Introduci
la tua esperienza professionale dall’università fino all’ingresso in ORBYTA.
In sei anni ne ho percorsi di kilometri. Inizialmente lungo tutta la Calabria, offrendo la mia consulenza da imprenditore per i miei clienti. Lavoravo in una banca, trattavo tutti i servizi finanziari.
Decido poi e mi
sposto, capovolgendo lo Stivale. La voglia di mettermi in gioco non mi manca.
Entro così a far parte di un’assicurazione sanitaria storica italiana.
La mia esperienza mi
ha insegnato a mettere davanti le persone, i clienti, ai miei titoli. Ho
imparato ad ascoltare e a relazionarmi con diverse tipologie di
interlocutori.
Di
cosa ti occupi e che valore porti all’azienda?
Sono un anello in una
catena. Mi piace portare entusiasmo e voglia di fare. Mi piace mettermi in
gioco sfruttando le mie competenze tecniche-informatiche e funzionali dei
processi assicurativi.
Analizzo i processi
informatici e ne modello le soluzioni presenti. Con il mio team costruiamo le
soluzioni future. Facciamo in modo che gli ERP societari rispondano a pieno
alle esigenze degli utilizzatori, nel rispetto delle caratteristiche tecniche
del prodotto.
Perché
ti piace lavorare in ORBYTA?
Sarà che per anni ho
lavorato in una società cui lo slogan è “Costruita intorno a te”, ma
in ORBYTA sento davvero la vicinanza della struttura e la loro presenza.
È una società dinamica
e proattiva ed è in continua evoluzione. Caratteristiche che rispecchiano il
mio modo di intendere il lavoro per non perdersi le opportunità di business.
Scelta che rifarei,
rifarei mille volte ancora!
The chosen one: .NET 5
.NET 5, il successore di .NET Core 3.1 e .NET
Framework 4.8, mira a fornire agli sviluppatori .NET una nuova esperienza di
sviluppo multipiattaforma. Mette ordine alla frammentazione dell’universo .NET
che si è verificata nel corso degli anni e apporta nuove straordinarie
funzionalità. Di seguito i cinque punti su cui concentrarci per capire
agevolmente quali sono i punti di forza dell’ultima release per gli
sviluppatori di casa Microsoft.
1.Piattaforma Unificata
La prima cosa che c’è da sapere è che .NET 5
offre una nuova visione unificata del mondo .NET.
Se abbiamo già lavorato con .NET, dovremmo
essere a conoscenza della sua frammentazione di piattaforme sin dalla sua prima
versione nel 2002. .NET Framework è stato inizialmente progettato per Windows,
ma la sua specifica di runtime, nota anche come Common Language Infrastructure
(CLI), fu standardizzata come ECMA
335.
Questa standardizzazione consentì a chiunque
di creare la propria implementazione del runtime .NET. Infatti non si attese
molto per veder comparirne i primi all’orizzonte: abbiamo Mono per sistemi
basati su Linux, Silverlight
per applicazioni basate su browser, framework .NET Compact
e Micro
per dispositivi mobili e con risorse limitate e così via.
Per questi motivi, Microsoft decise di
scrivere .NET Core da zero pensando esclusivamente alla compatibilità
multipiattaforma. Queste diverse implementazioni hanno sollevato la necessità
di capire “dove” potrebbe essere eseguito un pacchetto .NET.
Dovresti creare versioni diverse della tua
libreria per distribuirla? La risposta a questa domanda fu .NET Standard,
ovvero una specifica formale delle API comuni che dovresti aspettarti tra le
implementazioni della CLI. In altre parole, se crei la tua libreria per uno
specifico .NET Standard, avrai la garanzia che verrà eseguita su tutti i
runtime che implementano tale specifica.
Si comprende dunque che, in questa situazione
disordinata, la compatibilità di implementazione desiderata non era così facile
da ottenere. Questo è il motivo per cui .NET 5 appare in scena.
La nuova piattaforma .NET è il successore
unificato delle varie versioni .NET: .NET Framework, .NET Standard, .NET Core,
Mono, ecc. È ufficialmente la prossima versione di .NET Core 3.1, ma
sostanzialmente determina la fine di .NET Framework, .NET Standard
e le altre varianti che hanno causato grossi grattacapi agli sviluppatori .NET.
.NET 5 fornisce un set comune di API che
allinea le diverse implementazioni di runtime. Questo set di API è identificato
dal Net5.0 Target Framework Moniker (TFM), che è il token impostato nel
progetto .NET per specificare il framework di destinazione. Ciò consente
l’esecuzione dell’applicazione su qualsiasi implementazione di runtime che
supporta .NET 5. Tuttavia, è comunque possibile compilare applicazioni per una
piattaforma specifica. Ad esempio, per creare un’applicazione che utilizza
l’API di Windows, è necessario specificare il TFM net5.0-windows. In questo
modo, la creazione di un’applicazione specifica per la piattaforma è una tua
scelta, non una scelta che dipende dall’implementazione di runtime che stai
utilizzando per sviluppare la tua applicazione.
Naturalmente, realizzare questa piattaforma
unificata ha richiesto uno sforzo significativo e una riorganizzazione
dell’architettura interna. Alcune funzionalità sono state rimosse dal set di
API di base, come vedrai più avanti, ma la piattaforma ha ottenuto un
miglioramento generale delle prestazioni.
Mentre il nuovo .NET 5 viene fornito con l’obiettivo di unificazione della piattaforma, il piano iniziale è cambiato a causa del COVID-19. In effetti, .NET 5 pone le basi dell’unificazione, ma sarà completato con .NET 6 a novembre 2021. Con tale rilascio, otterremo la versione stabile della nuova Universal UI ed anche il supporto per i TFM specifici per Android ( net6.0-android) e iOS (net6.0-ios).
2.Nuove funzionalità in C#
La seconda cosa da tenere a mente riguarda C#.
.NET 5 include C# 9, la nuova versione del principale linguaggio di
programmazione della piattaforma .NET. Ci sono diverse nuove funzionalità, e di
seguito ne troveremo un piccolissimo assaggio, giusto per farci “venir fame”.
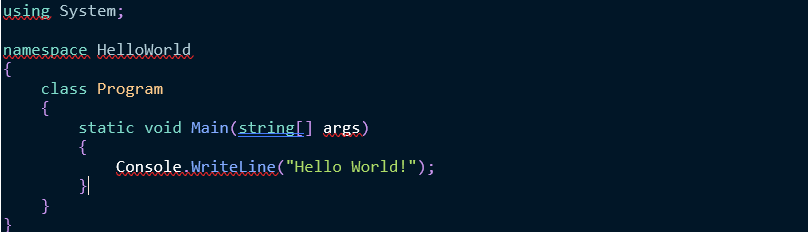
Dichiarazioni Top-Level
Tra le nuove funzionalità, una delle più
notevoli è l’introduzione di dichiarazioni top-level (o di primo livello). Per
sapere cosa sono, diamo un’occhiata al seguente programma:
Ebbene, il precedente blocco potrà essere
tranquillamente sostituito dal semplice ed unico:
Le istruzioni top-level consentono di
concentrarsi su ciò che conta davvero in piccoli programmi e utilità per
console e utilizzare C# con un approccio più orientato agli script.
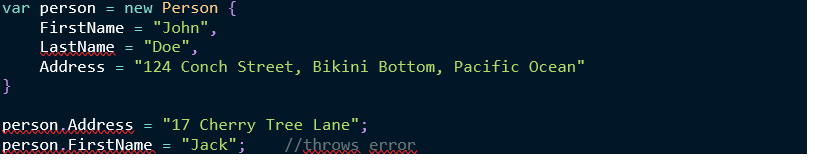
Tipi di record
Un’altra interessante novità sono i tipi di
record. Con i record, possiamo dichiarare un tipo di riferimento immutabile,
ovvero un tipo basato sulla classe che non può essere modificato dopo la sua
creazione. Un esempio di tipo di riferimento immutabile incorporato è la classe
System.String. Dopo aver creato un’istanza di System.String, non è più
possibile modificarne il valore.
Considera la seguente dichiarazione del tipo di record:
Possiamo creare un istanza del record Person
come faremmo per una classe, ma non ne possiamo alterare ad esempio la
proprietà FirstName.
Potremo comunque confrontare due istanze del
record Person come si trattassero di tipologie primitive:
Init setters
C# 9 aggiunge anche la funzione di init
setters per definire proprietà che possono essere solo inizializzate.
Consideriamo la seguente definizione di classe:
Questa classe definisce una persona con proprietà LastName e FirstName che possono essere inizializzate, ma non modificate. La proprietà Address può essere invece modificata in qualsiasi momento:
3. .NET MAUI, the Universal UI
Come terzo punto, dobbiamo sapere che .NET 5
offre un nuovo modo di creare interfacce utente multipiattaforma. Grazie al
framework UI dell’app multipiattaforma .NET, noto anche come .NET MAUI, saremo
in grado di creare interfacce utente per Android, iOS, macOS e Windows con un
unico progetto.
In realtà, questa funzionalità è ancora in
corso e verrà rilasciata con .NET 6, ma possiamo iniziare a dare
un’occhiata a .NET MAUI per essere pronto quando verrà rilasciato ufficialmente
fin dal .NET 5.
.NET MAUI può essere considerato un’evoluzione
di Xamarin.Forms, il framework open source per la creazione di app iOS e
Android con un’unica base di codice .NET. Ma questo nuovo framework propone un
modello universale per la creazione di interfacce utente su piattaforme mobili
e desktop.
Oltre al buon vecchio Model-View-ViewModel
(MVVM) pattern, .NET MAUI supporta anche il recentissimo Model-View-Update
(MVU).
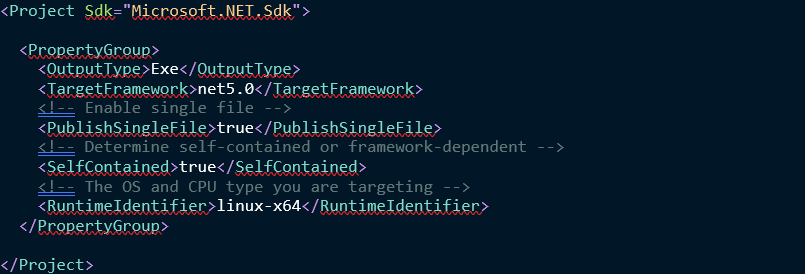
4.Supporto Single-File Applications
Altra grande feature che otterremo in .NET 5 è
il supporto alle single-file applications, ovvero applicazioni pubblicate e
distribuite come un singolo file. Ciò significa che la nostra applicazione e
tutte le sue dipendenze sono raggruppate in un unico file.
