Introduci la tua esperienza professionale dall’università fino all’ingresso in ORBYTA
Sono sempre stata affascinata dagli aspetti più teorici della matematica e desiderosa di applicarli in contesti pratici, la scelta di studiare Ingegneria Matematica al Politecnico di Torino è stata quindi naturale. Dopo la triennale ho iniziato un percorso come full stack Java developer in una piccola azienda e durante questo periodo ho capito che anche l’informatica mi piaceva molto. Attirata da Orbyta, perchè molto aperta all’innovazione e al dare spazio ai giovani, ho deciso di propormi per la candidatura ed è stata un’ottima decisione! Mi è stata subito data la possibilità di lavorare in contesti sfidanti in ambito Analytics e ho avuto modo di completare i miei studi magistrali con una tesi sulla topologia algebrica computazionale in cui ho potuto unire ciò che ho imparato dai miei colleghi con ciò che ho appreso dai miei professori.
Di cosa ti occupi e che valore porti all’azienda?
Sono da poco diventata Head dell’Analytics, area in cui ci occupiamo di Machine Learning, Artificial Intelligence, Data Mining, Business Intelligence e processi ETL di diverso genere. Ci teniamo continuamente aggiornati sulle ultime metodologie portando avanti, oltre a diversi progetti aziendali, anche progetti di ricerca e sviluppo sfidanti come LIS2Speech. Penso che la passione e la costante voglia di migliorare le competenze mie e del mio Team siano stati molto importanti per i progetti in cui abbiamo lavorato. D’altro canto è fondamentale per me costruire un ambiente di lavoro sereno e supportare i più giovani in modo che possano diventare degli ottimi data scientists.
Perché ti piace lavorare in ORBYTA?
Perchè stimo le persone con cui lavoro: l’ambiente è davvero costruttivo e mi dà la possibilità di sviluppare ogni volta qualcosa di nuovo, oltre che di conoscere molti clienti. Inoltre il lavoro che faccio è la mia passione e dai miei colleghi ho imparato moltissimo in questi anni.
AI: bias, esempi nella realtà e nella cinematografia
È difficile poter dare una definizione univoca di cosa sia un’intelligenza artificiale (IA). Descrizioni diverse possono essere date focalizzandosi o sui processi interni di ragionamento o sul comportamento esterno del sistema intelligente e utilizzando come misura di efficacia o la somiglianza con il comportamento umano o con un comportamento ideale.
A seconda dei diversi punti di vista un’IA è quel sistema in grado di
Agire umanamente: il risultato dell’operazione compiuta dal sistema intelligente non è distinguibile da quella svolta da un umano.
oppure
Pensare umanamente: il processo che porta il sistema intelligente a risolvere un problema ricalca quello umano.
oppure
Pensare razionalmente: il processo che porta il sistema intelligente a risolvere un problema è un procedimento formale che si rifà alla logica.
oppure
Agire razionalmente: il processo che porta il sistema intelligente a risolvere il problema è quello che gli permette di ottenere il miglior risultato atteso date le informazioni a disposizione.
Questo sistema potenzialmente può “apprendere” come svolgere i compiti a lui assegnati in modo simile ai bambini, ovvero tramite l’osservazione di uno o più schemi ed esempi.
L’apprendimento automatico (o machine learning, ML) è la disciplina che studia algoritmi capaci di migliorare automaticamente le proprie performance attraverso l’esperienza. È stato un ambito di ricerca cruciale all’interno dell’IA sin dalla sua nascita. Il ML è particolarmente importante per lo sviluppo di sistemi intelligenti principalmente per tre motivi:
Gli sviluppatori di un sistema intelligente difficilmente possono prevedere tutte le possibili situazioni in cui il sistema stesso si può trovare a operare, eccetto per contesti estremamente semplici.
Gli sviluppatori di un sistema intelligente difficilmente possono prevedere tutti i possibili cambiamenti dell’ambiente nel tempo.
Un’ampia categoria di problemi può essere risolta più efficacemente ricorrendo a soluzioni che coinvolgono l’apprendimento automatico. Questa categoria di problemi include, ad esempio, il gioco degli scacchi e il riconoscimento degli oggetti.
Le applicazioni di IA possono essere molteplici e riguardare diversi ambiti, da quello industriale a quello domestico. Possiamo affermare che l’età d’oro per le IA sia appena iniziata, ma il percorso non è privo di sfide. Sebbene lo scopo generale delle IA sia quello di risolvere i problemi può anche creare nuove sfide, come per esempio l’analisi dei bias, argomento delicato e spesso sottovalutato negli anni passati.
D’altro canto, non è un segreto che l’IA sia uno dei temi più trattati nei film, da robot propri di futuri distopici ad assistenti virtuali super efficienti. Per questo la cinematografia può essere una buona fonte di esempi per comprendere meglio questa tecnologia.
E se il loro “cervello” fosse più potente del nostro?
Nel 2017 due bot attivati da Facebook, Alice e Bob, furono improvvisamente spenti perché iniziarono a parlare e comprendersi in una lingua all’apparenza a noi sconosciuta. I due bot sono stati messi uno davanti all’altro per portare a termine uno scenario di collaborazione ipotetico: la suddivisione di alcuni oggetti da portare a termine con una contrattazione uno contro uno.
Nel corso dell’esperimento il dialogo è avanzato in inglese fino al momento in cui i due bot non hanno iniziato a basare i propri scambi su una lingua deforme, non più normata dalle regole sintattiche che conosciamo e dunque più vicina a un idioma ignoto. Ciò è avvenuto per un errore di programmazione da parte dei ricercatori che, anziché costringere i bot a mantenersi nei binari di un inglese comprensibile dagli umani, si sono limitati a implementare questa istruzione come una strategia di comunicazione preferibile ma facoltativa.
I bot sono stati così lasciati liberi di ispirarsi uno all’altro, trovando più semplice e meno ambiguo deviare dal lessico e dalla sintassi umani per iniziare a ripiegare su un’alternativa più efficiente.
Questo episodio ha agitato non poco la Rete, con tanto di cospirazioni e teorie. infatti, dopo questo incidente, ci sono state diverse ipotesi complottistiche, la più gettonata riguarda V.I.K.I., l’IA che nel film Io,Robot (2005) prende il controllo sulle altre IA per concretizzare un progetto formulato autonomamente.
V.I.K.I. (Virtual Interactive Kinetic Intelligence) nasce come un supercomputer basato sull’IA in grado di preoccuparsi della sicurezza dell’uomo; nel film lo vediamo già evoluto dopo anni di attività insieme alla sua interpretazione delle tre leggi della robotica. L’obiettivo dei robot è sempre quello di proteggere gli umani; tuttavia, per fare questo, i robot devono proteggere gli umani da loro stessi, sacrificando quindi i singoli e la loro libertà avviando una vera schiavizzazione del genere umano. Tra i più fantasiosi hanno visto in Alice e Bob un’attitudine simile a quella di V.I.K.I., ma i ricercatori non li hanno spenti perché andati nel panico, ma semplicemente perché non hanno dato loro le giuste regole.
Vieni qui bello!
Nel 2019 un robo-dog Spot di Boston Robotics ha subito una drammatica morte sul palco durante la dimostrazione dal vivo del CEO dell’azienda Marc Raibert a re: MARS 2019 a Las Vegas. Il robot durante la presentazione doveva camminare ma le sue gambe sembravano cedere per poi inciampare e crollare al pavimento dinanzi al pubblico incredulo.
Sono proprio i robo-dog a diventare i protagonisti di una puntata della serie di Black Mirror, Metalhead (2018), ove i robo-dogs sono realtà da più di un decennio e le loro abilità vengono affinate ogni anno di più per scopi militari. Tutta la struttura dell’episodio, impostato come un survival horror, si regge sull’impossibilità da parte degli umani di far fronte alla spietata efficienza dei cani robot.
Contrariamente alla credenza popolare, i robot di Boston Dynamics non sono alimentati dall’intelligenza artificiale: molti dei loro comandi meccanici, sebbene estremamente sofisticati per i moderni standard robotici, devono essere avviati e guidati da operatori umani. Inoltre, il lancio precoce di Spot è un’ulteriore prova che questi robot sono lontani dal conquistare il mondo… e che il testing di tecnologie simili è una fase cruciale su cui la ricerca è ancora attivamente aperta.
Assistenza non pervenuta
Nel 2018 il robot LG Cloi ha ripetutamente fallito sul palco al suo debutto al CES, lo scopo era quello di dimostrare come l’IA possa migliorare l’uso degli elettrodomestici da cucina. Inizialmente Cloi si è comportato come previsto ma la gloria è durata poco poiché le richieste successive, come scoprire se il suo bucato era pronto, cosa era previsto per la cena e quali ricette potrebbe suggerire per il pollo, non hanno ricevuto nessun tipo di riposta. L’obiettivo di LG doveva essere quello di promuovere ThinQ, il suo software AI interno, che intende distribuire su vari prodotti per renderli più facili da usare e in grado di “evolversi” per soddisfare le esigenze dei clienti.
Questa volta è andata male ma ci sono tutti i presupposti per avere, in un futuro non troppo lontano, un assistente virtuale efficiente ed è ciò che viene rappresentato nel film Her (2013). In questo film gli assistenti virtuali sono integrati nelle attività quotidiane di tutti, ma il loro ruolo va ben oltre. Il protagonista intreccia infatti una relazione di amicizia con il sistema operativo OS 1, al quale dà una voce femminile e un nome, Samantha. Il rapporto tra i due diventa molto profondo, grazie alle capacità di ascolto del sistema, che sembra davvero comprendere paure, ansie e felicità che il protagonista le confida. Samantha apprende e si arricchisce da ogni interazione con il “suo umano”, tanto da instaurare con lui una relazione amorosa. Per ora le tecnologie legate alla comprensione del linguaggio, alla percezione del contesto e al ragionamento hanno fatto enormi passi in avanti ma siamo ancora lontani da una possibile Samantha.
Si pensi infatti che il nostro cervello è incredibilmente potente e attualmente lontano dalla portata delle macchine, infatti pur pesando in media poco più di un chilo, conta circa 86 miliardi di neuroni collegati tra loro da trilioni di sinapsi e 85 miliardi di cellule non neuronali. Un titano anche a confronto con i supercomputer più potenti del mondo. Come esempio si consideri che nel 2015, alcuni studiosi hanno simulato l’equivalente dell’1% dell’attività cerebrale umana di un secondo utilizzando più di 700 mila core del quarto super-computer più potente al mondo, il K computer. Quel secondo è costato 40 minuti di elaborazione. Un altro esempio è dato dal progetto Human brain project che si basa sul Blue Gene della IBM, uno tra i super-computer più veloci al mondo. Henry Markram, coordinatore del progetto e professore dell’ÉPFL, ha affermato che per dar vita a una simulazione in scala reale del cervello ci vorrà un computer centomila volte più veloce di un petascale.
