella che coinvolge i soli nodi Persone e Ristoranti (con relativi archi); questo esempio, per quanto semplice, ci permetterà già di indagare diversi aspetti interessanti di questa funzionalità di SSMS.
Creiamo e popoliamo le entità nodi
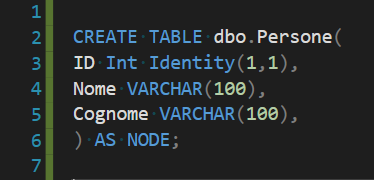
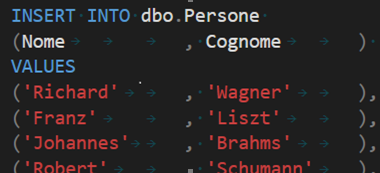
Come prima entità creiamo una tabella nodo, in tutto e per tutto simile alla creazione di una classica tabella, se non fosse per l’aggiunta finale della dicitura “AS NODE”.
L’inserimento dei dati in questa tabella è invece del tutto indistinguibile dalla classica insert che potremmo eseguire per popolare una tabella normale.
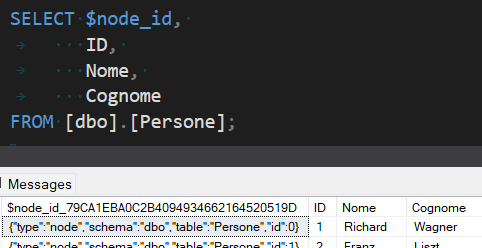
Se eseguiamo una semplice SELECT * della tabella appena creata, possiamo già notare una prima differenza rispetto ad una tabella classica: le tabelle di tipo nodo vengono difatti equipaggiate con una colonna aggiuntiva generata automaticamente, chiamata $node_id (seguito da una stringa esadecimale).
Si tratta di una pseudo colonna utilizzabile nelle query, ed è possibile interrogarla anche omettendo la parte esadecimale, come possiamo notare nell’esempio seguente.
Il contenuto di questa particolare colonna è un JSON (anche questo generato automaticamente) che ci servirà per creare gli archi che connetteranno due tabelle nodo tra loro.
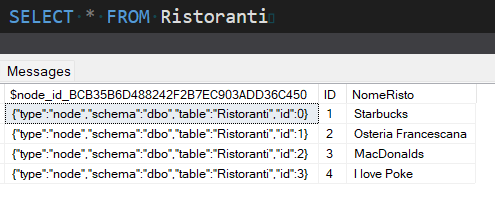
Creiamo e popoliamo allo stesso modo la tabella nodo “Ristoranti”, di cui per brevità vi mostro solo l’aspetto finale
Creiamo e popoliamo le entità archi
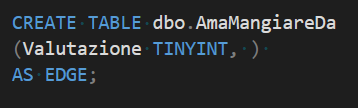
La sintassi per la creazione di un arco è identica alla creazione delle tabelle nodo, con la differenza che la specifica “AS NODE” sarà sostituita da “AS EDGE”
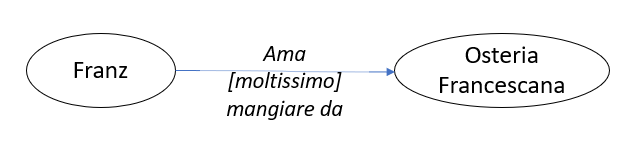
Questa relazione, che mette in rapporto le persone con i ristoranti, annovera tra i suoi attributi la valutazione che ciascuna persona ha espresso nei confronti di quel ristorante. Possiamo quindi visualizzare questa relazione tra due dati di esempio come
dove le ellissi sono i dati ospitati nei nodi Persone e Ristoranti, il connettore è la relazione rappresentata dall’arco AmaMangiareDa, e la parola tra parentesi quadre è l’attributo “Valutazione” dell’arco stesso, come lo abbiamo definito nel passaggio precedente.
Finora non abbiamo ancora collegato tra loro in nessun modo le persone e i ristoranti, quindi il prossimo passaggio consisterà nell’aggiungere dati alla tabella arco in questo modo:
Così facendo ho recuperato un record dalla tabella delle persone ovvero “Franz Liszt”, un record dalla tabella dei ristoranti, ovvero “Osteria Francescana”, e ho aggiunto la valutazione di cinque stelle che Franz Liszt ha assegnato a tale ristorante.