Ad esempio, supponiamo di eseguire il seguente
comando all’interno della cartella del nostro progetto .NET 5:
Otterremo un singolo file contenente l’intera
applicazione creata per Linux, tutte le dipendenze usate nel progetto ed il runtime .NET (–self-contained
true). Ciò significa che non è nemmeno necessario installare il runtime .NET
sul computer/server di destinazione.
Naturalmente, si potranno specificare questi parametri nella configurazione del progetto:
Notate bene che questa funzionalità non usa lo
stesso approccio delle applicazioni a file singolo che puoi compilare in .NET
Core 3.1. In .NET Core 3.1. L’applicazione a file singolo è solo un modo per
creare pacchetti binari: in fase di esecuzione vengono poi scompattati in una
cartella temporanea, caricati ed eseguiti. In .NET 5, l’applicazione a file
singolo ha una nuova struttura interna e viene eseguita direttamente senza
penalizzazioni delle prestazioni.
A questo
link è possibile trovare la documentazione di questa tipologia di rilascio.
5. Tecnologie non più supportate
Per ultimo punto, è obbligo parlare anche di
chi esce dal ciclo delle tecnologie supportate, non solo dei nuovi arrivati.
Come detto sopra, la revisione
dell’architettura e il tentativo di rendere .NET 5 un vero e proprio framework
di programmazione multipiattaforma ha portato alla rimozione di alcune
funzionalità supportate in .NET Framework. Diamo una rapida occhiata alle
funzionalità rimosse e alle possibili alternative.
Web Forms
Per molto tempo, ASP.NET Web Forms è stata la
principale tecnologia per creare interfacce utente web dinamiche. Tuttavia, non
è un segreto che la sua durata fosse strettamente legata al destino di .NET
Framework. .NET Core non supporta Web Form, quindi il fatto che non sia più
supportato in .NET 5 non dovrebbe essere una grande novità.
Tuttavia, abbiamo alcune alternative per
creare interfacce utente web. Se stiamo realizzando applicazioni web
tradizionali, Razor Pages è una di queste alternative. Se vuoi creare
applicazioni a pagina singola, puoi usare invece Blazor.
Windows Communication Foundation (WCF)
Anche WCF, il framework di comunicazione
tradizionale per Windows, sarà deprecato. Questo può sembrare un po’ scioccante
per gli sviluppatori che lo hanno utilizzato per creare le loro applicazioni
orientate ai servizi. Tuttavia, è abbastanza comprensibile se ci rendiamo conto
che l’obiettivo principale di .NET 5 è diventare un framework multipiattaforma.
L’alternativa a WCF consigliata da Microsoft è
la migrazione a gRPC.
Ma se abbiamo nostalgia di WCF o vuoi preparare una transizione graduale, puoi
provare il progetto open source CoreWCF.
Windows Workflow Foundation
Infine, .NET 5 non includerà nemmeno Windows
Workflow Foundation, la tecnologia del motore del flusso di lavoro disponibile
in .NET Framework. Non esiste un sostituto ufficiale per questa tecnologia.
Tuttavia, potremo usare un progetto di porting open source, CoreWF, per tentare di spostare i
flussi di lavoro esistenti su .NET 5 o crearne di nuovi.
Primi
Passi Insieme
Nella seconda parte di questo articolo
sperimenteremo insieme la creazione di un nuovo progetto web tramite Visual
Studio sfruttando il framework .NET 5 e mettendo subito alla prova il suo
aspetto multipiattaforma, pubblicandolo su di una macchina Linux (Ubuntu).
Non temiate la lunghezza della scrollbar
verticale del vostro browser, la guida è stata resa il più user-friendly
possibile riportando intere porzioni di codice e schermate dei “punti salienti”,
ecco spiegato il motivo della sua lunghezza.
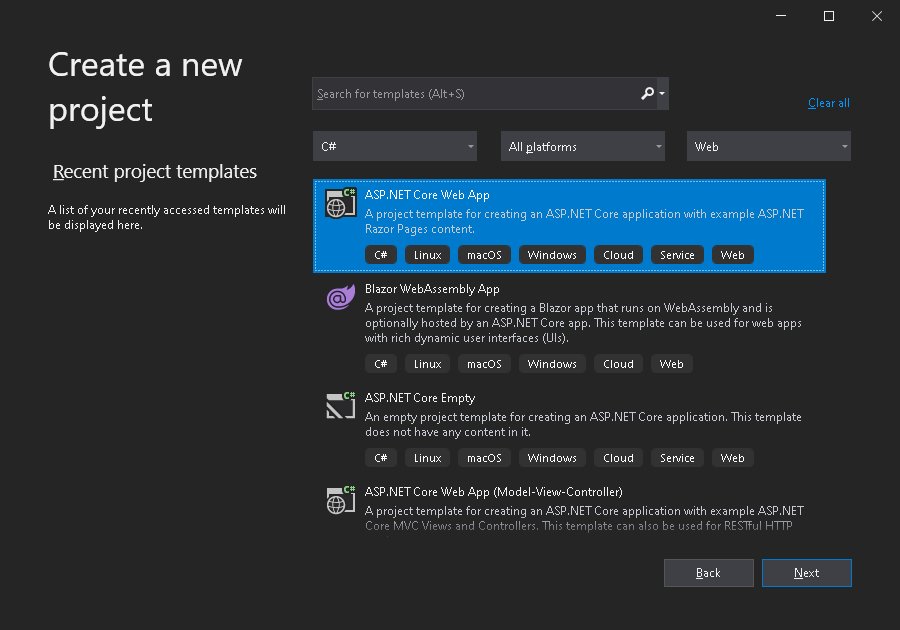
Creiamo
il nuovo progetto con Visual Studio
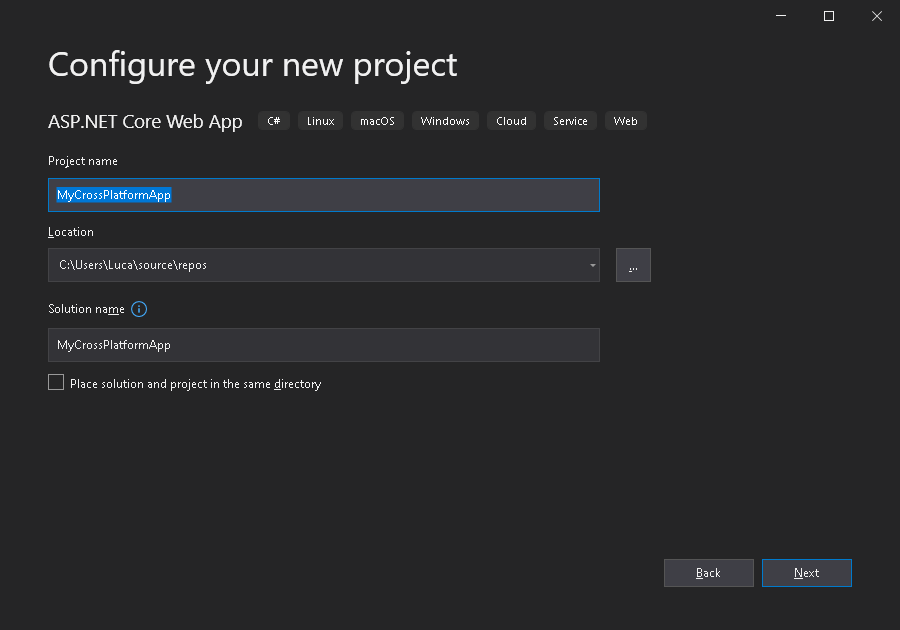
Creiamo il nuovo progetto cross platform “MyCrossPlatformApp”
partendo dal template “ASP.NET Core Web App”. Se non si trova il
suddetto template tra quelli disponibili, assicurarsi di aver selezionato la
voce “All platforms” e soprattutto che sia installata sul vostro Visual Studio
la relativa SDK.
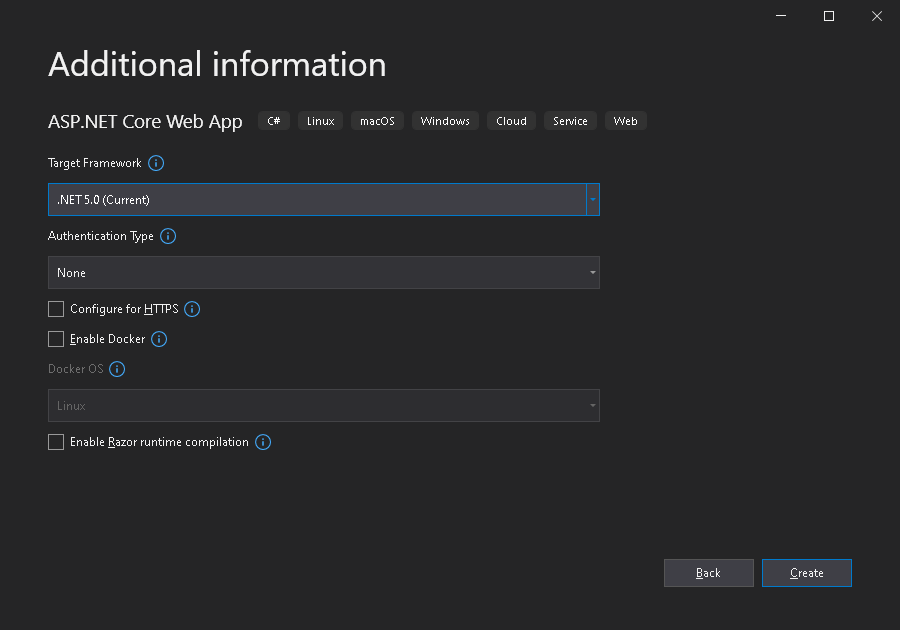
NB! E’ essenziale
selezionare come Target Framework -> .NET 5
Una volta completato lo scaffolding del nuovo
progetto possiamo tranquillamente procedere con la sua pubblicazione.