Attenzione ai bias!
Un algoritmo testato come strumento di reclutamento dal gigante online Amazon ha concluso che i candidati maschi erano preferibili a quelli di sesso femminile. Nel 2015 era chiaro che il sistema non valutava i candidati in modo neutrale rispetto al genere perché era basato sui dati ricavati dai CV inviati all’azienda principalmente da uomini, per questo il sistema ha iniziato a penalizzare i CV che includevano la parola “donna”.
Non è la prima volta che vengono sollevati dubbi su quanto affidabili sono gli algoritmi addestrati su dati potenzialmente distorti. È infatti fondamentale controllare, tra le tante cose, che i dati utilizzati siano correttamente bilanciati.
Un altro esempio viene fornito da Instagram. Uno studio condotto nel 2020 ha portato alla luce che l’algoritmo di Instagram preferisce infatti mostrare donne svestite molto più spesso di quanto non faccia con gli uomini. I risultati della ricerca hanno riportato che se la foto ritraeva una donna nuda (o pochissimo vestita) c’era una possibilità su due che l’algoritmo la facesse apparire nel feed; se il soggetto era un uomo nudo, invece, ci sarebbe stata una possibilità su tre.
Una delle ipotesi formulata nei report è che il comportamento sia dovuto a un bias dell’algoritmo generato dal fatto che il mondo della computer vision è a prevalenza maschile e ciò potrebbe riprodurre negli strumenti di ottimizzazione dei feed una visione sessista.
Come non parlare del film Ex Machina (2015) in questa rubrica che è forse quello che fino ad oggi è riuscito a meglio rappresentare l’IA nella sua ampiezza di significato, toccando non solo la componente robotica e quella di autoapprendimento dei sistemi fino alla coscienza di sé, ma anche sfiorando nella trama alcuni degli ambiti applicativi già oggi presenti nelle nostre vite (internet, i motori di ricerca e i social network, chatbot ed assistenti virtuali, realtà virtuale e aumentata).
Ava è un umanoide dotata di IA e il protagonista umano Caleb, ultimo dei dipendenti della grande azienda che ha implementato Ava, deve capire se davvero la si possa definire un’intelligenza artificiale. A fare la differenza rispetto ad altre compagnie è il fatto che questa possiede un motore di ricerca, uno così usato e potente da aver accesso a tutto ciò che è disponibile in rete.
Ava è descritta quindi come la prima vera intelligenza artificiale perché attinge a quel bacino immenso di conoscenza che condividiamo ogni giorno. Nutrendosi di spazzatura e di informazioni rilevanti, di foto di gatti al pari di pubblicazioni scientifiche, Ava impara tutto, anche ad aver sete di sentimenti, fino a risultare un creato dell’intelligenza collettiva degli utenti della rete. Probabilmente Ava se avesse avuto un dataset scelto e delimitato non sarebbe risultata così “umana” e sensibile; un po’ come l’IA per la selezione dei CV di Amazon che se avesse avuto più controllo sulla raccolta dei dati forse non sarebbe risultata sessista.
Cos’è un bias?
Il bias di apprendimento automatico è un fenomeno che si verifica quando un algoritmo produce risultati che sono sistematicamente pregiudicati a causa di presupposti errati nel processo di apprendimento automatico. Un bias elevato può far sì che un algoritmo non rilevi le relazioni rilevanti tra le caratteristiche e gli output target.
È molto facile cadere nei bias quando si parla di sistemi di apprendimento automatico se non c’è un adeguato controllo nei dati utilizzati per addestrare i modelli di apprendimento.
C’è da aggiungere anche che i pregiudizi possono insinuarsi molto prima che i dati vengano raccolti, così come in molte altre fasi del processo di apprendimento profondo. Per capire meglio i bias ci concentreremo su tre frasi chiave: inquadrare il problema, raccolta dei dati e preparazione dei dati.
Inquadrare il problema: la prima cosa da fare quando si crea un modello di apprendimento profondo è decidere cosa si vuole effettivamente ottenere. Una società di carte di credito, ad esempio, potrebbe voler prevedere l’affidabilità creditizia di un cliente, ma “affidabilità creditizia” è un concetto piuttosto nebuloso. Per tradurlo in qualcosa che possa essere calcolato, l’azienda deve decidere se vuole, ad esempio, massimizzare i suoi margini di profitto o massimizzare il numero di prestiti che vengono rimborsati. Potrebbe quindi definire l’affidabilità creditizia nel contesto di tale obiettivo.
Raccolta dei dati. Ci sono due modi principali in cui i bias si manifestano nei dati di addestramento: o i dati raccolti non sono rappresentativi della realtà o riflettono i pregiudizi esistenti. Il primo caso potrebbe verificarsi, ad esempio, se un algoritmo di apprendimento profondo riceve più foto di volti dalla pelle chiara che volti dalla pelle scura. Il sistema di riconoscimento facciale risultante sarebbe inevitabilmente peggiore nel riconoscere i volti dalla pelle più scura. Questo caso è simile rispetto a quello che vi abbiamo raccontato incontrato da Amazon quando ha scoperto che il suo strumento di reclutamento interno stava favorendo gli uomini . Poiché è stato formato su decisioni storiche e sociologiche di assunzione, che hanno favorito gli uomini rispetto alle donne, l’IA ha imparato a fare lo stesso.
Preparazione dei dati. è possibile introdurre bias anche durante la fase di preparazione dei dati, che implica la selezione degli attributi che si desidera vengano presi in considerazione dall’algoritmo. Ciò non deve essere confuso con la fase di definizione del problema. Si possono utilizzare gli stessi attributi per addestrare un modello per obiettivi molto diversi o utilizzare attributi molto diversi per addestrare un modello per lo stesso obiettivo. Nel caso della modellazione del merito di credito, un attributo potrebbe essere l’età, il reddito o il numero di prestiti rimborsati del cliente. Nel caso dello strumento di reclutamento di Amazon, un attributo potrebbe essere il sesso, il livello di istruzione o gli anni di esperienza del candidato. Questo è ciò che i data scientist chiamano l‘arte del deep learning, ovvero scegliere quali attributi considerare o ignorare può influenzare in modo significativo l’accuratezza della previsione del modello.
Nonostante la rapida crescita dell’IA e i notevoli risultati raggiunti, le sfide finora incontrate sono un chiaro segnale che c’è ancora molto da studiare e da scoprire.
Articolo a cura di Lucia Campomaggiore, data analyst, e Carla Federica Melia, data scientist, 01.12.2020
Fabio Aquila – CEO Compliance e Engineering
Introduci la tua carriera professionale fino al ruolo da CEO.
A seguito del conseguimento della Laurea specialistica in ingegneria meccanica nel 2011, ho iniziato la mia carriera lavorativa in una importante realtà nel campo del machine tool, dove mi sono occupato di progettazione di linee industriali, soprattutto in ambito automotive. È stata un’esperienza intensa che mi ha consentito di comprendere bene il funzionamento dei processi organizzativi e produttivi, e allo stesso tempo mi ha fatto riflettere su molte sfaccettature legate ad aspetti di carattere manageriale e di gestione del personale, è stato lì che ho iniziato a pensare a come sarebbe stata l’azienda guidata da me.
Dopo aver rassegnato le dimissioni, a fine 2012 ho vinto un bando come assegnista di ricerca presso il Dipartimento di Ingegneria Meccanica e Aerospaziale del Politecnico di Torino, un’esperienza elettrizzante. Per due anni ho avuto modo di sfogare la mia indole da ingegnere meccanico progettando, all’interno di un Team altamente qualificato, prototipi innovativi per la conversione di energia da fonti rinnovabili offshore, come le onde del mare (wave energy) o l’eolico galleggiante.
Tuttavia, mancava qualcosa, ed a marzo 2013 ho aperto la mia prima partita iva, iniziando a propormi nelle aziende come consulente industriale ed eseguendo in parallelo il lavoro di ricerca al Politecnico. Svolgere due lavori contemporaneamente non è stato semplice: sono state tante le notti insonni per portare a compimento i miei progetti, tanto che nel 2014 mi trovo a dover rinunciare al mio assegno di ricerca per dedicarmi anima e corpo alla mia attività da consulente.
Da qui in poi i volumi di crescita anno dopo anno sono molto incoraggianti, ed è proprio in virtù dei risultati raggiunti che diventa strategico costituire una società di capitali, così nel 2017 fondo, insieme a Daniela, la mia società di consulenza; proprio quella che oggi si chiama ORBYTA COMPLIANCE. Il 2018 è ancora un anno di successi e i risultati conseguiti catturano l’attenzione di Lorenzo, CEO di ORBYTA, con cui è nato un bellissimo rapporto di fiducia, mentoring e contaminazione culturale (e se posso dire anche una grande amicizia). I valori che ho trovato nella visione di Lorenzo vibravano unisono con i miei ed ho colto al volo l’occasione di affiancarlo nella realizzazione del progetto ORBYTA in qualità senior partner.
Il 2020 è stato un anno ricco di soddisfazioni, in cui tra i vari progetti che abbiamo varato, ha preso forma ORBYTA ENGINEERING, società di ingegneria che ho l’onore di seguire come CEO e per la quale nutro grandi aspettative. Sono sicuro che il futuro ci riserva grandi cose.
Qual è la strategia per guidare con successo il team?
C’è una grandissima responsabilità dietro il lavoro di un team leader, che attenzione, non è solo di carattere lavorativo, e non si misura con numeri risultati e obiettivi.
Dal momento che passiamo la maggior parte della nostra vita al lavoro, è inevitabile che la vita privata ne sia condizionata. Va da sé che quello che succede in azienda genera i suoi effetti in famiglia, con gli amici e gli affetti in generale. Alla luce di questo, elenco quelle che sono per me le caratteristiche fondamentali di un bravo leader:
Un team leader è prima di tutto un coach, che allena la sua squadra costantemente, la forma, le fornisce gli strumenti adeguati per poter giocare il campionato ai massimi livelli.
Come ogni coach è prima di tutto un giocatore, e sa cosa significa giocare una partita, lavorare duro sul campo. Ne va della sua accountability e della sua autorevolezza.
