Introduci la tua esperienza professionale dall’università fino all’ingresso in ORBYTA.
Dopo aver conseguito a pieni voti la Laurea Triennale e Magistrale in Economia Aziendale, con indirizzo Professioni Contabili, ho svolto il tirocinio professionale in diversi studi di commercialisti per diventare una consulente aziendale sul piano contabile, fiscale e tributario. In tal modo, oltre ad aver messo in pratica gli insegnamenti universitari, ho imparato ad utilizzare i programmi di contabilità, a gestire le pratiche dei clienti esterni, a redigere i bilanci ed alcuni dichiarativi. Ero però curiosa di vivere più dall’interno la realtà di un’azienda ed è allora che sono approdata in Orbyta!
Di cosa ti occupi e che valore porti all’azienda?
Nel 2018 sono entrata a far parte dell’area amministrativa del Gruppo Orbyta grazie alle mie competenze e dall’esperienza lavorativa maturata precedentemente. In azienda ho iniziato un percorso intenso e motivante che mi ha permesso di crescere, di collaborare con le diverse aree aziendali e di interfacciarmi con moltissimi interlocutori come i dipendenti, i consulenti esterni e gli istituti bancari. Inoltre, ho partecipato attivamente alle riunioni aziendali per approfondire, insieme ai CFO ed alle mie colleghe responsabili delle loro aree, l’andamento del gruppo e le proiezioni per il futuro delle nostre aziende.
A gennaio 2021, con l’ingresso di Orbyta Tax&Finance, una società specializzata nella consulenza fiscale e societaria, è stato come un ritorno alle origini! Dato il difficile periodo economico che le aziende stanno attraversando, credo sia diventato sempre più indispensabile mettere a fattor comune esperienze e risorse soprattutto per sostenere le piccole realtà imprenditoriali del nostro paese. Per questo motivo ho deciso di uscire dalla mia zona di comfort di amministrativa e rimettermi in gioco intraprendendo il percorso da consulente.
Perché ti piace lavorare in ORBYTA?
Tutte le società del gruppo permettono ad ognuno degli Orbyter di esprimere al meglio il proprio potenziale sia in ambito professionale che personale, infatti, ogni anno vengono programmati:
Colloqui Obiettivi personalizzati in base alle competenze di ciascuno;
Eventi di Team Building per creare spirito di squadra;
Seminari realizzati dagli Orbyters stessi su tematiche differenti. In essi ognuno è libero di esprimersi e condividere molteplici argomenti, dai più tecnici e formativi ai più divertenti e stimolanti.
Credo che la specificità dei singoli debba essere considerata il nostro valore e l’identità che nasce dall’unionesia la nostra forza: se ognuno mette in gioco le proprie capacità e le proprie risorse il risultato finale sarà sempre migliore della somma delle singole skill.
Sono convinta che la volontà, l’impegno ed il senso di appartenenza di tutti ci permetteranno di ottenere risultati importanti con un orizzonte di grande potenzialità.
Questo è Orbyta!
Mario Berger
Introduci la tua carriera professionale fino al ruolo di Direttore Tecnico di ORBYTA Engineering
Subito dopo la Laurea magistrale in ingegneria civile mi sono trasferito in Valle d’Aosta per iniziare la mia prima esperienza lavorativa presso la Nolovallee, società operante nel settore del noleggio e della vendita di macchine ed attrezzature per cantieri edili. All’interno dell’azienda mi occupavo principalmente della logistica e dell’assistenza tecnica.
Ho ben presto capito che questa non sarebbe stata la mia strada e così, dopo essere rientrato a Torino, mi sono iscritto all’ordine degli ingegneri e ho iniziato la libera professione specializzandomi nella progettazione di impianti meccanici.
La mia continua voglia di crescita mi porta a frequentare, nel 2017, il corso di specializzazione in prevenzione incendi. Qui conosco Fabio, con cui nasce fin da subito una naturale amicizia e una reciproca stima. La nostra condivisione dei valori e la comune visione del futuro ci portano, nel 2020, a fondare la Orbyta Engineering.