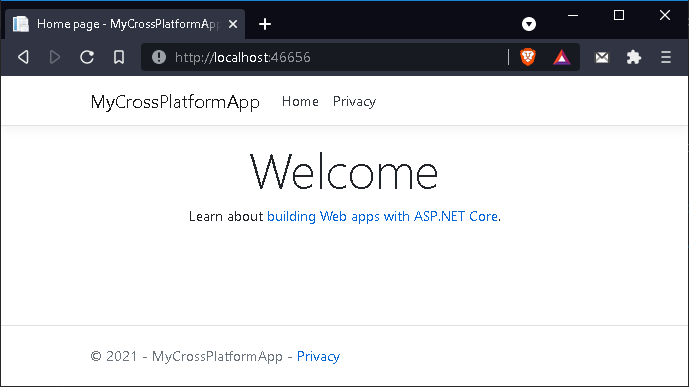
Non sono necessarie ulteriori modifiche
essendo il nostro obiettivo ultimo l’esecuzione del progetto su una macchina
Linux. Possiamo comunque provare a far partire il progetto per assicurarci che
non contenga errori (e che Visual Studio non stia tentando di nascosto di
sabotarci…).
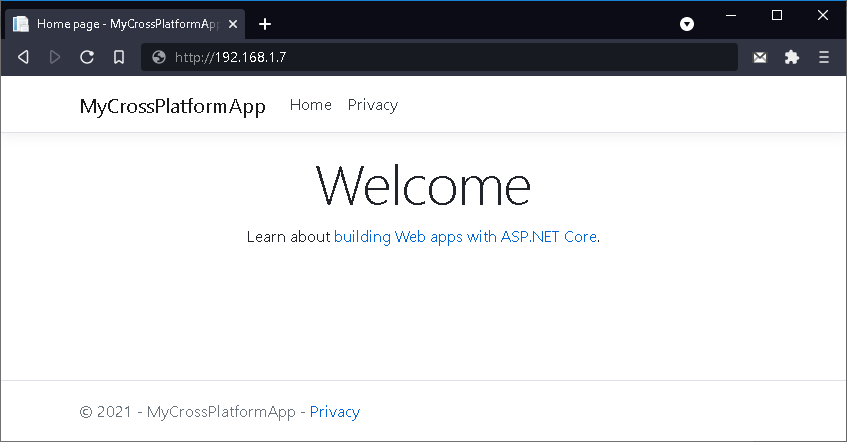
Il risultato sarà la classica pagina di
benvenuto del template selezionato.
Eradicati i nostri dubbi riguardo la bontà
della compilazione del progetto, possiamo finalmente pubblicarlo.
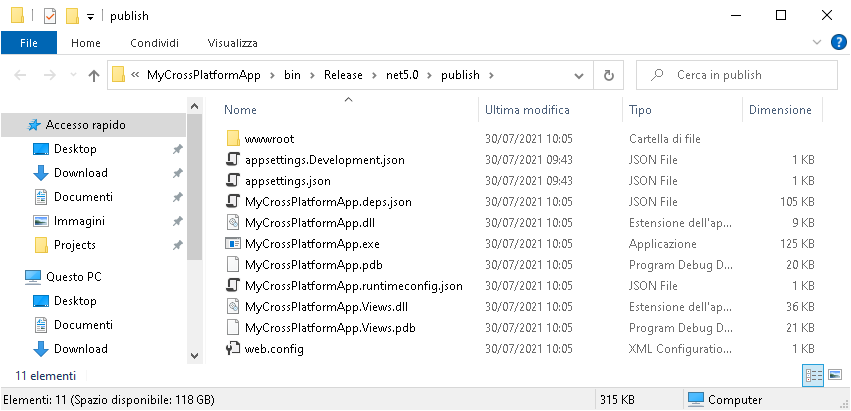
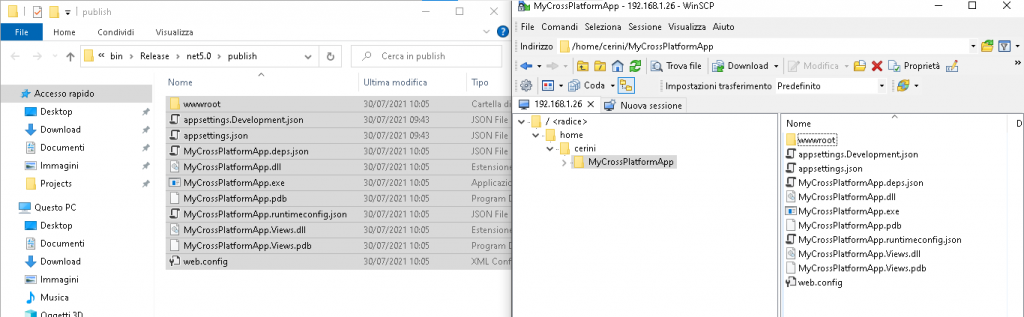
Il risultato della pubblicazione sarà una
cartella contenente exe, dll e files di configurazione del nostro applicativo,
compilati per il rilascio sulla nostra piattaforma desiderata.
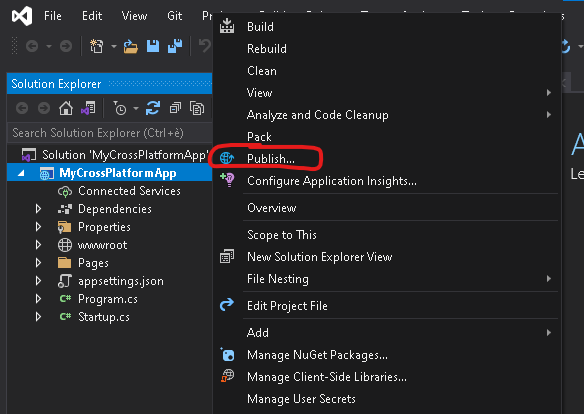
Procediamo dunque cliccando col destro sulla
nostra soluzione nell’explorer di Visual Studio e selezionado la voce Publish.
Questo avvierà il wizard di creazione di un
nuovo Profilo di Pubblicazione.
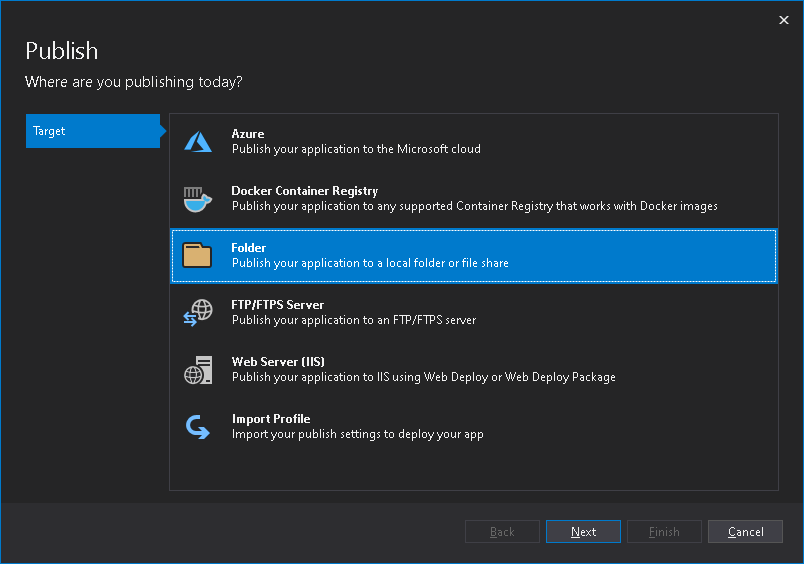
Delle varie modalità di pubblicazione,
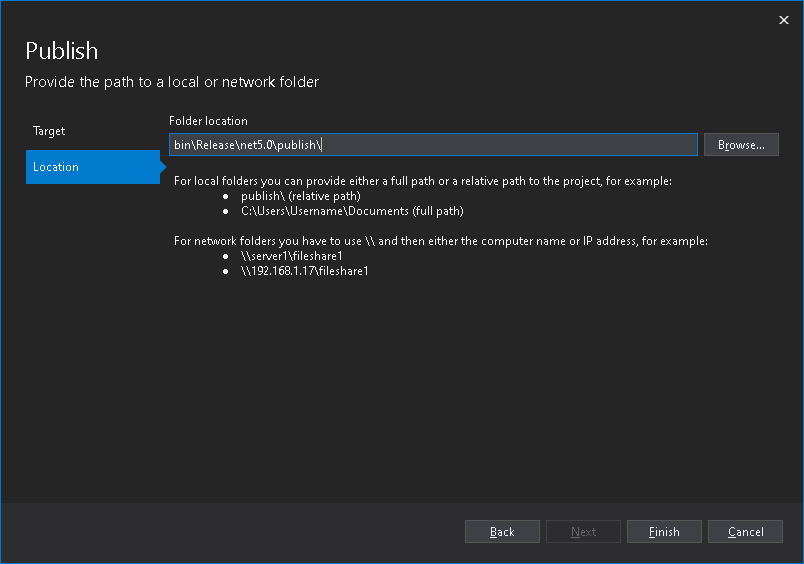
sceglieremo la più grezza e legacy, ovvero la pubblicazione su cartella/folder.
In questo modo, lasciando tutte le impostazioni di default proposte nella
successiva schermata, avremo il nostro risultato nella sotto cartella di progetto
bin\Release\net5.0\publish .
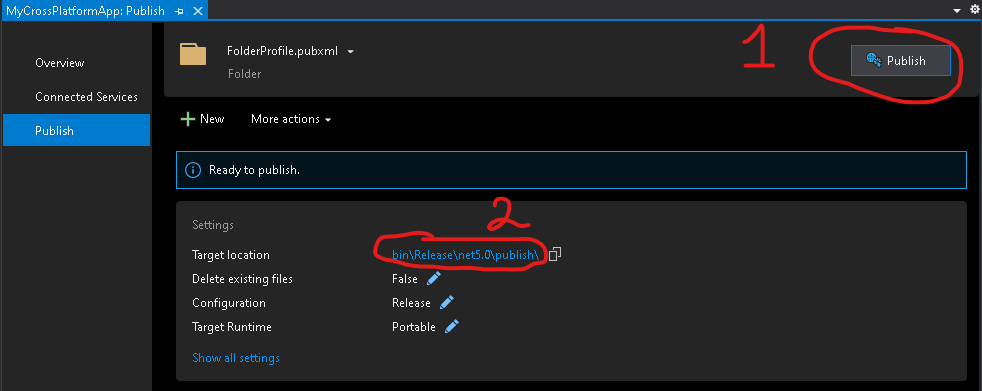
Una volta creato il nuovo profilo di
pubblicazione possiamo procedere cliccando dapprima su Publish (1) ed in
seguito esaminando il risultato cliccando sulla cartella di output (2).