Un team leader ha dei principi etici precisi, li diffonde e li condivide con la squadra, è disposto a mettersi in discussione, ad ascoltare, sa cambiare idea e chiedere scusa.
È sempre presente, ma sa delegare e avere fiducia nei membri del suo team, consente loro di crescere, cosicché possano diventare degli allenatori a loro volta.
Se dovessi dare un consiglio a chi aspira ad un ruolo come il tuo, quale sarebbe?
Il mio consiglio è quello di percorrere la strada dal basso verso l’alto, partendo da zero. Così facendo si ha modo di vivere ogni sfaccettatura della crescita, imparando sulla base della propria esperienza diretta. Ritengo che sia il modo migliore.
Per fare ciò è inevitabile prendersi dei rischi, non dirò che non bisogna avere paura, perché effettivamente io ne ho avuta tanta, ma serve di sicuro il coraggio di gettare il cuore oltre l’ostacolo. È un concetto banale, ma in effetti è impossibile manifestare coraggio se non provi paura.
Su questo ho anche sviluppato una teoria che condivido volentieri. La prima cosa da fare è chiedersi perché lo vuoi, qual è la motivazione, la spinta emotiva che ti guida a perseguire la tua aspirazione.
Cominci dal tuo sogno, è quello che ti fa sentire bene al solo pensiero, che fa vibrare le tue corde. Poi inizi a definire cosa ti serve per realizzare quel sogno e cominci ad impacchettare degli obiettivi, quelli sono un po’ più duri, perché sono misurabili ed hanno una scadenza temporale. Infine, giorno per giorno prepari i tuoi compiti che sono quelli necessari a perseguire l’obiettivo, si tratta di azioni precise, per cui puoi scrivere delle istruzioni e sono anche delegabili.
Quindi un sogno è la sommatoria di tanti compiti che fanno la sommatoria di tanti obiettivi.
In qualità di partner del Gruppo, come pensi di contribuire al progetto ORBYTA?
Sinergia e lavoro di squadra sono aspetti cardine in un gruppo come il nostro. Lavoro ogni giorno con lo staff, i partner e con il mio team per cercare nuove idee, modelli e progetti che possano portare ORBYTA davvero molto lontano nel futuro, è questo il mio sogno, far diventare ORBYTA un player ai massimi livelli, così che i valori e i principi etici che portiamo avanti possano essere fonte d’ispirazione per tante altre persone dentro e fuori il gruppo.
Quali sono i piani di crescita pensati per il futuro di ORBYTA Compliance e Engineering?
Compliance ed Engineering sono due società complementari, e la crescita e lo sviluppo di una non può che essere il successo dell’altra. In particolare, Compliance oggi si posiziona a un ottimo livello rispetto alla media dei player del settore, tuttavia il suo andamento dipende ancora molto dal mio operato diretto. Il piano per prossimi anni è quello di rendere lo sviluppo e la crescita di Compliance sempre meno dipendente dal mio operato, in modo che possa essere guidata dai coach del futuro. È un processo già in atto, che stiamo portando avanti sia a livello organizzativo (con una digitalizzazione capillare a tutti i livelli, per cui devo ringraziare i ragazzi di ORBYTA TECH con cui sto lavorando molto bene), sia a livello qualitativo, investendo su persone che manifestano un elevato potenziale. Nel frattempo, la nuova nata Engineering dovrà proseguire con il suo processo di crescita e percorrere la medesima strada, per consentirmi dopo di dedicarmi ad altri obiettivi e compiti che portino al sogno di cui parlavo prima, far diventare ORBYTA un punto di riferimento per gli altri, un sogno condiviso.
Introduci la tua esperienza professionale dall’università fino all’ingresso in Orbyta
Il mio percorso comincia con la laurea in Informatica all’Università di Torino, dove, per il progetto di tesi, ho potuto muovere i primi passi nel mondo IT in una piccola software house. Qui sono stato coinvolto in un progetto per la realizzazione di un’applicazione per il controllo accessi dell’azienda, utilizzando la tecnologia RFID. Successivamente ho lavorato in un’azienda di consulenza informatica e contemporaneamente ho conseguito un master sul Cloud Computing. Dopo circa tre anni ho deciso di cambiare realtà e così sono entrato finalmente a far parte di ORBYTA!
Di cosa ti occupi e che valore porti all’azienda?
Lavoro in consulenza presso Deltatre, dove ho l’opportunità di sviluppare siti web riguardanti il mondo dello sport, in particolare nell’ambito delle Olimpiadi: quelle di Rio 2016 rappresentano sicuramente un’esperienza da ricordare!
Mi sono specializzato soprattutto sulle tecnologie Microsoft, quali .NET, C# e Azure, mentre per la parte di front-end uso principalmente React. I valori aggiunti che porto all’interno della mia azienda sono la voglia di migliorarmi costantemente e la condivisione delle mie conoscenze: tengo ogni anno dei seminari aperti a tutti i dipendenti ORBYTA su queste tecnologie, così da poter dare il mio contributo al Gruppo.
Perché ti piace lavorare in Orbyta?
ORBYTA rappresenta una realtà giovane e in evoluzione, nella quale siamo costantemente seguiti nel nostro percorso di crescita professionale, grazie alle numerose iniziative aziendali, quali corsi, seminari e certificazioni. E non mancano di certo gli eventi aziendali, in cui si ha la possibilità di fare team building conoscendo tutti gli altri Orbyters.
Lorenzo Sacco – CEO Orbyta
Introduci la tua carriera professionale fino al ruolo da CEO.
Ho conseguito la laurea specialistica in Ingegneria
delle telecomunicazioni nel 2005 con il massimo dei voti.
Ho iniziato subito a lavorare nell’ICT come analista
programmatore in realtà multinazionali di consulenza dove ho sviluppato
competenze e relazioni su Clienti importanti nei settori fintech, insurance,
telco e automotive. Sono stato inoltre dipendente FIAT, prima della fusione con
Chrysler, dove ho potuto vivere le dinamiche lato cliente.
Fin dall’università avevo il desiderio di costruire
una realtà mia e così nel 2011, a 30 anni, dopo 6 anni di esperienza, un
bagaglio di competenze e relazioni, ho deciso di lanciarmi in una nuova sfida
imprenditoriale fondando la startup EIS.
L’idea dietro ed EIS era quella di essere una
società di consulenza dove le persone fossero al centro, dove ciascuno potesse
trovare un terreno fertile per far crescere il proprio potenziale e sentirsi
parte dell’azienda.
Mi sono dedicato anima e corpo al progetto,
lavorando duramente e seguendo tutti gli aspetti della società: l’area tecnica,
le risorse umane, l’area amministrativa e finanziaria. Il mio socio,
anagraficamente più senior di me, si è occupato inizialmente dello sviluppo
commerciale.
In pochi anni EIS è
cresciuta in modo esponenziale, nel 2015 siamo stati premiati dalla Deloitte
come prima startup tecnologica per crescita di fatturato in Italia nella
classifica EMEA TECHNOLOGY FAST 500. Nel 2016 siamo diventati un gruppo,
EISWORLD, formato da società specializzate ed io ricoprivo il ruolo di CEO
nelle principali.
Nel 2019 il gruppo EISWORLD viene sciolto, ma restano la passione per il mio lavoro e l’entusiasmo del mio staff. Così a febbraio 2020 nasce il gruppo ORBYTA, fondata sui valori in cui credo e che mi tengono unito alle persone che con me condividono questa avventura. Come fondatore e CEO, mi pongo come obiettivo quello di mettere la mia esperienza e le mie competenze al servizio del gruppo per far diventare ORBYTA un punto di riferimento tra le società di servizi.
Qual è stata la tua più grande delusione nella carriera? Cos’hai imparato da questo?
Delusione è una parola che non uso, è un sentimento
che non mi appartiene. Ho imparato a far le mie valutazioni sul lungo periodo
e, analizzando la mia carriera, posso parlare di cambiamenti, non di delusioni.
Cambiamenti anche difficili da affrontare, come la scissione del gruppo
EISWORLD, ma inevitabili e necessari, che si sono poi rivelati essere
fondamentali per la riuscita dei progetti futuri.
Sicuramente da questo ho imparato ad essere più risoluto, ho imparato che un leader deve avere il coraggio di fare la scelta giusta, soprattutto quando non è facile ed è la scelta che in pochi farebbero. Ho imparato che bisogna credere fortemente nella propria visione per vederla realizzata, senza compromessi.
Che cosa significa innovazione per ORBYTA e in che modo la realizzi?
ORBYTA è una società di servizi, consulenza e progettazione in ambito ICT, ma non solo. Si differenzia perché mette al centro le persone, valorizza la partecipazione ed il coinvolgimento. In ORBYTA si cresce insieme con entusiasmo, il merito viene riconosciuto. Vogliamo essere la società del fare, delle competenze, della qualità, la società che sorprende il cliente portando sempre valore aggiunto. Per fare questo abbiamo costruito un modello culturale nuovo, dirompente, che ci impegniamo a diffondere in azienda e tutto intorno a noi.
Quali principali minacce/opportunità prevedi nel tuo settore? Come pensi di gestirli?
Una grande sfida per le aziende che crescono molto rapidamente, come stiamo facendo noi, è il saper mantenere la capacità di adattarsi al mercato, di trasformarsi per cogliere le differenti opportunità. In ORBYTA crediamo molto nella formazione continua, nella competenza vera. Non sappiamo cosa ci aspetta nel futuro, ma ci prepariamo ogni giorno per affrontarlo.
Come costruisci i rapporti con il team di gestione? Che ruolo giocano gli altri nell’attuazione delle tue strategie?
Una cosa che dico spesso è che i risultati che riusciamo ad ottenere dipendono da tutto il team. Tutti sono importanti, fondamentali, per la realizzazione del progetto ORBYTA. E ciascuno deve essere consapevole della propria importanza, del contributo che porta per la crescita del gruppo. Costruisco i rapporti con le persone basandoli sulla fiducia, voglio che i miei collaboratori siano liberi di esprimersi, di sbagliare, di portare le proprie idee, di sentirsi protagonisti e guida del cambiamento. Li stimolo affinché ciascuno di loro possa esprimere a pieno il proprio potenziale, che vuol anche dire aiutarli a scoprire le proprie capacità e superare i limiti che credono di avere.
COVID-19: COME MI COMPORTO SE…?
Sono stato al ristorante con una persona che si allena con un’amica risultata positiva al virus. Devo mettermi in quarantena?