Se proviamo adesso ad interrogare la tabella appena popolata, otteniamo questo risultato
Esattamente come era avvenuto per le tabelle nodo, viene aggiunta automaticamente una colonna contenente un JSON, chiamata $edge_id. Possiamo anche notare la presenza delle due colonne che puntano ai nodi collegati da questo arco (praticamente delle chiavi esterne), una riferita alla tabella di partenza (quella delle persone), cioè $from_id, e una riferita alla tabella di destinazione (quella dei ristoranti), cioè $to_id, popolate con il contenuto delle rispettive colonne $node_id che avevamo recuperato al momento di inserire i dati nell’arco. Anche in questo caso il nome “vero” delle colonne generate automaticamente è seguito da una stringa esadecimale, ma analogamente a quanto avveniva per le tabelle nodo, possiamo interrogarle omettendo il suffisso.
Volendo pensare in termini relazionali alla struttura appena creata, non abbiamo fatto qualcosa di molto diverso rispetto al creare una tabella molti a molti tra la tabella Persone e la tabella Ristoranti.
Se adesso riapriamo il menu delle Graph Tables su Management studio, troviamo le tre entità create finora.
Guardando l’icona a sinistra del nome è possibile distinguere tra tabelle nodo e tabelle arco, essendo le prime contraddistinte da un pallino pieno, mentre le seconde da un connettore che unisce tra di loro due pallini vuoti.
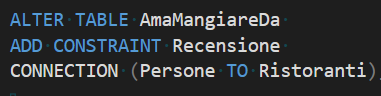
È importante osservare che di default tutti gli archi creati sono bidirezionali; ciò significa che, se non imponiamo nessun vincolo, potremmo inserire un record in cui un ristorante recensisce un utente, che costituirebbe uno scenario un po’ strano.
Per proteggerci da questa eventualità possiamo aggiungere un vincolo sull’arco che connette le persone ai ristoranti, in modo da imporre la direzionalità delle recensioni solo dalla persona verso il ristorante.
Come ultimo passaggio per completare il grafo di esempio che vogliamo riprodurre ho creato e popolato in modo del tutto analogo anche la tabella arco che rappresenta il legame tra due persone, chiamata AmicoDi ovvero un arco che collega la tabella Persone a sé stessa (stavolta senza attributi).
A questo punto abbiamo ricreato esattamente la struttura che volevamo, e possiamo eseguire qualche query per renderci conto di come estrarre informazioni dal sistema appena costruito.
La funzione MATCH
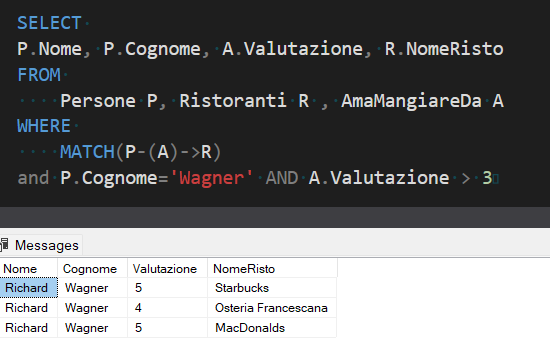
Come primo esempio vorrei trovare quali ristoranti il signor Wagner ha valutato con più di tre stelle: la forma della query sarà la seguente
L’aspetto più significativo di questa query è sicuramente la presenza della funzione MATCH e dell’indicazione che segue (P-(A)->R).
Quello che stiamo facendo nella FROM è sostanzialmente un prodotto cartesiano tra le tabelle Persone, Ristoranti e AmaMangiareDa: la funzione Match invece si preoccupa di stabilire la gerarchia tra queste entità, mostrando con una sintassi che riproduce in modo quasi visuale la relazione tra le tabelle considerando che il nostro scopo è quello di scoprire quale persona (P) ama mangiare (A) in quale ristorante (R).
Volendo possiamo complicare un po’ di più la cosa aggiungendo il livello della relazione tra le persone. Proviamo quindi a ricavare tutti i ristoranti con valutazione uguale a 5 recensiti dagli amici del signor Wagner.