Et voilà! Una
volta terminata la pubblicazione su cartella possiamo chiudere con Visual
Studio ed iniziare a dedicarci alla nostra macchina Linux. Essendo il progetto
compilato con un framework multipiattaforma (.NET5), nella cartella bin\Release\net5.0\publish
avremo tutto il necessario per far partire l’app su qualsiasi Sistema
Operativo in cui è installabile la relativa runtime.
Di seguito procederemo con la pubblicazione
sull’ultima versione server Debian e l’ultima versione long-term support di
Ubuntu Server.
UBUNTU 20.04 LTS & Apache
Prerequisiti
Salvo particolarissime eccezioni o
esigenze, sarebbe ideale cominciare a riscaldarci sul terminale con la solita
sfilza di formalismi necessari a partire con tutti i repositori e pacchetti
aggiornati:
sudo apt-get update
sudo apt-get upgrade
sudo apt-get dist-upgrade
sudo apt-get autoclean
sudo apt-get autoremove
Nonostante sia un appunto banale e
per molti scontato, tengo a precisare che per trasferire il nostro progetto sul
server Ubuntu in questa guida faremo uso del protocollo SFTP. Sarà dunque
necessario installare sulla macchina in questione la versione server di SSH (se
non già presente) con il comando:
sudo apt-get install
openssh-server
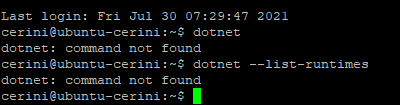
Step#1 – Installazione Runtimes
Per prima cosa dobbiamo assicurarci che siano
installate le runtime di .NET5 e ASP.NET Core 5. Procediamo con
il seguente comando per listarle tutte:
dotnet –list-runtimes
Se il risultato dovesse essere il seguente
(“command not found”) allora dobbiamo fare un passetto indietro, installandone
almeno una.
Installare le runtime .NET non è complicato.
come già visto per l’SSH, possiamo tranquillamente procedere con la loro
installazione tramite il packet manager di Ubuntu apt:
Runtime ASP.NET Core 5
sudo apt-get install
aspnetcore-runtime-5.0
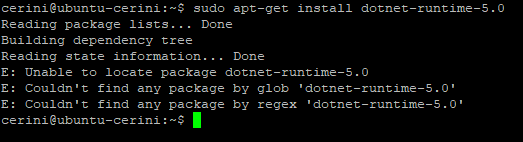
Con gran probabilità, arrivati a questo punto
vi scontrerete con la mancanza dei pacchetti dotnet-runtime-5.0 e aspnetcore-runtime-5.0
negli attuali repository della vostra macchina, come da screen di seguito (“Unable
to locate package (…)”) .
Non disperate: oltre alla guida ufficiale
Microsoft per l’aggiunta del repository (LINK)
potrete nuovamente fare affidamento a quanto segue di questa guida. Infatti,
per l’aggiunta dei repository ufficiali Microsoft sul nostro server Ubuntu
basterà eseguire i seguenti comandi:
A questo punto saremo in grado di ritentare
con successo l’installazione delle runtime .NET come descritto poche righe addietro,
assicurandoci infine che compaiano nella lista fornita dal comando:
dotnet –list-runtimes
Step#2 – Installazione & Config. Apache
Dobbiamo sapere che le applicazioni .Net
vengono eseguite su server Kestrel. Il nostro web server Apache fungerà
da server proxy e gestirà il traffico dall’esterno della macchina
reindirizzandolo al server Kestrel. Possiamo dunque vedere il nostro web server
Apache come un middle layer per l’applicazione .Net .
Di seguito vedremo come installare e
configurare un’installazione pulita di Apache sul nostro server Ubuntu per
servire la nostra applicazione.
Diamo quindi i seguenti comando per installare
Apache ed abilitare in seconda battutati i moduli proxy,proxy_http,
proxy_html e proxy_wstunnel.
Possiamo confermare la corretta installazione
di Apache navigando con un browser all’indirizzo del nostro server. Se tutto è
andato liscio, il risultato sarà la pagina di default di Apache con tanto di
messaggio evidenziato IT WORKS come da screen:
Arrivati a questo punto,dovremo creare un file
conf per configurare il nostro proxy su Apache.
Forniamo dunque il seguente comando per entrare nell’editor di testo nano :
sudo nano /etc/apache2/conf-enabled/netcore.conf
Copiamo ora la seguente configurazione nel
file vuoto appena aperto per poi salvarlo con la combinazione (per chi non la
conoscesse) CTRL+O -> INVIO -> CTRL+X .
NB! La porta 5000
è quella usata di default dal server Kestrel con cui si eseguono le
applicazioni .Net
Ora con il seguente comando ci assicuriamo che
non siano presenti errori nella configurazione appena create su Apache:
sudo apachectl configtest
A prescindere dai vari warning segnati, se
riceviamo infine il messaggio Syntax OK possiamo procedere con il
riavvio di Apache:
sudo service apache2 restart
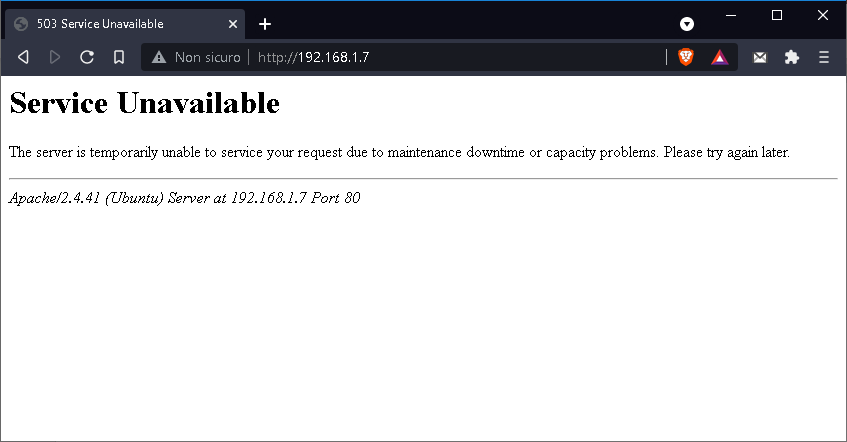
Effettuando nuovamente la navigazione con un
browser puntando all’indirizzo della nostra macchina, ci accorgeremo di non
avere più la pagina di default di Apache esposta, bensì un messaggio di Service
Unavailable . Risultato del tutto normale poiché Apache sta già
funzionando da server proxy, mirando in realtà alla porta 5000 della macchina sulla
quale non è ancora stata avviata la nostra applicazione .Net con
Kestrel.
Step#3
– Spostamento Progetto & Creazione Servizio
E’
giunto ora il momento di riversare il nostro progetto compilato sul nostro
server Linux.
Come
anticipato nelle premesse di questa guida, uno degli strumenti più comodi per
chi lavora su una macchina Windows è WinSCP, con il quale potremo trasferire
files tramite SFTP.
Prima
di spostare i files, sarebbe utile creare preventivamente la cartella di
destinazione del progetto, che nel nostro caso si chiamerà MyCrossPlatformApp
e sarà nella home della mia utenza cerini.
cd /home/cerini
mkdir MyCrossPlatformApp
Ecco che una volta connessi con WinSCP potremo
spostare comodamente il progetto nella cartella appena creata anche con un
semplice Drag&Drop.
Possiamo
finalmente testare il corretto funzionamento della nostra soluzione cross
platform e della bontà della configurazione del reverse proxy di Apache
avviando l’applicazione e facendo di conseguenza partire il server Kestrel
sulla porta 5000 col comando:
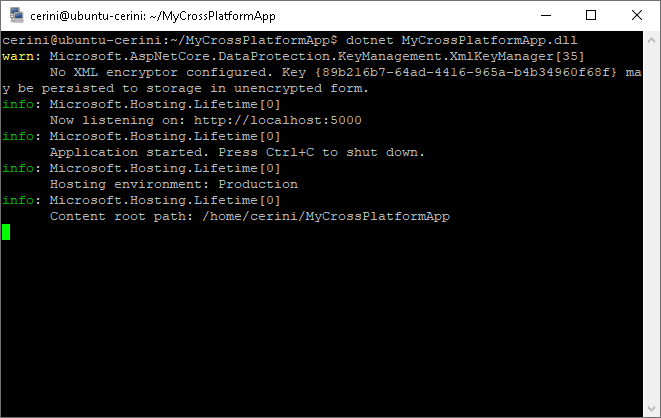
dotnet MyCrossPlatformApp.dll
Visitando
nuovamente col browser la nostra macchina, il messaggio di “Service
Unavailable” sarà soltanto un lontano ricordo.
Rimane
soltanto un ultimo “problema”:
l’esecuzione dell’applicazione è contestualizzata all’istanza di terminale che
ha lanciato il comando dot, dunque fin quando non ne termineremo
l’esecuzione con la combinazione di comandi CTRL+C, l’istanza di questo
terminale sarà occupata da questo unico job, impedendoci di usarla per
qualsiasi altro task.
E’
qui che entrano in gioco i service di Ubuntu. Un service (o servizio
se preferite in italiano) su Ubuntu costituisce la gestione regolarizzata
di uno o più processi in totale autonomia dell’OS ed in background.
Tra
i vari parametri configurabili di un servizio, troviamo quelli che ne
definiscono il tempo di esecuzione, partenza e comportamento in caso di errore,
come ad esempio il riavvio od un nuovo tentativo ad una certa distanza
temporale.
I
servizi su Ubuntu sono facilmente gestibili con il comando service o il
suo sinonimo systemctl, fornendo come parametro l’operazione da
effettuare sul servizio specificato:enalbe, disable, stop,
start, restart e status.