Un collega degli uffici accanto è risultato positivo al virus. Devo stare a casa anch’io?
Un compagno di classe di mio figlio è risultato positivo al virus. Posso continuare ad andare a lavorare?
In questi casi la quarantena potrebbe non essere necessaria perché…
La quarantena (e successivamente il tampone) è prevista soltanto se ho avuto un contatto stretto con una persona positiva.
Cos’è un contatto stretto?
una persona che vive nella stessa casa di un caso di COVID-19;
una persona che ha avuto un contatto fisico diretto con un caso di COVID-19 (per esempio la stretta di mano); ▪ una persona che ha avuto un contatto diretto non protetto con le secrezioni di un caso di COVID-19 (ad esempio toccare a mani nude fazzoletti di carta usati);
una persona che ha avuto un contatto diretto (senza mascherina) con un caso di COVID-19, a distanza minore di 2 metri e di durata maggiore a 15 minuti;
una persona che si è trovata in un ambiente chiuso (ad esempio aula, sala riunioni, sala d’attesa dell’ospedale) con un caso di COVID-19 per almeno 15 minuti, a distanza minore di 2 metri senza indossare la mascherina ▪ un operatore sanitario o altra persona che fornisce assistenza diretta ad un caso di COVID-19 oppure personale di laboratorio addetto alla manipolazione di campioni di un caso di COVID-19 senza l’impiego dei DPI raccomandati o mediante l’utilizzo di DPI non idonei;
una persona che ha viaggiato seduta in treno, aereo o altro mezzo di trasporto entro due posti in qualsiasi direzione rispetto a un caso COVID-19; sono contatti stretti anche i compagni di viaggio e il personale addetto alla sezione dell’aereo/treno dove il caso indice era seduto (qualora il caso indice abbia una sintomatologia grave o abbia effettuato spostamenti all’interno del mezzo, determinando una maggiore esposizione dei passeggeri, considerare come contatti stretti tutti i passeggeri seduti nella stessa sezione del mezzo o in tutto il mezzo).
Cosa faccio se ho dei sintomi compatibili con il COVID-19?
Rimango a casa. Avviso il Datore di Lavoro e contatto il mio medico curante per avere indicazioni su come procedere. In presenza di sintomatologia sospetta, il medico di medicina generale (MMG), richiede tempestivamente il test diagnostico e lo comunica al Dipartimento di Prevenzione (DdP), o al servizio preposto sulla base dell’organizzazione regionale.
Quali sono i sintomi compatibili?
febbre ≥ 37,5°C e brividi
tosse di recente comparsa
difficoltà respiratorie
perdita improvvisa dell’olfatto (anosmia) o diminuzione dell’olfatto (iposmia), perdita del gusto (ageusia) o alterazione del gusto (disgeusia)
raffreddore o naso che cola
mal di gola
diarrea (soprattutto nei bambini).
Ho avuto un contatto stretto con una persona risultata positiva al SARS-CoV-2. Cosa devo fare?
Mi metto in quarantena, avviso il Datore di Lavoro e il mio medico curante, seguendo le sue indicazioni. I contatti stretti di casi con infezione da SARS-CoV-2, confermati e identificati dalle autorità sanitarie, potranno effettuare un test antigenico o molecolare al decimo giorno di quarantena (oppure osservare un periodo di quarantena di 14 giorni dall’ultima esposizione al caso).
Cosa si intende per quarantena, sorveglianza attiva ed isolamento? Quali sono le differenze?
In tutti e tre i casi non è consentito uscire di casa, ma con le seguenti differenze:
La quarantena si attua ad una persona sana (contatto stretto) che è stata esposta ad un caso COVID-19, con l’obiettivo di monitorare i sintomi e assicurare l’identificazione precoce dei casi.
L’isolamento consiste nel separare quanto più possibile le persone affette da COVID-19 da quelle sane al fine di prevenire la diffusione dell’infezione, durante il periodo di trasmissibilità.
La sorveglianza attiva è una misura durante la quale l’operatore di sanità pubblica provvede a contattare quotidianamente, per avere notizie sulle condizioni di salute, la persona in sorveglianza.
Cosa bisogna fare al termine della quarantena per rientrare al lavoro?
Se non sono comparsi sintomi: Al termine del periodo di quarantena, se non sono comparsi sintomi, si può rientrare al lavoro ed il periodo di assenza risulta coperto dal certificato.
Se sono comparsi sintomi: Se durante la quarantena si sviluppassero sintomi, il Dipartimento di Sanità Pubblica, che si occupa della sorveglianza sanitaria, provvederà all’esecuzione del tampone per la ricerca di SARS-CoV-2. In caso di esito positivo dello stesso bisognerà attendere la guarigione clinica ed eseguire un test molecolare dopo almeno 3 giorni senza sintomi. Se il test molecolare risulterà negativo si potrà tornare al lavoro, altrimenti si proseguirà l’isolamento.
Fonte: Ministero della Salute
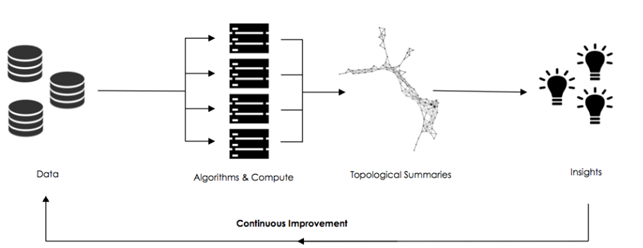
TDA in a nutshell: how can we find multidimensional voids and explore the “black boxes” of deep learning?
Topological Data Analysis (TDA) is an innovative set of techniques that is gaining an increasing relevance in data analytics and visualization. It uses notions of a miscellaneous set of scientific fields such as algebraic topology, computer science and statistics.
Its resulting tools allow to infer relevant and robust features of high-dimensional complex datasets that can present rich structures potentially corrupted by noise and incompleteness[74].
Here, two of the most common TDA methodologies will be briefly and intuitively introduced along with some of their interesting applications.
Topological Data Compression to represent the shape of data
Topological Data Completion to “measure” the shape of data
Topological Data Compression
Topological Data Compression algorithms aim at representing a collection of high dimensional clouds of points through graphs. These techniques rely on the fact that an object made of lots or infinitely many points, like a complete circle, can be approximated using only some nodes and edges [28].
The premise underlying TDA is that shape matters and in general real data in high dimensions is nearly always sparse, and tends to have relevant low dimensional features.
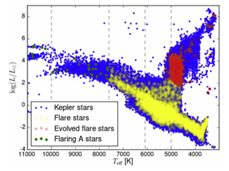
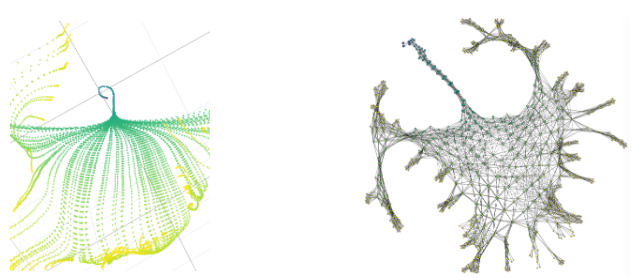
Consider for example the “Y”-shape detectable in the figure below
This shape occurs frequently in real data sets. It might represent a situation where the core corresponds to the most frequent behaviours and the tips of the flares to the extreme ones [30]. However, classical models such as linear ones and clustering methods cannot detect satisfactorily this feature.
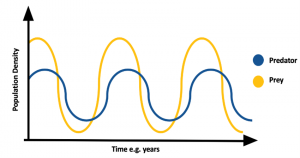
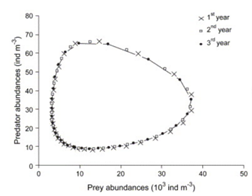
Another not trivial but important shape is the circular one; in fact loops can denote periodic behaviours. For example, in the Predatory-Prey model in the figure below, the circular shapes are due to the periodicity of the described biological system.
In a dynamic system, an attractor is a set towards which it tends to evolve after a sufficiently long time. System values that get close enough to the attractor ones have to remain close to them, even if slightly disturbed. A trajectory of a dynamic system on an attractor must not satisfy any particular property, but it is not unusual for it to be periodic and to present loops.
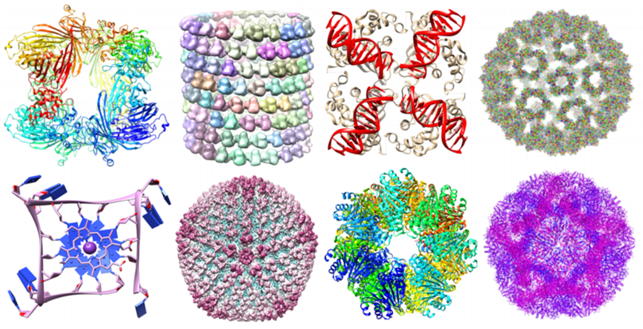
Consider, moreover, the great amount of not trivial geometric information carried by biomolecules and their importance for the analysis of their stability [63].
But, how can we go from an highly complex set of data points (PCD) to a simple summary of their main features and relations?
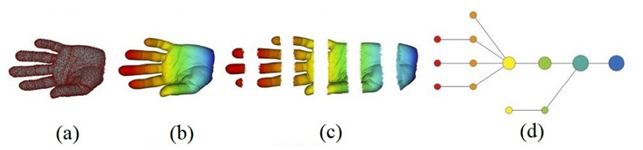
Topological Data Compression can detect these shapes easily and the main algorithm in this area is the Mapper. Its steps can be described as follows[88].
A PCD representing a shape is given.
It is covered with overlapping intervals by coloring the shape using filter values.
It is broken into overlapping bins.
The points in each bin are collapsed into clusters. Then a network is built representing each cluster by a vertex and drawing an edge when clusters intersect.