Da questo comando è possibile notare che le tabelle nodo vanno specificate nella FROM n volte, una per ogni occorrenza nel MATCH, mentre all’interno del MATCH stesso abbiamo semplicemente aggiunto degli anelli alla catena per coinvolgere nella query anche le relazioni tra persona e persona.
La funzione SHORTEST_PATH
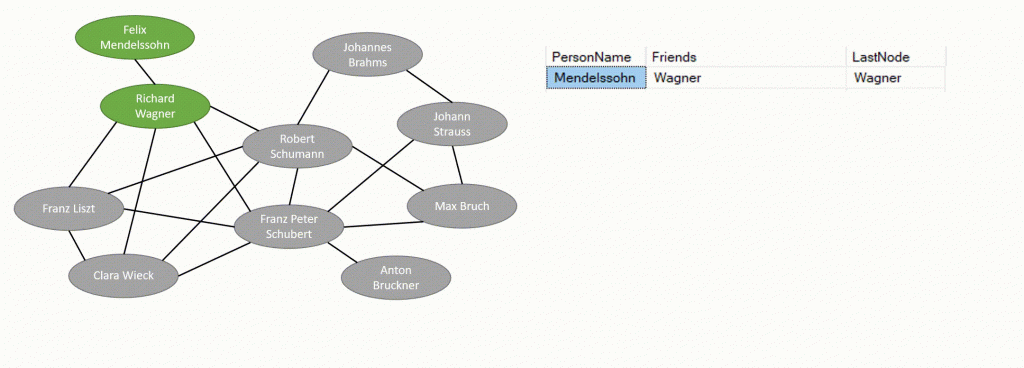
Abbiamo detto che i DB a grafo sono molto adatti per rappresentare i legami e le relazioni tipiche di un sistema come un social network; immaginiamo quindi che la nostra tabella Persone rappresenti un mini social network di compositori ottocenteschi, i cui membri siano relazionati in questo modo
Ricordiamo che abbiamo strutturato l’arco che referenzia la tabella “Persone” con sé stessa in modo che sia bidirezionale e che non sia pesato: Richard è amico di Clara esattamente come lei lo è di lui e l’amicizia tra loro due vale esattamente come l’amicizia tra qualunque altra coppia di membri direttamente connessi di questo diagramma.
La nostra esigenza in questo momento è quella di capire qual è il minimo percorso possibile per andare da una persona all’altra, per esempio da Felix Mendelssohn (in alto a sinistra) ad Anton Bruckner (in basso a destra).
A differenza di quanto si potrebbe credere questa operazione nasconde una certa complessità, dato che stabilire dei percorsi tra i nodi è un’operazione molto costosa, come scopriremo tra poco a nostre spese. La soluzione consisterà nell’intendere ciascun percorso come una serie di nodi raggruppati, un approccio che sarà determinante nel cercare di minimizzare i passaggi tra un nodo e l’altro.
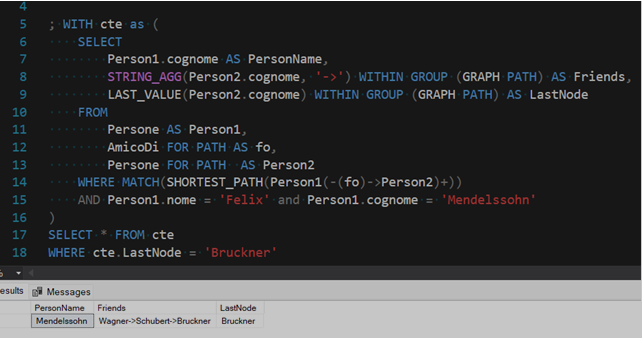
Lanciamoci in una veloce disamina di questa query, a partire dalla FROM.
L’espressione FOR PATH che segue l’arco e il nodo di destinazione ricorda in qualche modo una GROUP BY, dato che il suo scopo sarà quello di raggruppare i nodi che costituiscono il percorso minimo tra il nodo di partenza e quello di arrivo.