Creiamo
dunque il file di configurazione per il servizio che si occuperà di avviare (e
tenere avviata) la nostra applicazione .NET sul server.
Come in precedenza, usiamo l’editor nano per creare il suddetto file:
# Restart service after 10 seconds if the dotnet service crashes:
RestartSec=10
SyslogIdentifier=dotnet5-demo
User=www-data
Environment=ASPNETCORE_ENVIRONMENT=Production
[Install]
WantedBy=multi-user.target
Tra le config più interessanti troviamo la WorkingDirectory con cui
diamo il contesto della cartella di esecuzione, ExecStart che definisce
il vero e proprio comando da eseguire (dotnet + dll), Restart e RestartSec
con cui definiamo il comportamento in caso di errore/crash del servizio.
Possiamo
dunque abilitare il servizio e tentarne l’avvio:
sudo systemctl enable
MyCrossPlatformApp
sudo systemctl start
MyCrossPlatformAppt
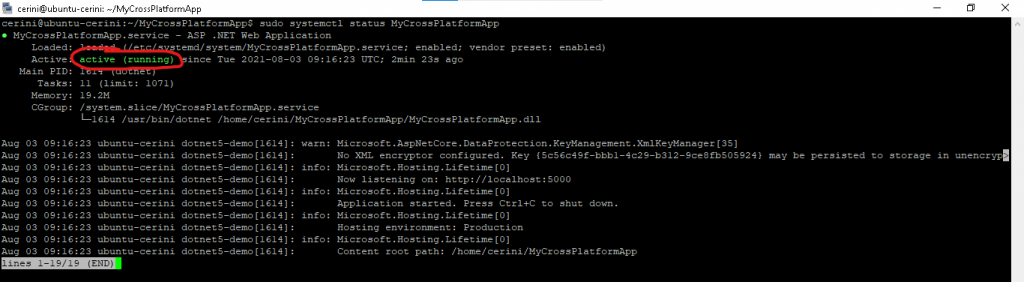
Controlliamo
infine che sia correttamente partito con:
sudo systemctl status
MyCrossPlatformApp
La
prova del nove la potrete tranquillamente avere navigando come al solito dal
vostro browser.
Provare
per credere! E se vi sentite fortunati (e ne avete la possibilità) provate a
riavviare il vostro server: il servizio avvierà la vostra applicazione .NET
automaticamente una volta ripartito Ubuntu.
Articolo a cura di Luca Cerini, Senior Developer in Orbyta Tech, 07/09/2021
Introduci la tua
esperienza professionale dall’università fino all’ingresso in ORBYTA
Nel luglio del 2019 mi sono laureata in
Lingue e letterature moderne presso l’Università degli Studi di Torino. A
differenza di altri percorsi di formazione, sapevo che, terminati gli studi,
avrei dovuto tracciare la mia strada e costruirmi un profilo
professionale.
Conseguita la laurea, ho iniziato a
cercare contesti in cui potessi esprimermi al meglio e, dopo qualche esperienza
in diverse realtà, è iniziato il mio percorso nell’ambito delle risorse umane
presso un’agenzia per il lavoro.
L’esperienza in agenzia mi ha fatto
appassionare al punto di voler ampliare la conoscenza del settore anche
all’interno di un contesto aziendale. Di qui l’inizio in ORBYTA nel luglio del
2020 nell’ufficio HR.
Di cosa ti occupi e che valore porti
all’azienda?
L’esperienza di stage nell’ufficio HR termina
a febbraio 2021 con il mio ingresso in ORBYTA People.
Oggi mi occupo della gestione del flusso
paghe per le società del gruppo e del servizio payroll e gestione risorse umane
che offriamo alle aziende clienti.
Il valore che porto all’azienda si
traduce in passione, impegno ed entusiasmo. Mi piace lavorare bene e sodo per
contribuire al raggiungimento degli obiettivi e al miglioramento dei processi.
Perché ti piace lavorare in ORBYTA?
Mi piace lavorare in ORBYTA perché viene
dato valore alla parola di ciascuno. È un contesto dove è possibile esprimere
il proprio potenziale, confrontarsi e formarsi.
Ogni giorno si vive una realtà
stimolante e dinamica affiancata da professionisti che sono veri e propri
mentori per la crescita personale e professionale.
Essere un Orbyter va oltre il concetto
di lavoro. Significa condividere un progetto, avere una visione comune che
stimoli la costante crescita di tutto il gruppo ed io sono contenta e fiera di farne
parte.
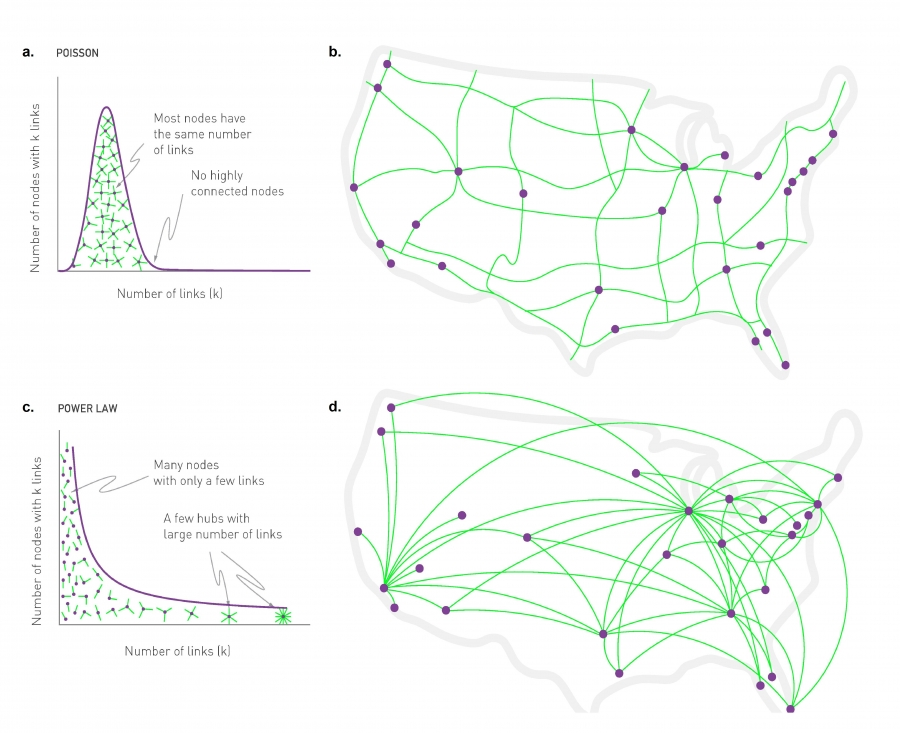
I network (o reti) sono uno strumento potente ed efficace per rappresentare la realtà che ci circonda e sono infatti presenti in quasi ogni aspetto della nostra vita. Amici, parenti, il Web, le strade di una città… tutto può essere modellato sotto forma di network. Lo scopo di questa rappresentazione è quello di studiare un sistema cercando di catturarne la sua complessità e le relative cause. In generale, un network è la semplice descrizione di un insieme composto da entità interconnesse, che chiamiamo nodi, e le loro connessioni/relazioni, che chiamiamo link. I nodi possono rappresentare ogni genere di entità: persone, luoghi, siti web, cellule, etc. Le relazioni a loro volta possono esprimere ogni tipo di interazione/scambio/flusso che avviene fra due entità, quindi pagamenti, scambi di messaggi, like su Facebook, etc.
Nota: In questo articolo i social network vanno intesi come reti sociali e non come i siti di social networking come Facebook e Twitter.
I network sociali sono un particolare tipo di network dove i nodi sono persone interconnesse da un qualche tipo di relazione. Ci sono tantissimi tipi di social network, al punto che questa è la categoria di network più studiata in assoluto. Per esempio la sociologia, il ramo da cui è partito lo studio delle reti sociali, cerca di stabilire delle regole emergenti dal comportamento collettivo degli individui. Nell’ambito della medicina si può studiare la propagazione di malattie attraverso una rete sociale, in economia si studia come il comportamento di un individuo influenza quello di un altro sulla base di meccanismi di incentivi ed aspettative degli altri. Nel campo della ricerca i social network vengono utilizzati per studiare gli autori più influenti e come hanno collaborato fra loro nello studio di un determinato argomento.
La complessità delle connessioni della società moderna, data da fenomeni come internet, crisi finanziarie o epidemie è data dal comportamento aggregato di gruppi di persone le cui azioni hanno conseguenze sul comportamento di tutti gli altri. Il crescente interesse verso lo studio di tale complessità ha reso la Social Network Analysis uno degli strumenti di visualizzazione e rappresentazione dei sistemi complessi più utilizzati.
Teoria dei Grafi
La Social Network Analysis ed in generale tutta la Network Science si basa sui concetti chiave della teoria dei grafi di nodo e legame, andando ad ampliare questa branca della matematica con una serie di termini e metriche propri, dati dallo sviluppo autonomo di questo campo di ricerca.
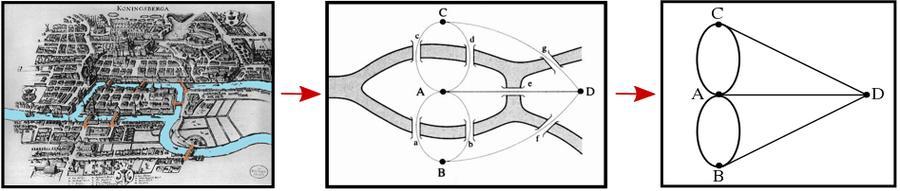
L’avvento della teoria dei grafi si riconduce a un aneddoto del 1736 della città Prussiana di Königsberg, città natale di Immanuel Kant e Leonhard Euler, per noi Eulero. Eulero si trovò ad affrontare un problema matematico legato alla città di Königsberg, la quale era divisa ai tempi in quattro settori dal fiume Pregel, connessi tra loro da sette ponti. Solo cinque di questi sono sopravvissuti ai bombardamenti della Seconda guerra mondiale e allo stesso modo molti edifici sono stati demoliti. Il problema con cui si cimentò Eulero, irrisolto fino a quel momento, era quello di collegare tutti e sette i ponti potendo passare solo una volta su ciascuno di questi.