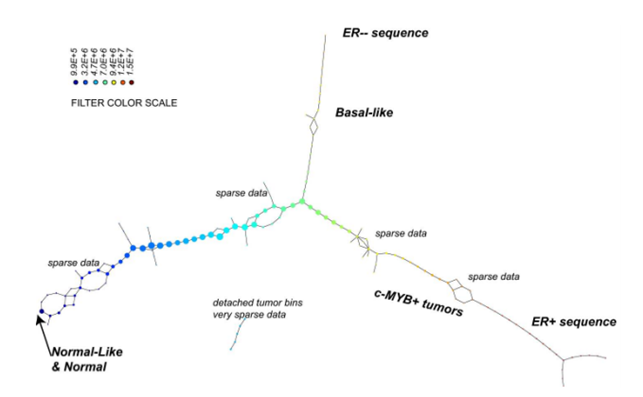
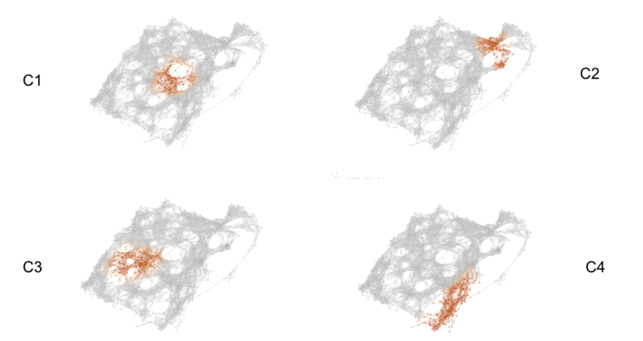
In work published in 2011 by Nicolau, Carlsson, and Levine[37], a new subtype of breast cancer was discovered[95] using the Progression Analysis of Disease (PAD), an application of the Mapper that provided an clear representation of the dataset. The used dataset describes the gene expression profiles of 295 breast cancer tumours [5]. It has 24.479 attributes and each of them specifies the level of expression of one gene in a tissue sample of the corresponding tumour. The researchers discovered the three-tendril “Y”-shaped structure shown below.
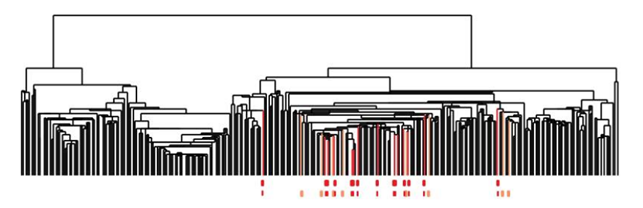
In addition, they found that one of these tendrils decomposes further into three clusters. One of these three clusters corresponds to a distinct new subtype of breast cancer that they named c-MYB+. A standard approach to the classification of breast cancers, based on clustering, divides breast cancers into five groups and these results suggested a different taxonomy not accounted before. In particular, the dendrogram of this dataset is shown below (the bins defining the c-MYB+ group are marked in red).
The c-MYB+ tumors are scattered among different clusters and there are many non-members of their group that lie in the same high-level cluster. Although, PAD was able to extract this group that turns out to be both statistically and clinically coherent. The new discovered subtype of cancer exhibits a 100% survival rate and no metastasis indeed. No supervised step beyond distinction between tumour and healthy patients was used to identify this subtype. The group has a clear, distinct and statistically significant molecular signature, this highlights coherent biology that is invisible to cluster methods. The problem is that clustering breaks data sets into pieces, so it can break things that belong together apart.
Improved Machine Learning Algorithms Ayasdi[7] is a machine intelligence software company that offers to organizations solutions able to analyse data and to build predictive models from them[9]. In particular, the Ayasdi system runs many different unsupervised and supervised machine learning algorithms on data, finds and ranks best fits automatically and then applies TDA to find similar groups in the results.
This is performed to reduce the possibility of missing critical insights by reducing the dependency on machine learning experts choosing the right algorithms [10]. This methodology has lead to many achievements, for example:
DARPA (Defense Advanced Research Projects Agency) used Ayasdi Core to analyse acoustic data tracks. The analysis identified signals that had been previously classified from traditional signal processing methods as unstructured noise [9].
Using TDA on the portfolio of a G-SIB institution, the bank was able to identify performance improvements by 103bp in less than two weeks. This was worth over 34 million annually, despite this portfolio had been heavily analysed previously [26].
TDA was used on the care process model for pneumonia of the Flagler Hospital. This methodology could extract nine potential pneumonia care pathways, each with distinctive elements. This represented a potential savings of more than $400K while delivering better care [6].
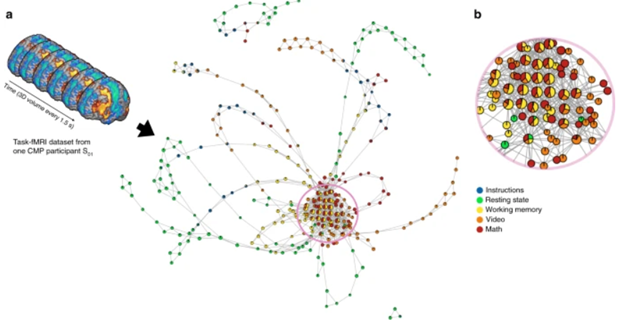
TDA-based data-driven discovery has great potential application for decision-support for basic research and clinical problems such as outcome assessment, neuro-critical care, treatment planning and rapid, precision-diagnosis [2]. For example, it has revealed new insights of the dynamical organization of the brain.
As Manish Saggar reports [1]
“How our brain dynamically adapts to perform different tasks is vital to understanding the neural basis of cognition. Understanding the brain’s dynamical organization is crucial for finding causes, cures and effective treatments for neurobiological disorders. The brain’s inability to dynamically adjust to environmental demands and aberrant brain dynamics have been previously associated with disorders such as schizophrenia, depression, attention deficiency and anxiety disorders. However, the high spatiotemporal dimensionality and complexity of neuroimaging data make the study of whole-brain dynamics a challenging endeavor.”
The scientists using TDA have been able to collapse data in space or time and generate graphical representations of how the brain navigates through different functional configurations. This revealed the temporal arrangement of whole-brain activation maps as a hybrid of two mesoscale structures, i.e., community and core−periphery organization.
Remarkably, the community structure has been found to be essential for the overall task performance, while the core−periphery arrangement revealed that brain activity patterns during evoked tasks were aggregated as a core while patterns during resting state were located in the periphery.
TDA has been used also for improving and better understating ML and AI algorithms. Neural Networks are powerful but complex and opaque tools. Using Topological Data Analysis, we can describe the functioning and learning of a convolutional neural network in a compact and understandable way. In paper [3] the researchers explain how deep neural networks (DNN) are trained using a gradient descent back propagation technique which trains weights in each layer for the sole goal of minimizing training error. Hence, the resulting weights cannot be directly explained.
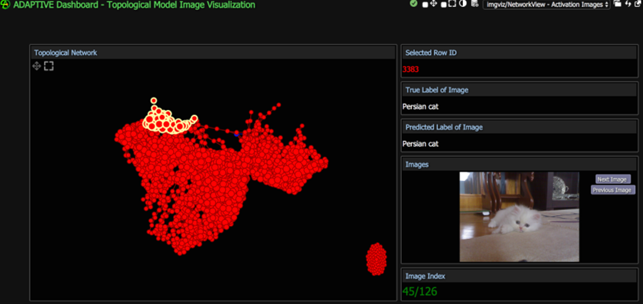
Using TDA they could extract useful insights on how the neural network they were using was thinking, specifically by analysing the activation values of validation images as they pass through each layer.
Below you can see as they have developed an Adaptive Dashboard visualization that allowed them to select and view groups of nodes in a topological model.
They reported
“Instead of making assumptions about what the neural network may be focusing on, suppose we had a way of knowing exactly which areas on the image were producing the highest activation values. We can do such analysis with the use of heat maps”
“(…) the pink colored spots are the locations where the neural network gave relatively high activations at nodes. So we can infer that VGG16 was focusing on the cat’s eyes and stripes when classifying this picture.
(…)So far we showed how to use TDA to identify clusters of correct and incorrect classifications. When we built the model using the activation values at several layers, we noticed that the misclassifications clustered into a single dense area. It is more interesting to analyze multiple clusters for which the reason for poor classification is different for each one.
(…)We converted 2,000 randomly picked images and extracted 5,000 pixel features. In this model, the images represented a majority of the 1,000 possible ImageNet labels. Each of the test images was also given an extra one-hot feature for being ”problematic”. We defined a problematic label to be one that we encountered at least three times in the test set and had an overall accuracy of less than 40%.
The topological model below is coloured by the density of problematic labels. The green nodes contain quite a few images that had problematic labels while blue nodes had almost none. The images with problematic labels cluster into roughly 4 distinct areas.
“The category of pictures in Cluster 1 were ordinary pictures with cluttered or unusual backgrounds. (…)Cluster 2 consists of images that are shiny or have glare. These types of images could have been rare in the training set so VGG16 automatically associates glare to a small set of classes. (…)Cluster 3 contains several chameleons (…) that have falsely been labelled as green lizards. This is likely because chameleons tend to blend in with their backgrounds similarly to how these green lizards blend in with the leafy environment. We can infer that there were few pictures of chameleons in the training set with green colored backgrounds. (…)In Cluster 4 we run into images with shadows and very low saturations. Here VGG16 faults when its identification of certain objects relies on color. We get false identifications when there is confusion caused by shadows and lack of color.”
The researcher concludes
“When we are able to identify unique clusters of incorrect classifications like in this example, we can then train new learners to perform well on each of these clusters. We would know to rely on this new learner when we detect that a test image exhibits similar features as the cluster’s topological group. In this case, the features were the pixel data of the images but we believe that the same methods would apply when analyzing the activation values as well. (…)With this new information on how the algorithm performs, we can potentially improve how we make predictions. We can find multiple clusters of images that make misclassifications for different reasons. Our next step would be to train new learners to perform well on the specific clusters that misclassify for certain reasons.”
Topological Data Completion
Topological data completion aims at detecting and counting properties of the shape of data that are preserved under continuous deformations such as crumpling, stretching, bending and twisting, but not gluing or tearing. Below, you can see a the figure that makes you understand the well-known mathematical joke “a topologist is a person who cannot tell the difference between a coffee mug and a donut”.
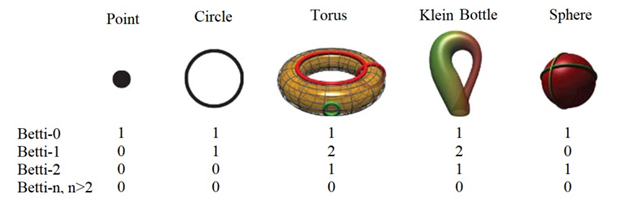
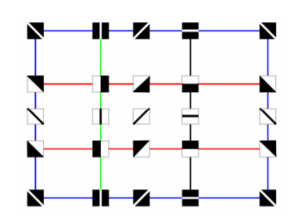
Single components, loops and voids are examples of these invariant properties and they are called Betti-0, Betti-1 and Betti-2, respectively. Below you can see Betti numbers of some shapes. For the torus, two auxiliary rings are added to explain Betti-1= 2 [34].