La funzione STRING_AGG è stata di recente aggiunta in SQL Server ed è una semplice concatenazione tra stringhe, che permette di collegare il set di nomi nella colonna Friends con i caratteri voluti (nel nostro caso, ‘->’), mentre la LAST_VALUE restituisce l’ultimo valore di un certo set (ovvero del nodo di destinazione).
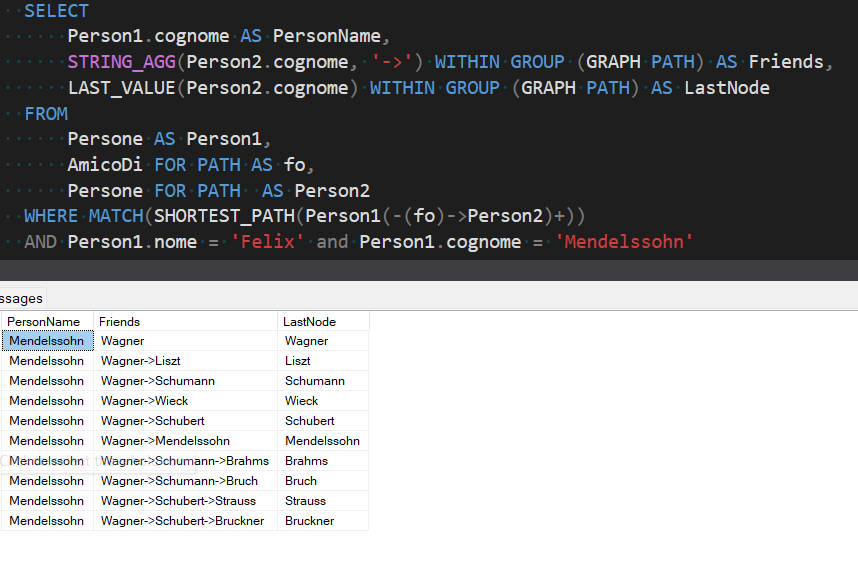
Infine nella WHERE troviamo, all’interno della MATCH che abbiamo già visto, la dicitura “SHORTEST_PATH”, che ricerca il percorso più breve tra un nodo e l’altro del diagramma. Alla sintassi ormai nota per specificare a quali nodi e quali archi siamo interessati (Person1(-(fo)->Person2) abbiamo in aggiunta un segno ‘+’ che sta ad indicare che vogliamo le informazioni riguardo all’intero percorso tra ciascun membro del nodo di partenza e di quello di destinazione, senza limitare il numero dei singoli passaggi. Ogni volta che la query viene eseguita, il risultato dell’esecuzione di questo modello sarà una raccolta ordinata di nodi e archi attraversati lungo il percorso, dal nodo iniziale al nodo finale.
Questa funzionalità merita alcune riflessioni. La prima è che, se eseguiamo solamente la CTE della query esposta in precedenza, otterremo come risultato i percorsi più brevi tra il nodo Mendelssohn e tutti gli altri nodi del grafico.
Questa considerazione deve sicuramente far scattare un campanello d’allarme dal punto di vista delle performance: se già in uno schema semplice come questo abbiamo così tante ramificazioni, sicuramente per una realtà più complessa le risorse impiegate per sfornare i risultati possono esplodere facilmente. Teniamo anche in considerazione che avevamo specificato esplicitamente il nodo di partenza, cioè Mendelssohn, nella condizione WHERE: non l’avessimo fatto avremmo ottenuto i percorsi che collegano tutti i nodi dello schema con tutti gli altri nodi.
Un’azione che sicuramente aiuta a migliorare le performance in uno scenario come questo consiste nell’aggiunta un indice sulle colonne $from_id e $to_id
Proprio per limitare il dispendio di risorse, anche se ci sono due o più percorsi che portano da un nodo ad un altro con lo stesso numero di passaggi, SQL Server ne mostrerà sempre e solo uno (scelto in base al primo trovato). Prendiamo ad esempio il percorso che viene mostrato come il più breve per andare da Mendelssohn a Bruch: ci viene mostrato il corretto cammino Mendelssohn->Wagner->Schumann-> Bruch, ma al tempo stesso viene ignorato quello del tutto equipollente Mendelssohn->Wagner->Schubert-> Bruch.