Eulero formalizzò il problema ricorrendo a un grafo i cui nodi erano i quattro settori della città, e i collegamenti erano i ponti. Dimostrò così che un tale percorso esiste solo se tutti i nodi hanno grado (numero di link) pari, tranne la partenza e l’arrivo. Questo tipo di percorso, rinominato poi Eulerian path in suo onore, non è effettivamente possibile in questo sistema in quanto ognuno dei quattro nodi ha un numero dispari di connessioni. La vera novità di questo approccio fu l’aver formalizzato in forma topologica il problema, andando a definire questo tipo di percorso come una proprietà intrinseca del grafo.
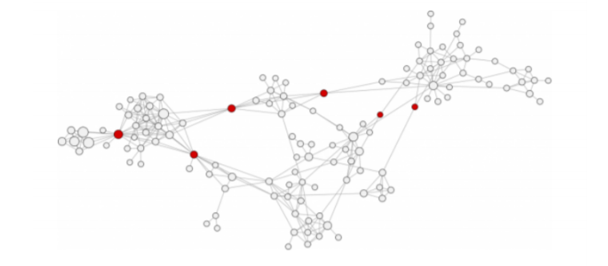
La forza dei legami deboli e la Small-World property
La teoria della “forza dei legami deboli” nasce da uno studio di Mark Granovetter degli anni 60 diventato poi un classico della sociologia. Granovetter, attraverso una serie di interviste, andò a studiare come le persone che avevano recentemente cambiato mestiere a Boston fossero venute a conoscenza della nuova opportunità. La maggior parte di queste persone erano immigrati irlandesi, i quali erano soliti trascorrere una buona quantità di tempo nei pub. Il lavoro ed in particolare quello edilizio, settore principale di queste persone, era molto instabile portando a frequenti passaggi dallo stato di occupazione a quello di disoccupazione. L’obiettivo iniziale della ricerca era di capire il ruolo delle conversazioni nei pub nella ricerca del nuovo lavoro. Scoprì che molte persone avevano trovato il nuovo lavoro attraverso i contatti personali e pertanto decise di soffermarsi proprio su questi. Emerse dalla sua ricerca che questi contatti erano perlopiù conoscenti piuttosto che amici stretti. Solo il 30% degli intervistati aveva trovato lavoro attraverso i contatti più stretti.
Da qui la distinzione tra legami forti e deboli. I legami forti erano amici e parenti, mentre i legami deboli semplici conoscenti. Granovetter teorizzò quindi che i legami forti sono maggiormente disposti a fornire un supporto emotivo, ma appartenendo alla stessa cerchia di chi in questo caso sta cercando lavoro, hanno meno possibilità di fornire informazioni che non conosciamo. I legami deboli a differenza, appartenendo a cerchie da noi distanti sono in contatto con realtà a noi sconosciute ed hanno per questo accesso a informazioni nuove. Le implicazioni di questo studio sono vastissime e tuttora oggetto di studio. Il perché i social media siano diventati uno strumento così potente è riconducibile proprio al concetto di legame debole. Essenzialmente, i social media non fanno altro che mantenere ed amplificare i legami deboli, definiti in questo caso come legami sociali che non richiedono alcun attaccamento emotivo, necessità di comunicare o tempo da dedicare. Nonostante questo, risultano estremamente potenti in quanto fungono da canali per il passaggio di informazioni tra persone distanti sia in termini fisici che sociali (es reddito, cultura, etc). Quando due persone comunicano attraverso un legame debole, l’informazione che passa attraverso di esso è di solito nuova, e proviene da un diverso punto di vista.
Dal punto di vista dei network i legami forti (come quelli tra coniugi e amici intimi) tendono a riunire i nodi in cluster stretti e densamente interconnessi. All’interno di questi cluster si sviluppa una conoscenza specifica ma non si generano conoscenze “distanti” a livello di contenuti. Poiché diverse nicchie conservano diversi tipi di conoscenza, sono i collegamenti tra i questi sub-network a permettere la condivisione. Tali collegamenti sono chiamati ponti. Granovetter ha quindi capito che nelle reti sociali i legami che tengono insieme la rete stessa sono, paradossalmente, i legami “deboli”.
La famosa teoria dei sei gradi di separazione si basa proprio su questo concetto, ovvero che attraverso i semplici legami deboli due persone qualunque del globo sono in grado di entrare in contatto mediante un massimo di sei persone. L’esperimento fu condotto negli anni 60 da Stanley Milgram, data a cui risale la prima prova empirica dell’esistenza dei cosiddetti network small world. L’idea era quella di misurare la distanza sociale fra sconosciuti. Furono quindi selezionate 160 persone in Kansas e Nebraska per mandare una lettera a una persona selezionata in Massachussets. Ogni persona doveva mandare la lettera alla persona di sua conoscenza che reputava più adatta a raggiungere il destinatario. In questo caso solo il 26% di lettere arrivarono a destinazione correttamente, mostrando però che il numero medio di intermediari erano di poco superiori a 6. L’esperimento fu ripetuto nel 2003 usando però le email. Anche in questo caso si mise in luce il fatto che il path medio in termini di persone erano 5-7 individui. La maggior parte dei network del mondo reale hanno il percorso critico (il più veloce) medio molto breve, secondo quella che viene definita small word property. Questa proprietà rende le reti molto efficienti in termini di velocità di propagazione delle informazioni.
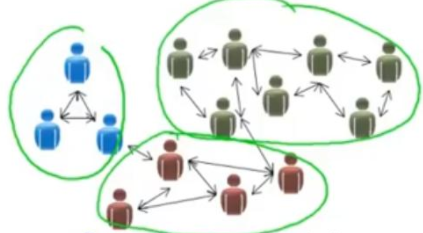
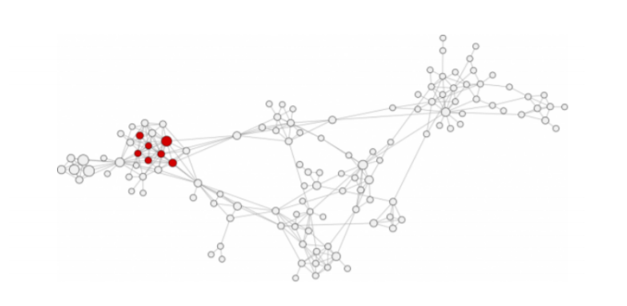
Una caratteristica che si osserva nelle reti sociali è che gli individui tendono ad aggregarsi in comunità, dette cluster. Questa proprietà, già nota nella sociologia come transitività, è stata poi ripresa nella network science con il nome di clustering. Come tale, questo coefficiente esprime la misura di quanti amici di un individuo sono a loro volta amici fra loro. A livello di rete si calcola come frazione di tutti i possibili triangoli (o triadi) che esistono nella rete, mentre a livello di singolo nodo corrisponde alla frazione di tutti i possibili triangoli che contengono il nodo in esame.
Una delle modalità per cui si formano cluster è quella della vicinanza a un altro nodo. Anche questo concetto è ampiamente trattato nella Social Network Analysis, e prende il nome di assortatività. Essa esprime la preferenza per un nodo ad interagire con un altro nodo avente caratteristiche simili. Nel caso delle reti sociali queste caratteristiche possono essere sesso, età, luogo, argomenti di interesse e così via. Alcuni ricercatori hanno visto che è possibile stabilire con una certa accuratezza l’orientamento politico di un individuo anche se non presente nel suo profilo guardando le caratteristiche della sua cerchia di amicizie. Una regola empirica è che se due persone sono simili in qualche modo, è più probabile che si selezionino a vicenda e diventino due nodi interconnessi. A questo aspetto si lega la teoria delle bolle di filtraggio di Eli Pariser che sarebbe interessante approfondire, ma questo esula dal tema dell’articolo.
Watts–Strogatz Model
Per studiare come emergono le caratteristiche di un network, come la small world property o il clustering, si utilizzano degli algoritmi di simulazione che generano dei modelli. Questi modelli vengono poi comparati con i dati reali per capirne le differenze e studiarne i meccanismi.
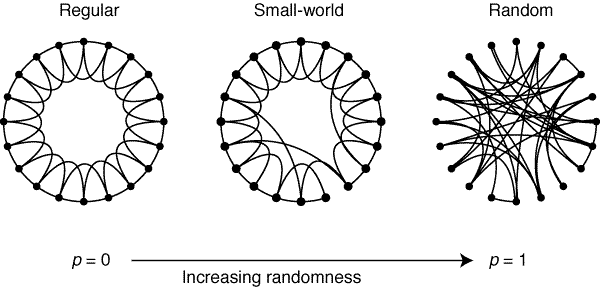
Il modello Watts–Strogatz (1998) è un network avente proprietà small world che allo stesso tempo possiede un buon coefficiente di clustering. Può essere generato in modo sperimentale risultando in un network dove la maggior parte dei nodi sono collegati a un numero relativamente ristretto di vicini in maniera piuttosto regolare, con alcune eccezioni dati da legami deboli con nodi distanti. Watts e Strogatz notarono che nel mondo reale non si riscontravano pressoché in nessuna situazione né network regolari, dove tutti i nodi sono strettamente legati ai propri vicini, né network completamente randomici, dove invece i collegamenti fra nodi non seguono nessuna logica particolare. Osservarono infatti che la realtà circostante era sempre una via di mezzo fra questi due tipi di network, ovvero una forte aggregazione in cluster tipica di un network regolare e allo stesso tempo una forte propensione alla propagazione di informazioni secondo la small world property, tipica invece di un random network. La soluzione che proposero è quindi l’interpolazione di questi due estremi.
L’algoritmo di generazione di un modello Watts–Strogatz parte da un network regolare dove tutti i nodi sono connessi ai propri vicini, e in modo randomico elimina alcuni di questi collegamenti andandoli a sostituire con collegamenti a nodi più distanti. In questo modo le proprietà topologiche locali fra nodi vicini rimangono intatte, ma si permette ai legami deboli di fungere da collegamento con nodi anche molto distanti.
.