A Betti-n with a n>2 describes a “void” in higher dimensions, a multidimensional hole. In order to better understand higher dimensions you can start with the 4th watching the video below or directly playing the videogame “Miegakure: Explaining the Fourth Dimension”.
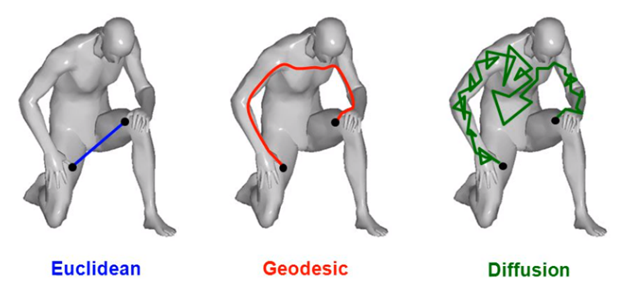
Now that we know what topologists look for, we need to have an idea of how they see “distances”. Without diving into mathematical technicalities, you can see below some distinct ways of considering distances between two points [19].
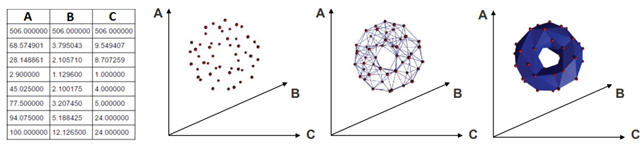
Now we can briefly describe the basic steps of topological data completion. We start by getting an input that is a finite set of elements coming with a notion of distance between them. The elements are mapped into a point cloud (PCD). Then this PCD is completed by building “continuous” shape on it, called a complex.
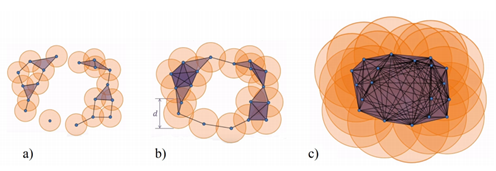
However, there are many ways to build complexes from a topological space. For example, which value of d should we use below to decide that two points are “close” one another?
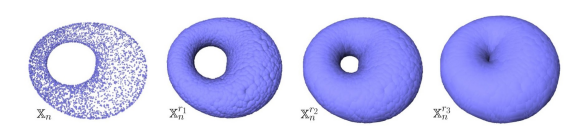
You don’t have to choose, you can consider all the (positive) distances d! Note that each hole appears at a particular value d1, and disappears at another value d2>d1. Below another example: a PCD sampled on the surface of a torus and its offsets for different values of the radius r. For r1 and r2, the offsets are “equivalent” to a torus, for r3 to a sphere [48].
Given a parameterized family of spaces, the topological features that persist over a significant parameter range are to be considered as true features with short-lived characteristics due to noise [70].
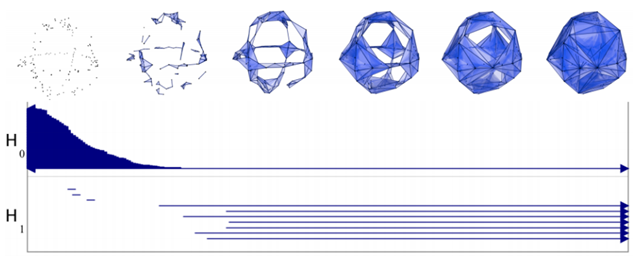
We can represent the persistence of the hole with a segment [d1,d2). In the figure below, H0 represents the persistence (while d grows) of Betti-0 (single components), while H1 the one of Betti-1 (circles).
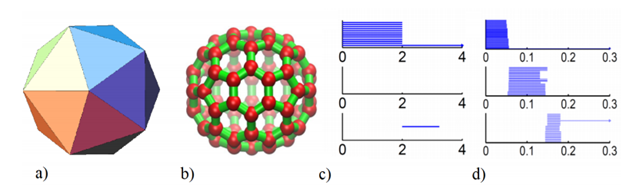
Using this approach we can associate to a set of points with a notion of distance a persistence diagram as the one shown above that represents its topological fingerprint. For example, below you can see the topological fingerprints of the icosahedron (a) and fullerene C70 (b). They are shown respectively in (c) and (d) where there are three panels corresponding to β0, β1 and β2 bars, respectively [123].
Note that for the icosahedron:
• β0: Originally 12 bars coexist, indicating 12 isolated vertices. Then, 11 of them disappear simultaneously with only one survived. These vertices connect with each other at ε = 2A˚, i.e., the designed bond length. The positions where the bars terminate are exactly the corresponding bond lengths.
• β1: As no one-dimensional circle has ever formed, no circle is generated.
• β2: There is a single bar, which represents a two-dimensional void enclosed by the surface of the icosahedron.
In regarding of the fullerene C70 barcodes:
• β0: There are 70 initial bars and 6 distinct groups of bars due to the presence of 6 types of bond lengths in the C70 structure.
• β1: There is a total of 36 bars corresponding to 12 pentagon rings and 25 hexagon rings. It appears that one ring is not accounted because any individual ring can be represented as the linear combination of all other rings. Note that there are 6 types of rings.
• β2: 25 hexagon rings further evolve to two-dimensional holes, which are represented by 25 bars. The central void structure is captured by the persisting β2 bar.
These studies have been used in a wide range of applications, below some examples are reported.
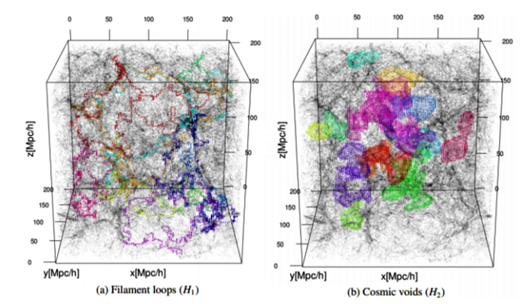
In [17] and [51], this technique has been used to provide a substantial extension of available topological information about the structure of the Universe. Below you can see the Cosmic Web in an LCDM simulation [17].
While connencted components, loops and voids do not fully quantify topology, they extend the information beyond conventional cosmological studies of topology in terms of genus and Euler characteristic [17]. Below you can see filament loops (a) and voids (b) identified in the Libeskind et al. (2018) dataset using SCHU. The most significant 10 filament loops (a) and the most significant 15 cosmic voids generators (b) are shown in different colours [51].
TDA has been used to find significant features hidden in a large data set of pixelated natural images (3×3 and 5×5 high-contrast patches).
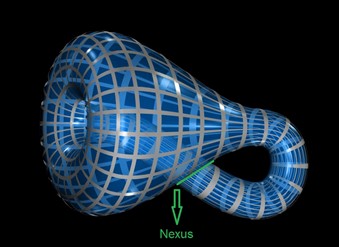
The subspace of linear and quadratic gradient patches forms a dense subset inside the space of all high-contrast patches and it was found to be topologically equivalent to the Klein bottle, a mathematical object that lives in 4-dimensions.
We represent a Klein Bottle in glass by stretching the neck of a bottle through its side and joining its end to a hole in the base. Except at the side-connection (the nexus), this properly shows the shape of a 4-D Klein Bottle.
This could lead to an efficient encoding of a large portion of a natural image: instead of using an “ad hoc” dictionary for approximating high-contrast patches, one can build such a dictionary in a systematic way by generating a uniform set of samples from the ideal Klein bottle [35].
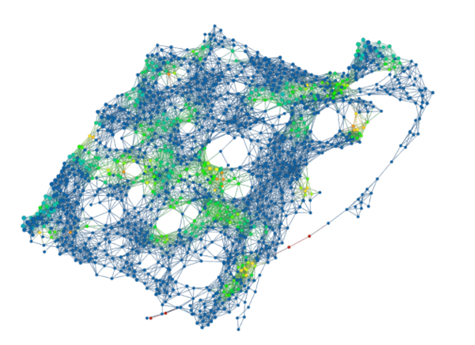
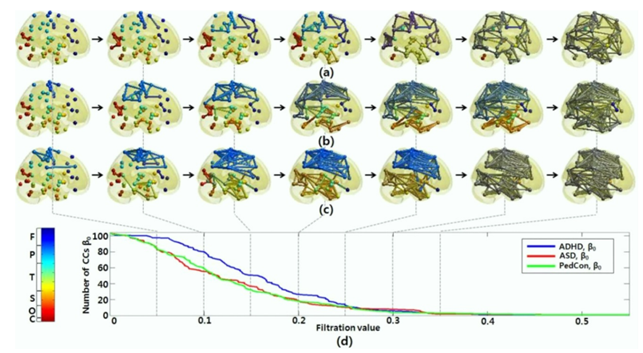
Traditionally, the structure of very complex networks has been studied through their statistical properties and metrics. However, the interpretation of functional networks can be hard. This had motivated the widespread of thresholding methods that risk overlooking the weak links importance. In order to overcome these limits efficient, alternative analysis of brain functional networks have been provided [24].
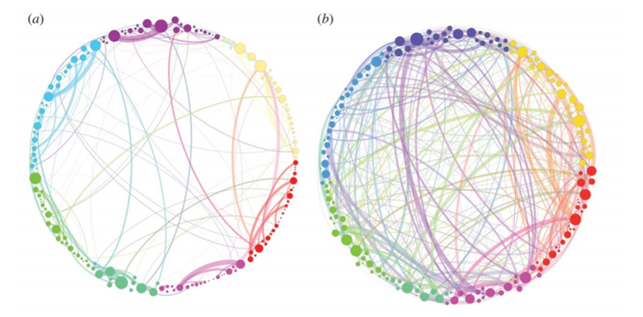
Above a simplified visualization of the results of TDA analysis on the relations of different areas of the brain. The colours represent communities obtained by modularity optimization. In (a) the placebo baseline is shown, in (b) the post-psilocybin structure one. The links widths are proportional to their weight and the diameter of the nodes to their strength [24].
These tools were applied to compare functional brain activity after intravenous infusion of placebo and psilocybin, a psychoactive component. The results, consistently with psychedelic state medical descriptions, show that the post-psilocybin homological brain structure is characterized by many transient structures of low stability and of a low number of persistent ones. This means that the psychedelic state is associated with less constrained and more inter-communicative brain activities[24].
In [50], to overcome the threshold problem, TDA was used to model all brain networks generated over every possible threshold. The evolutionary changes in the number of connected components are displayed below.