Un altro aspetto interessante da notare è che di default non c’è vincolo che escluda il nodo di partenza dai nodi di arrivo, troviamo infatti alla sesta riga il loop Mendelssohn -> Wagner -> Mendelssohn.
Purtroppo al momento la funzione SHORTEST_PATH non è in grado di essere parametrizzata in modo esplicito con i nodi di partenza e di arrivo; la conseguenza di ciò è che il filtraggio dei risultati deve essere eseguito in un secondo momento tramite opportune clausole WHERE, come in questo caso: una interna alla CTE per definire il nodo di partenza e una esterna per definire il nodo di arrivo.
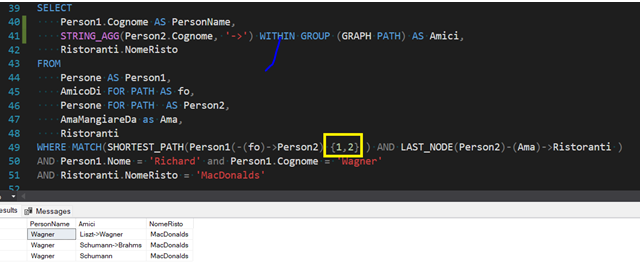
Come ultimo esempio possiamo indagare una sintassi alternativa al ‘+’ visto nella MATCH dell’esempio precedente, che ci permette di specificare a che livello di profondità fermare la nostra ricerca sui nodi.
In questa query abbiamo pertanto estratto tutte le persone ad un minimo di uno e un massimo di due livelli di distanza da Richard Wagner e che abbiano lasciato una recensione a MacDonalds. La prima condizione è fornita dal segmento di codice {1,2} che ha sostituito il segno ‘+’ visto in precedenza, il vincolo sulla presenza della recensione è invece espresso dalla seconda condizione all’interno della MATCH.
Conclusioni
Alla luce di queste considerazioni possiamo chiederci quando effettivamente possa convenire utilizzare un DB a grafo su SQL Server.
Attualmente SSMS non è ancora in grado di competere con tecnologie sviluppate appositamente, come Neo4j, OrientDB o HyperGraph DB, specie se teniamo presenti alcune limitazioni piuttosto importanti, ad esempio
- Non è permesso eseguire operazioni di UPDATE sulle colonne degli archi
- Tabelle temporanee e tabelle temporanee globali non sono supportate
- Non è possibile eseguire query cross-database
- Non c’è un modo diretto per convertire tabelle normali in tabelle di un DB a grafo
- Non esiste GUI: per visualizzare il grafo dobbiamo appoggiarci a strumenti esterni come Power BI
Se però la nostra esigenza è di sviluppare un DB a grafo non eccessivamente complesso e performante senza cambiare tecnologia, sicuramente questa funzionalità già completamente integrata in SQL Server può essere di grande aiuto.
Nota
Tutto il codice utilizzato nell’articolo è disponibile a questo link
https://drive.google.com/drive/folders/1DQo4CioViLCcNylA88T02aZeLRo9q40D?usp=sharing
Sitografia
https://docs.microsoft.com/en-us/sql/relational-databases/graphs/sql-graph-architecture?view=sql-server-ver15
https://docs.microsoft.com/en-us/sql/relational-databases/graphs/sql-graph-sample?view=sql-server-ver15
https://docs.microsoft.com/en-us/sql/relational-databases/graphs/sql-graph-shortest-path?view=sql-server-ver15
https://docs.microsoft.com/en-us/sql/relational-databases/graphs/sql-graph-overview?view=sql-server-ver15
https://docs.microsoft.com/it-it/sql/relational-databases/graphs/sql-graph-shortest-path?view=sql-server-ver15
https://medium.com/swlh/how-to-make-use-of-sql-server-graph-database-features-946ce38190cc
https://novacontext.com/getting-started-with-sql-server-graph/index.html
https://www.red-gate.com/simple-talk/databases/sql-server/t-sql-programming-sql-server/sql-server-2019-graph-database-and-shortest_path/
https://www.sqlshack.com/graph-database-features-in-sql-server-2019-part-1/



























{kind=link}