Fonte: https://www.nature.com/articles/30918
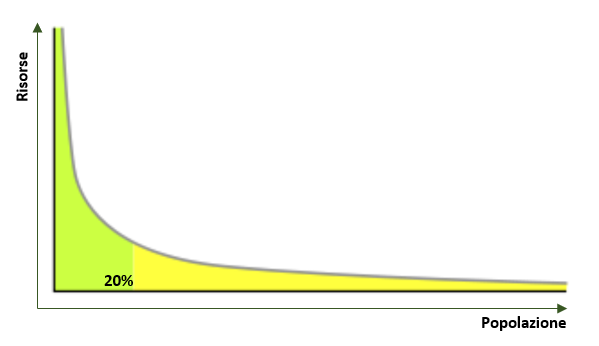
Il problema delle reti Watts-Strogatz è dato dall’inaccuratezza nella distribuzione dei gradi (il numero di collegamenti di ciascun nodo). Il numero di vicini di un nodo è infatti circa lo stesso per tutti i nodi, e differisce leggermente dal valore medio, seguendo così una distribuzione di Poisson. Risulta così un network molto omogeneo, che non rispecchia però la distribuzione delle reti reali. Nel mondo reale si assiste infatti a una fortissima disuguaglianza fra il grado dei nodi, secondo quella che viene definita “legge di potenza”, ovvero ci sono molti nodi con poche connessioni e pochi nodi con molte connessioni. Barabasi e Albert hanno considerato questo aspetto andando a creare un modello che si basa sulla legge di potenza. Una distribuzione che segue la legge di potenza è denominata power law distribution, distribuzione a invarianza di scala (scale-free distribution) o anche distribuzione di Pareto. La peculiarità di questo tipo di distribuzioni sta proprio nell’assenza di una scala caratteristica dei fenomeni.
Il modello Barabasi-Albert (1999) si discosta dal modello Watts-Strogatz aggiungendo realismo nel meccanismo di clustering dei nuovi nodi. Mentre il modello Watts-Strogatz parte da un set di nodi dall’inizio alla fine, il Barabasi-Albert aggiunge i nodi uno per volta rendendo il modello dinamico.
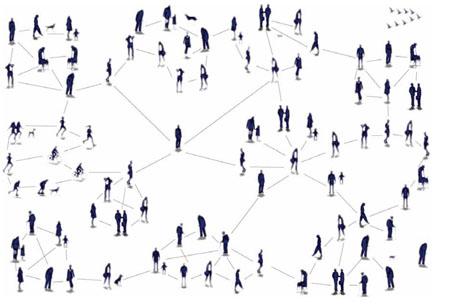
L’idea alla base è di generare una rete secondo una progressiva aggregazione di nodi seguendo una logica di preferenza verso i nodi più grandi, chiamata attaccamento preferenziale. In altre parole, quando si aggiungono nuovi nodi, questi andranno a connettersi tendenzialmente a nodi già largamente interconnessi, che vengono definiti hub.
Fonte: https://makeagif.com/i/0Ccn3L
Questo principio viene anche definito come “rich get richer”, ovvero i nodi più grandi tendono a diventare ancora più grandi. La probabilità che un nuovo nodo si colleghi a uno vecchio è proporzionale al grado del vecchio nodo. Per esempio un nodo con grado 10 è 10 volte più probabile che venga raggiunto da un nuovo nodo rispetto a un altro nodo avente grado 1. La proprietà di small world viene in questo caso garantita proprio dagli hub, che fungono da ponte principale fra coppie di nodi non collegati.
Questo tipo di modello trova un ampissimo riscontro nel mondo reale, come per esempio le pagine Web. Numerosi studi hanno dimostrato che più un sito è citato, ossia possiede più hyperlink, e più è probabile che verrà citato nuovamente e viceversa. La causa sottostante a questo fenomeno è spiegata dal fatto che più hyperlink ha un sito web e più è visibile, di conseguenza è più probabile che il sito riceva altri hyperlink. Questo stesso meccanismo si manifesta allo stesso modo nella legge di Pareto, per cui la ricchezza tende a concentrarsi nelle mani di pochi individui molto ricchi mentre è molto scarsa nel resto della popolazione (il 20% della popolazione possiede l’80% delle risorse, oppure il 20% delle parole di una lingua compongono l’80% del parlato).
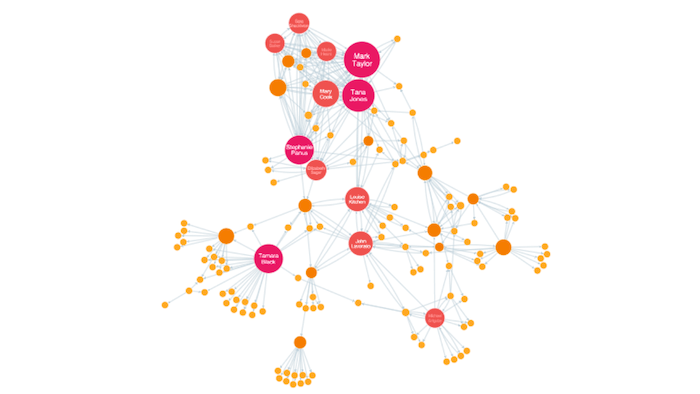
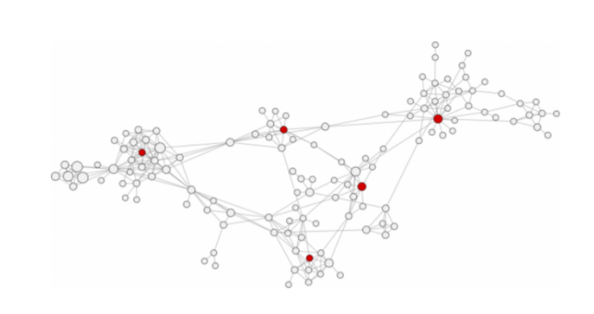
Misure di centralità
Spostando l’analisi a livello di singolo nodo all’interno della rete, la SNA permette di studiare le relazioni di ogni attore nella rete mostrandone le gerarchie e fornendo un quadro per spiegare la struttura e l’evoluzione dei singoli nodi e dei gruppi di nodi. Le reti sociali sono sistemi complessi e come tali necessitano di una moltitudine di metriche e strumenti di analisi. Le principali sono le centralità, ma vi sono anche la distribuzione dei gradi, la topologia della rete locale, la struttura della comunità e l’evoluzione della rete.
La prima domanda che potrebbe sorgere analizzando una rete è: chi è il più importante?
Ovviamente la risposta è dipende, e qui andremo a spiegare brevemente perché.
Generalmente sono le misure di centralità a rispondere a questa domanda. Le misure di centralità sono usate per calcolare l’importanza di un individuo all’interno del network, tuttavia sono vari i criteri di importanza: potere, l’influenza, o altre caratteristiche individuali delle persone. Per questo motivo ci sono diverse misure di centralità della rete. Analizzeremo le 4 principali.
Degree centrality
Se si vuole misurare il numero di connessioni che ha un individuo allora la degree centrality fa al caso nostro. Su Facebook per esempio corrisponderebbe al numero dei nostri amici. E’ logico pensare che più una persona abbia collegamenti e più abbia influenza sulle altre persone. Ma non è necessariamente così. Scott Adams, il creatore del fumetto Dilbert, sostiene che il potere di una persona è inversamente proporzionale al numero di chiavi nel suo portachiavi. Un custode ha le chiavi di tutti gli uffici e nessun potere. L’amministratore delegato non ha bisogno di una chiave, c’è sempre qualcuno ad aprirgli la porta. Effettivamente sono molti i casi in cui una persona di potere ha relativamente pochi contatti e per questo sono necessarie altre metriche di centralità.
Una breve digressione può essere fatta riguardo le due sottomisure della degree-centrality date dal numero di link in entrata o in uscita di un nodo, ovvero centralità in-degree e out-degree. Questo aspetto è interessante perché viene usato per misurare il livello di fiducia verso un individuo della rete. Semplificando molto (in quanto bisognerebbe tenere conto di molti altri aspetti), un attore con un basso valore di fiducia può essere identificato da un alto valore di centralità out-degree a cui corrispondono bassi valori di centralità out-degree degli attori con cui comunica. Ciò può essere spiegato dal fatto che questo attore si sente sicuro nel diffondere informazioni, ma gli altri attori non diffondono queste informazioni perché non reputano affidabile tale informazione.
Un altro modo di misurare la centralità è quello di guardare quanto un nodo è “vicino” agli altri nodi. La closeness centrality è usata per misurare la lunghezza media del percorso più breve da un nodo verso un qualunque altro nodo. Maksim Tsvetovat e Alexander Kouznetsov la definiscono la misura dei gossippari poiché rappresenta l’abilità di un attore di trasmettere o condividere informazioni da un lato del network all’altro. Minore è la distanza totale nella rete e più la closeness centrality sarà alta. In altre parole, rappresenta la velocità con cui l’informazione può raggiungere altri nodi da un dato nodo di partenza: i gossippari fanno arrivare le informazioni molto più velocemente degli altri.
Betweeness Centrality
La betweeness centrality è una misura che viene usata per studiare il ruolo di un nodo nella propagazione di una informazione. Se un nodo è l’unico collegamento ponte fra altri due nodi si può dire che abbia una posizione in qualche modo privilegiata o strategica. La Betweeness Centrality va a misurare proprio questo valore. Viene infatti spesso usata per misurare il traffico nei network di trasporti. Si calcola andando a contare quante volte un nodo è attraversato da un percorso critico (il percorso più breve, o anche Eulerian path) rispetto al totale dei percorsi critici.
Se c’è un buco strutturale (una forma di discontinuità nel flusso di informazioni) in una rete, la persona che detiene la posizione di intermediazione può assumere una posizione strategica per collegare o scollegare i nodi in un gruppo, e quindi gode di un vantaggio competitivo rispetto agli altri nodi. Gli attori con un alto valore di betweeness centrality sono come dei guardiani che controllano il flusso di informazioni tra gli altri.
Generalmente i nodi aventi alta betweeness sono quelli aventi anche alta degree centrality, in quanto sono i cosiddetti hub che abbiamo descritto sopra. Questo non è però il caso in cui un nodo va a collegare due regioni del network diverse e semplicemente scollegate. In questo caso il nodo può avere pochi collegamenti con altri nodi, ma fungere da ponte tra due regioni molto distanti della rete.