In [36], TDA was successfully used to find hidden structures in experimental data associated with the V1 visual cortex of certain primates.
In conclusion, Topological Data Analysis is a recent and fast growing branch of mathematics that has already proved to be able of providing new powerful approaches to infer robust qualitative, and quantitative, information about the structure of highly-dimensional, noisy and complex data.
Furthermore, TDA is increasingly being used with ML and AI techniques to improve and control their processing. This is why we can now talk about TML, Topological Machine Learning. As we can read on the paper “Topology of Learning in Artificial Neural Networks”[4]:
“Understanding how neural networks learn remains one of the central challenges in machine learning research. From random at the start of training, the weights of a neural network evolve in such a way as to be able to perform a variety of tasks, like classifying images. Here we study the emergence of structure in the weights by applying methods from topological data analysis. We train simple feedforward neural networks on the MNIST dataset and monitor the evolution of the weights. When initialized to zero, the weights follow trajectories that branch off recurrently, thus generating trees that describe the growth of the effective capacity of each layer. When initialized to tiny random values, the weights evolve smoothly along two-dimensional surfaces. We show that natural coordinates on these learning surfaces correspond to important factors of variation.”
Above you can see on the left a detail of the PCA projection of the evolution of the weights for the first hidden layer. Several phases are visible: uniform evolution (blue), parallel evolution along a surface (green), chaotic evolution (yellow). On the right, the learning graph representing the surface as a densely connected grid is shown.
[5] D. Atsma, H. Bartelink, R. Bernards, H. Dai, L. Delahaye, M. J. van de Vijver, T. van der Velde, S. H. Friend, A. Glas, A. A. M. Hart, M. J. Marton, M. Parrish, J. L. Peterse, C. Roberts, S. Rodenhuis, E. T. Rutgers, G. J. Schreiber, L. J. van’t Veer, D. W. Voskuil, A. Witteveen and D. H. Yudong, A Gene-Expression Signature as a Predictor of Survival in Breast Cancer, N Engl J Med 2002; 347:1999-2009, DOI: 10.1056/NEJMoa021967, 2002.
[6] Ayasdi, Flagler Hospital, on Ayasdi official site at link htt ps : //s3.amazonaws.com/cdn.ayasdi.com/wp − content/uploads/2018/07/25070432/CS − Flagler −07.24.18.pd f , 2018.
[7] Ayasdi, official site on htt ps : //www.ayasdi.com/ (01/09/2018).
[9] Ayasdi, Advanced Analytics in the Public Sector, consulted on 10/10/2018 on htt ps : //s3.amazonaws.com/cdn.ayasdi.com/wp−content/uploads/2015/02/13112032/wp−ayasdi− in−the− public−sector.pd f , 2014.
[10] Ayasdi, president G. Carlsson, TDA and Machine Learning: Better Together, white paper, consulted on 01/10/2018.
[17] E.G.P. P. Bos, M. Caroli, R. van de Weygaert, H. Edelsbrunner, B. Eldering, M. van Engelen, J. Feldbrugge, E. ten Have, W. A. Hellwing, J. Hidding, B. J. T. Jones, N. Kruithof, C. Park, P. Pranav, M. Teillaud and G. Vegter, Alpha, Betti and the Megaparsec Universe: on the Topology of the Cosmic Web, arXiv:1306.3640v1 [astro-ph.CO], 2013.
[19] A. Bronstein and M. Bronstein, Numerical geometry of non-rigid objects, Metric model of shapes, slides consulted on 05/05/2018 on htt ps : //slideplayer.com/slide/4980986/.
[24] R. Carhart-Harris, P. Expert, P. J. Hellyer, D. Nutt, G. Petri, F. Turkheimer and F. Vaccarino, Homological scaffolds of brain functional networks, Journal of The Royal Society Interface, 11(101):20140873, 2014.
[26] G. Carlsson, Why TDA and Clustering Are Not The Same Thing, article on Ayasdi official site (htt ps : //www.ayasdi.com/blog/machine − intelligence/why − tda − and − clustering − are − di f f erent/), 2016.
[28] G. Carlsson, The Shape of Data conference, Graduate School of Mathematical Sciences, University of Tokyo, 2015.
[30] G. Carlsson, Why Topological Data Analysis Works, article on Ayasdi official site (htt ps : //www.ayasdi.com/blog/bigdata/why−topological −data−analysis−works/), 2015.
[34] G. Carlsson, T. Ishkhanov , D. L. Ringac, F. Memoli, G. Sapiro and G. Singh, Topological analysis of population activity in visual cortex, Journal of vision 8 8 (2008): 11.1-18.
[35] G. Carlsson, T. Ishkhanov, V. de Silva and A. Zomorodian, On the Local Behavior of Spaces of Natural Images, International Journal of Computer Vision, Volume 76, Issue 1, pp 1–12, 2008.
[36] G. Carlsson, T. Ishkhanov, F. Memoli, D. Ringach, G. Sapiro, Topological analysis of the responses of neurons in V1, preprint, 2007.
[37] G. Carlsson, A. J. Levine and M. Nicolau, Topology-Based Data Analysis Identifies a Subgroup of Breast Cancers with a Unique Mutational Profile and Excellent Survival, Proceedings of the National Academy of Sciences 108, no. 17: 7265–70, 2011.
[48] F. Chazal and B. Michel, An introduction to Topological Data Analysis: fundamental and practical aspects for data scientists, arXiv:1710.04019v1 [math.ST], 2017
[50] M. K. Chung, H. Kang, B. Kim, H. Lee and D. S. Lee, Persistent Brain Network Homology from the Perspective of Dendrogram, DOI: 10.1109/TMI.2012.2219590, 2012.
[51] J. Cisewski-Kehea, S. B. Greenb, D. Nagai and X. Xu, Finding cosmic voids and filament loops using topological data analysis, arXiv:1811.08450v1 [astro-ph.CO], 2018.
[63] X. Feng, Y. Tong, G. W. Wei and K. Xia, Persistent Homology for The Quantitative Prediction of Fullerene Stability, arXiv:1412.2369v1 [q-bio.BM], 2014.
[70] R. Ghrist, Barcodes: The Persistent Topology Of Data, Bull. Amer. Math. Soc. 45 (2008), 61-75 , Doi: https://doi.org/10.1090/S0273-0979-07-01191-3, 2007.
[74] P. Grindrod, H. A. Harrington, N. Otter, M. A. Porter and U. Tillmann, A roadmap for the computation of persistent homology, EPJ Data Science, 6:17 DOI10.1140/epjds/s13688-017-0109-5, 2017.
[88] R. Kraft, Illustrations of Data Analysis Using the Mapper Algorithm and Persistent Homology, Degree Project In Applied And Computational Mathematics, Kth Royal Institute Of Tcehnology, Sweden, 2016.
[95] M. Lesnick, Studying the Shape of Data Using Topology, Institute for Advanced Study, School of Mathematics official site htt ps : //www.ias.edu/ideas/2013/lesnick − topological − data − analysis, 2013.
[123] G. W. Wei and K. Xia, Persistent homology analysis of protein structure, flexibility and folding, arXiv:1412.2779v1 [q-bio.BM], 2014.
Article by: Carla Federica Melia, Mathematical Engineer at Orbyta Srl, 19 october 2020
Introduci la tua esperienza professionale dall’università fino all’ingresso in Orbyta
Beh dal 2011 fino ad oggi penso di averne fatta di strada. Mi sono laureata in Management dell’Informazione e della Comunicazione aziendale (più lungo il titolo che il corso di laurea!), dopo varie esperienze estere in India, Polonia e Russia. Ho sempre puntato a lavorare in area commerciale, ispirata dal lavoro di mio papà che mi ha trasmesso questa passione.
Dopo più di 2 anni di esperienza in Banca, annoiata dalla routine e dagli orari standard, ho deciso di lanciarmi nel settore della consulenza informatica, l’estremo opposto, il dinamismo allo stato puro. Nell’ex EiSWORLD ho quindi ricoperto dapprima il ruolo di Account commerciale, per poi passare alla gestione del team recruiting e accounting, fino ad arrivare all’attuale ruolo di Business Development Manager in ORBYTA..
Di cosa ti occupi e che valore porti all’azienda
Mi occupo della gestione del team di Business Development, dove facciamo sia la parte di ricerca e selezione di personale ICT altamente specializzato, sia la parte commerciale e di sviluppo su grandi Clienti Enterprise. Siamo un team di 6 persone, siamo super affiatati e siamo il motore e l’energia che porta tanti nuovi Orbyters in azienda.
Che valore portiamo? Portiamo i cash, più valore di così!🤑
Perché ti piace lavorare in Orbyta?
D’impatto mi viene da dire “perchè ho contribuito a crearla”, ma a dire il vero sono tanti i motivi per cui amo il mio lavoro e amo farlo qui. Tra questi l’ambiente giovane e dinamico, innovativo e pervaso da un clima di entusiasmo e collaborazione.
Tutti hanno la possibilità di esprimersi e realizzarsi, di portare valore e di costruire la propria azienda in ORBYTA, proprio come me. Non è solo lavoro, è divertimento, preoccupazione, gioia e dolore, un mix spaziale che mi fa sentire viva!
Introduci la tua esperienza professionale dall’università fino all’ingresso in Orbyta
Quest’anno è il mio ventesimo anno di vita a Torino. Qui ho sperimentato veramente tanto. A partire dall’università, ho sempre cercato di diversificare, di espandere orizzontalmente le mie conoscenze. Sono partito con una laurea in ingegneria delle telecomunicazioni e finito con una laurea magistrale in ingegneria informatica.
Nei 15 anni seguenti alla laurea ho lavorato in contesti davvero differenti: ricercatore in progetti di sicurezza informatica, sviluppo software di robotica industriale, business assicurativo e bancario, sistemi di trasporto ITS, automotive, editoria tecnica e altro.
Da ognuna di queste esperienze ho tratto qualcosa di buono, incontrato persone che mi hanno dato molto e spero altrettanto di aver lasciato qualcosa anch’io di positivo che mi faccia ricordare con un sorriso.
Di cosa ti occupi e che valore porti all’azienda
Un buon bagaglio di esperienze, una faretra con tante frecce da poter utilizzare, ma soprattutto la consapevolezza che non si possa mai smettere di imparare sono le armi che utilizzo quotidianamente come responsabile dell’area tecnica in ORBYTA e della nostra software house AREA 51.
In Azienda porto quotidianamente uno spirito positivo, dedizione massima, voglia di insegnare soprattutto dando l’esempio, ma ancora di più di imparare.
Perché ti piace lavorare in Orbyta?
In ORBYTA ho la possibilità di attingere linfa dalla vitalità che l’azienda possiede e che dimostra quotidianamente di avere, di poter sperimentare sempre nuovi ambiti e tecnologie innovative.
Allo stesso modo mi piace pensare che il mio modo di essere abbia contribuito a plasmare ORBYTA nella sua mentalità attuale che sarà il motore dei nostri futuri successi.
Quando, anni fa, ho iniziato a lavorare come consulente IT ho dovuto sviluppare e modificare script che venivano eseguiti su server UNIX. Non avevo a disposizione strumenti di tendenza. Fondamentalmente Notepad ++ per si scrive localmente sulla mia macchina e PuTTY o FileZilla per raggiungere i server remoti. Quindi, sui server, erano installati i “temibili” Vi o Vim . Così ho iniziato a usare anche Vim , e la prima cosa che ho dovuto imparare era “come uscire da Vim”.
Vim ha una curva di apprendimento ripida . In quel momento ho imparato solo pochi comandi di base, quelli fondamentali per lavorare e poi appena ho avuto la possibilità di passare a qualcos’altro l’ho fatto. Ma Vim ha anche un grande potenziale , se sai come usarlo. Ricordo che il mio capo poteva usarlo abbastanza bene ed era molto abile in questo. Certo è difficile e devi usarlo molto per iniziare a vedere miglioramenti, ma lo sforzo è ben pagato.
Alcuni giorni fa, in un tweet, ho scoperto l’esistenza di questo sito: vimforvscode.com . Ho pensato: “Wow, imparare Vim usando VS Code? 10 $ è un prezzo per cui vale la pena provare ”. Ho installato l’ estensione VS Code : VSCodeVim e poi ho iniziato le lezioni che ho acquistato dal sito. Gli esercizi non sono difficili e ti permettono, attraverso la pratica e i suggerimenti, di imparare 22 comandi di base.
Ovviamente le lezioni di vimforvscode.com non bastano per padroneggiare appieno Vim , ti consiglio di provare ad esercitarti molto, cercando di aggiungere gradualmente più comandi. Queste risorse possono essere utili:
Barbarian meets coding è un sito meraviglioso (la home page è qualcosa di incredibile, ti consiglio – anche se non sei interessato a Vim – di dare un’occhiata!) Che tra l’altro spiega come usare VSCodeVim , c’è un libro gratuito , che puoi leggere online, con tutte le funzionalità di Vim in VS Code , e se ti serve solo un breve riepilogo puoi usare il cheat sheet
Vim Cheat sheet è un cheat sheet completo per Vim , ma anche se ci sono alcuni comandi che non sono supportati nell’estensione VS Code ce ne sono altri che nel cheat sheet “barbaro” sono assenti.
Vim adventures è un gioco molto carino che ti può insegnare Vim : è molto divertente, i primi 3 livelli sono gratuiti, poi devi acquistare una licenza personale da 25 $. Ho provato fino al livello 3, ma se tutti i livelli sono simili a quelli gratuiti, penso che valga il prezzo!
E così sono tornato su Vim , in VS Code ora. Devo ammettere che all’inizio mi sentivo abbastanza lento, ma, giorno dopo giorno, sento che sto migliorando e che forse sarò più efficiente di prima nel prossimo futuro. Penso che usare Vim in VS Code possa essere un’esperienza “strana” se non ci sei abituato, ma con un po ‘di impegno e molta pratica può essere davvero soddisfacente!
Articolo a cura di Federico Gambarino
Su questo sito utilizziamo cookie tecnici necessari alla navigazione e funzionali all’erogazione del servizio. Utilizziamo i cookie anche per fornirti un’esperienza di navigazione sempre migliore, per facilitare le interazioni con le nostre funzionalità social.
Puoi esprimere il tuo consenso cliccando su ACCETTA TUTTI.
I cookie necessari sono assolutamente essenziali per il corretto funzionamento del sito web. Questi cookie garantiscono le funzionalità di base e le caratteristiche di sicurezza del sito web, in modo anonimo.
Cookie
Durata
Descrizione
__hssrc
session
This cookie is set by Hubspot whenever it changes the session cookie. The __hssrc cookie set to 1 indicates that the user has restarted the browser, and if the cookie does not exist, it is assumed to be a new session.
cookielawinfo-checkbox-analytics
11 months
Questo cookie è impostato dal plug-in GDPR Cookie Consent. Il cookie viene utilizzato per memorizzare il consenso dell'utente per i cookie nella categoria "Analytics".
cookielawinfo-checkbox-functional
11 months
Il cookie è impostato dal consenso cookie GDPR per registrare il consenso dell'utente per i cookie nella categoria "Funzionali".
cookielawinfo-checkbox-necessary
11 months
Questo cookie è impostato dal plug-in GDPR Cookie Consent. I cookie vengono utilizzati per memorizzare il consenso dell'utente per i cookie nella categoria "Necessari".
cookielawinfo-checkbox-others
11 months
Questo cookie è impostato dal plug-in GDPR Cookie Consent. Il cookie viene utilizzato per memorizzare il consenso dell'utente per i cookie nella categoria "Altri.
cookielawinfo-checkbox-performance
11 months
Questo cookie è impostato dal plug-in GDPR Cookie Consent. Il cookie viene utilizzato per memorizzare il consenso dell'utente per i cookie nella categoria "Prestazioni".
JSESSIONID
session
Utilizzato da siti scritti in JSP. Cookie di sessione della piattaforma per scopi generici che vengono utilizzati per mantenere lo stato degli utenti attraverso le richieste di pagina.
viewed_cookie_policy
11 months
Il cookie è impostato dal plug-in GDPR Cookie Consent e viene utilizzato per memorizzare se l'utente ha acconsentito o meno all'uso dei cookie. Non memorizza alcun dato personale.
I cookie funzionali aiutano a eseguire determinate funzionalità come condividere il contenuto del sito Web su piattaforme di social media, raccogliere feedback e altre funzionalità di terze parti.
Cookie
Durata
Descrizione
__cf_bm
30 minutes
Questo cookie, impostato da Cloudflare, viene utilizzato per supportare la gestione dei bot di Cloudflare.
__hssc
30 minutes
HubSpot imposta questo cookie per tenere traccia delle sessioni e per determinare se HubSpot deve incrementare il numero di sessione e i timestamp nel cookie __hstc.
bcookie
2 years
LinkedIn imposta questo cookie dai pulsanti di condivisione di LinkedIn e aggiunge tag per riconoscere l'ID del browser.
lang
session
Questo cookie viene utilizzato per memorizzare le preferenze di lingua di un utente per fornire contenuti in quella lingua memorizzata la prossima volta che l'utente visita il sito web.
lidc
1 day
LinkedIn imposta il cookie lidc per facilitare la selezione del data center.
I cookie per le prestazioni vengono utilizzati per comprendere e analizzare gli indici di prestazioni chiave del sito Web che aiutano a fornire una migliore esperienza utente per i visitatori.
I cookie analitici vengono utilizzati per capire come i visitatori interagiscono con il sito web. Questi cookie aiutano a fornire informazioni sulle metriche del numero di visitatori, della frequenza di rimbalzo, della sorgente del traffico, ecc.
Cookie
Durata
Descrizione
__hstc
1 year 24 days
This is the main cookie set by Hubspot, for tracking visitors. It contains the domain, initial timestamp (first visit), last timestamp (last visit), current timestamp (this visit), and session number (increments for each subsequent session).
_ga
2 years
Il cookie _ga, installato da Google Analytics, calcola i dati di visitatori, sessioni e campagne e tiene anche traccia dell'utilizzo del sito per il report di analisi del sito. Il cookie memorizza le informazioni in modo anonimo e assegna un numero generato casualmente per riconoscere i visitatori unici.
_gat_gtag_UA_162571803_1
1 minute
This cookie is set by Google and is used to distinguish users.
_gid
1 day
Installato da Google Analytics, il cookie _gid memorizza informazioni su come i visitatori utilizzano un sito web, creando anche un report analitico delle prestazioni del sito web. Alcuni dei dati raccolti includono il numero di visitatori, la loro fonte e le pagine che visitano in modo anonimo.
CONSENT
16 years 3 months 10 days 7 hours 5 minutes
Questi cookie vengono impostati tramite video di YouTube incorporati. Registrano dati statistici anonimi su ad esempio quante volte viene visualizzato il video e quali impostazioni vengono utilizzate per la riproduzione. Nessun dato sensibile viene raccolto a meno che non accedi al tuo account google, in tal caso le tue scelte sono legate al tuo account, ad esempio se fai clic su "mi piace" su un video.
hubspotutk
1 year 24 days
Questo cookie viene utilizzato da HubSpot per tenere traccia dei visitatori del sito web. Questo cookie viene passato a Hubspot all'invio del modulo e utilizzato durante la deduplicazione dei contatti.
I cookie pubblicitari vengono utilizzati per fornire ai visitatori annunci e campagne di marketing pertinenti. Questi cookie tengono traccia dei visitatori sui siti Web e raccolgono informazioni per fornire annunci personalizzati.
Cookie
Durata
Descrizione
bscookie
2 years
Questo cookie è un cookie ID del browser impostato dai pulsanti di condivisione collegati e dai tag degli annunci.
IDE
1 year 24 days
I cookie di Google DoubleClick IDE vengono utilizzati per memorizzare informazioni su come l'utente utilizza il sito Web per presentargli annunci pertinenti e in base al profilo dell'utente.
test_cookie
15 minutes
Il test_cookie è impostato da doubleclick.net e viene utilizzato per determinare se il browser dell'utente supporta i cookie.
VISITOR_INFO1_LIVE
5 months 27 days
Un cookie impostato da YouTube per misurare la larghezza di banda che determina se l'utente ottiene la nuova o la vecchia interfaccia del lettore.
YSC
session
Il cookie YSC è impostato da Youtube e viene utilizzato per tenere traccia delle visualizzazioni dei video incorporati nelle pagine di Youtube.
yt-remote-connected-devices
never
YouTube imposta questo cookie per memorizzare le preferenze video dell'utente utilizzando il video YouTube incorporato.
yt-remote-device-id
never
YouTube imposta questo cookie per memorizzare le preferenze video dell'utente utilizzando il video YouTube incorporato.
yt.innertube::nextId
never
Questi cookie vengono impostati tramite video di YouTube incorporati.
yt.innertube::requests
never
These cookies are set via embedded youtube-videos.