Cercando di mettere insieme i pezzi, si può dire che un nodo avente una alta betweeness centrality può corrispondere a uno dei due estremi di un legame debole di Granovetter, che a sua volta garantisce a un network la proprietà di small world vista sopra.
Eigenvector Centrality
Il detto “dimmi chi sono i tuoi amici e ti dirò chi sei” si traduce nella social network analysis nella centralità dell’autovettore. Questa misura ci dà informazioni su un attore sulla base delle relazioni che ha con i suoi vicini, cioè i suoi contatti più stretti. Di nuovo Maksim Tsvetovat e Alexander Kouznetsov hanno trovato l’analogia perfetta, ovvero Don Vito Corleone. Egli infatti con le misure di centralità precedenti non si sarebbe potuto riconoscere come il boss, poiché non ha molti collegamenti diretti e non scambia molte parole in giro. Ecco quindi l’utilità dell’eigenvector centrality. Sostanzialmente si basa sull’algoritmo di Bonacich, che iterativamente calcola un peso per ciascuno dei link di un nodo basandosi su quello degli attori vicini. Può essere definita come un’estensione della degree-centrality poiché va a guardare proprio questa metrica nei vicini, ed infatti un attore con alta eigenvector centrality è connesso a nodi aventi molte connessioni a loro volta.
Pagerank
Simile alla Eigenvector Centrality in quanto si basa sullo stesso principio di calcolo dei pesi ricorsivo è il pagerank, l’algoritmo sviluppato da Larry Page come parte essenziale delle prime versioni di Google per indicizzare le pagine Web. Il PageRank è una misura di centralità che calcola il prestigio di un nodo, inteso come pagina Web. Le pagine Web sono i nodi di un grafo orientato dove i link fra nodi sono gli hyperlink alla pagina stessa (link alla pagina presenti su altre pagine web). Il grado di un nodo è calcolato come la probabilità che una persona capiti casualmente su quella pagina cliccando un link.
Questo processo è conosciuto come random walk, ed è una semplice simulazione di come l’utente naviga nel web. La pagina con il più alto indice di ranking è quindi la destinazione più probabile. Si potrebbe pensare perchè non usare direttamente la in-degree centrality allora? Il Pagerank è in questo caso molto più efficiente perché tiene conto dell’importanza della pagina da cui proviene l’hyperlink. Ovvero se la pagina target viene citata dal Wall Street Journal sarà molto più alta in ranking rispetto a una pagina citata da un sito di spam.
Conclusione
Come abbiamo visto in questo articolo la SNA è uno strumento di analisi estremamente potente ed affascinante che può essere utilizzato in concomitanza con molti altri modelli nel contesto della data science. Uno di questi è la teoria dei giochi, con la quale è possibile applicare alcune delle analisi di cui abbiamo parlato, come vedremo nei prossimi articoli.
Fonti
Albert, and Barabasi. Network Science. Cambridge University Press, 2016.
Easley, David, and Jon Kleinberg. Networks, Crowds, and Markets: Reasoning about a Highly Connected World. Cambridge University Press, 2010.
Menczer, Filippo, et al. A First Course in Network Science. Cambridge University Press, 2020.
Tsvetovat, Maksim, and Alexander Kouznetsov. Social Network Analysis for Startups. O’Reilly, 2011.
Articolo a cura di Giovanni Ceccaroni, Data Scientist in Orbyta Tech, 22.06.2021
Su questo sito utilizziamo cookie tecnici necessari alla navigazione e funzionali all’erogazione del servizio. Utilizziamo i cookie anche per fornirti un’esperienza di navigazione sempre migliore, per facilitare le interazioni con le nostre funzionalità social.
Puoi esprimere il tuo consenso cliccando su ACCETTA TUTTI.
I cookie necessari sono assolutamente essenziali per il corretto funzionamento del sito web. Questi cookie garantiscono le funzionalità di base e le caratteristiche di sicurezza del sito web, in modo anonimo.
Cookie
Durata
Descrizione
__hssrc
session
This cookie is set by Hubspot whenever it changes the session cookie. The __hssrc cookie set to 1 indicates that the user has restarted the browser, and if the cookie does not exist, it is assumed to be a new session.
cookielawinfo-checkbox-analytics
11 months
Questo cookie è impostato dal plug-in GDPR Cookie Consent. Il cookie viene utilizzato per memorizzare il consenso dell'utente per i cookie nella categoria "Analytics".
cookielawinfo-checkbox-functional
11 months
Il cookie è impostato dal consenso cookie GDPR per registrare il consenso dell'utente per i cookie nella categoria "Funzionali".
cookielawinfo-checkbox-necessary
11 months
Questo cookie è impostato dal plug-in GDPR Cookie Consent. I cookie vengono utilizzati per memorizzare il consenso dell'utente per i cookie nella categoria "Necessari".
cookielawinfo-checkbox-others
11 months
Questo cookie è impostato dal plug-in GDPR Cookie Consent. Il cookie viene utilizzato per memorizzare il consenso dell'utente per i cookie nella categoria "Altri.
cookielawinfo-checkbox-performance
11 months
Questo cookie è impostato dal plug-in GDPR Cookie Consent. Il cookie viene utilizzato per memorizzare il consenso dell'utente per i cookie nella categoria "Prestazioni".
JSESSIONID
session
Utilizzato da siti scritti in JSP. Cookie di sessione della piattaforma per scopi generici che vengono utilizzati per mantenere lo stato degli utenti attraverso le richieste di pagina.
viewed_cookie_policy
11 months
Il cookie è impostato dal plug-in GDPR Cookie Consent e viene utilizzato per memorizzare se l'utente ha acconsentito o meno all'uso dei cookie. Non memorizza alcun dato personale.
I cookie funzionali aiutano a eseguire determinate funzionalità come condividere il contenuto del sito Web su piattaforme di social media, raccogliere feedback e altre funzionalità di terze parti.
Cookie
Durata
Descrizione
__cf_bm
30 minutes
Questo cookie, impostato da Cloudflare, viene utilizzato per supportare la gestione dei bot di Cloudflare.
__hssc
30 minutes
HubSpot imposta questo cookie per tenere traccia delle sessioni e per determinare se HubSpot deve incrementare il numero di sessione e i timestamp nel cookie __hstc.
bcookie
2 years
LinkedIn imposta questo cookie dai pulsanti di condivisione di LinkedIn e aggiunge tag per riconoscere l'ID del browser.
lang
session
Questo cookie viene utilizzato per memorizzare le preferenze di lingua di un utente per fornire contenuti in quella lingua memorizzata la prossima volta che l'utente visita il sito web.
lidc
1 day
LinkedIn imposta il cookie lidc per facilitare la selezione del data center.
I cookie per le prestazioni vengono utilizzati per comprendere e analizzare gli indici di prestazioni chiave del sito Web che aiutano a fornire una migliore esperienza utente per i visitatori.
I cookie analitici vengono utilizzati per capire come i visitatori interagiscono con il sito web. Questi cookie aiutano a fornire informazioni sulle metriche del numero di visitatori, della frequenza di rimbalzo, della sorgente del traffico, ecc.
Cookie
Durata
Descrizione
__hstc
1 year 24 days
This is the main cookie set by Hubspot, for tracking visitors. It contains the domain, initial timestamp (first visit), last timestamp (last visit), current timestamp (this visit), and session number (increments for each subsequent session).
_ga
2 years
Il cookie _ga, installato da Google Analytics, calcola i dati di visitatori, sessioni e campagne e tiene anche traccia dell'utilizzo del sito per il report di analisi del sito. Il cookie memorizza le informazioni in modo anonimo e assegna un numero generato casualmente per riconoscere i visitatori unici.
_gat_gtag_UA_162571803_1
1 minute
This cookie is set by Google and is used to distinguish users.
_gid
1 day
Installato da Google Analytics, il cookie _gid memorizza informazioni su come i visitatori utilizzano un sito web, creando anche un report analitico delle prestazioni del sito web. Alcuni dei dati raccolti includono il numero di visitatori, la loro fonte e le pagine che visitano in modo anonimo.
CONSENT
16 years 3 months 10 days 7 hours 5 minutes
Questi cookie vengono impostati tramite video di YouTube incorporati. Registrano dati statistici anonimi su ad esempio quante volte viene visualizzato il video e quali impostazioni vengono utilizzate per la riproduzione. Nessun dato sensibile viene raccolto a meno che non accedi al tuo account google, in tal caso le tue scelte sono legate al tuo account, ad esempio se fai clic su "mi piace" su un video.
hubspotutk
1 year 24 days
Questo cookie viene utilizzato da HubSpot per tenere traccia dei visitatori del sito web. Questo cookie viene passato a Hubspot all'invio del modulo e utilizzato durante la deduplicazione dei contatti.
I cookie pubblicitari vengono utilizzati per fornire ai visitatori annunci e campagne di marketing pertinenti. Questi cookie tengono traccia dei visitatori sui siti Web e raccolgono informazioni per fornire annunci personalizzati.
Cookie
Durata
Descrizione
bscookie
2 years
Questo cookie è un cookie ID del browser impostato dai pulsanti di condivisione collegati e dai tag degli annunci.
IDE
1 year 24 days
I cookie di Google DoubleClick IDE vengono utilizzati per memorizzare informazioni su come l'utente utilizza il sito Web per presentargli annunci pertinenti e in base al profilo dell'utente.
test_cookie
15 minutes
Il test_cookie è impostato da doubleclick.net e viene utilizzato per determinare se il browser dell'utente supporta i cookie.
VISITOR_INFO1_LIVE
5 months 27 days
Un cookie impostato da YouTube per misurare la larghezza di banda che determina se l'utente ottiene la nuova o la vecchia interfaccia del lettore.
YSC
session
Il cookie YSC è impostato da Youtube e viene utilizzato per tenere traccia delle visualizzazioni dei video incorporati nelle pagine di Youtube.
yt-remote-connected-devices
never
YouTube imposta questo cookie per memorizzare le preferenze video dell'utente utilizzando il video YouTube incorporato.
yt-remote-device-id
never
YouTube imposta questo cookie per memorizzare le preferenze video dell'utente utilizzando il video YouTube incorporato.
yt.innertube::nextId
never
Questi cookie vengono impostati tramite video di YouTube incorporati.
yt.innertube::requests
never
These cookies are set via embedded youtube-videos.