Qual è il valore che Engineering ha portato al Gruppo ORBYTA?
Orbyta Engineering è una società di progettazione giovane e dinamica che condivide e promuove i valori del gruppo Orbyta.
Il principale valore che la società porta al gruppo ORBYTA è sicuramente quello di ampliare l’offerta del gruppo, consentendo di soddisfare con tempestività e innovazione le richieste dei propri clienti siano esse in campo civile, industriale o terziario.
Che cosa significa innovazione per ORBYTA Engineering?
Prima di tutto è fondamentale capire cos’è l’innovazione e perché molte aziende raramente riescono ad innovarsi e ad avere successo.
L’innovazione dovrebbe essere un po’ come il senso dell’onestà: la sua diffusione dovrebbe essere naturale, invece è molto difficile da trovare al giorno d’oggi.
Per Orbyta Engineering l’innovazione è la capacità di trasmettere alle persone qualcosa di nuovo, di diverso. Qualcosa che abbia un impatto significativo sulle loro vite.
Bisognerebbe sempre mettere l’innovazione al primo posto perché quando un’azienda non riesce continuamente ad innovarsi, quante probabilità di successo può avere?
Quali sono le sfide che si prospettano per le società di ingegneria al giorno d’oggi? Come pensi di affrontarle?
La sfida principale che si prospetta per le società di ingegneria al giorno d’oggi è sicuramente il dover affrontare tematiche complesse e progettazioni sempre più integrate. Penso che il modo migliore per affrontare tale sfida e riuscire ad offrire una progettazione di successo sia avere all’interno del proprio team una multidisciplinarità di professionalità tecniche.
Un’altra sfida impegnativa è quella di riuscire a proporre sempre soluzioni innovative. Questa sfida penso che si debba affrontare con coraggio e senza timore di commettere errori. Molte aziende non riescono ad innovare perché troppo spesso hanno paura di un fallimento. Cerchiamo di progettare avendo sempre uno sguardo volto al futuro, senza affidarci unicamente all’esperienza che, per noi di Orbyta Engineering, è un punto di partenza e mai d’arrivo.
Recommender systems: principali metodologie degli algoritmi di suggerimento
Introduzione
Vi siete mai chiesti come faccia Netflix a suggerirvi il tipo di film adatto a voi? O Amazon a mostrarvi l’articolo di cui avevate bisogno? O come mai, le pubblicità che vi appaiono nei siti web facciano riferimento a qualcosa di vostro interesse? Questi sono solo alcuni esempi di un tipo di algoritmi che vengono oggigiorno usati dalla maggior parte dei siti web e dalle applicazioni per fornire agli utenti dei suggerimenti personalizzati, si tratta dei sistemi di raccomandazione.
In questo articolo scopriremo cosa sono, con quali metodi vengono implementati e come vengono valutate le loro performance.
Cosa sono i sistemi di raccomandazione
I sistemi di raccomandazione sono un tipo di sistemi di filtraggio dei contenuti. Possono essere descritti come degli algoritmi che hanno lo scopo di suggerire all’utente di un sito web o di un’applicazione degli articoli che possano risultare di suo interesse. Davanti ad una serie di prodotti devono essere in grado di selezionare e proporre quelli più adatti per ogni utente, quindi di fornire dei suggerimenti personalizzati.
Questo tipo di algoritmi vengono utilizzati in svariati settori. Gli esempi più evidenti possono essere quelli già citati all’inizio dell’articolo quindi nei servizi di e-commerce (es. Amazon), nei servizi di streaming di film, video o musica (es. Netflix, YouTube, Spotify), ma anche nelle piattaforme social (es. Instagram), nei servizi di delivery (es. Uber Eats) e così via. In generale, ogni qualvolta ci sia la possibilità di suggerire ad un utente un contenuto, può essere utilizzato un sistema di raccomandazione per renderlo specifico per l’utente stesso.
Figura 1. Esempi di applicazioni che utilizzano i sistemi di raccomandazione
Come vengono implementati
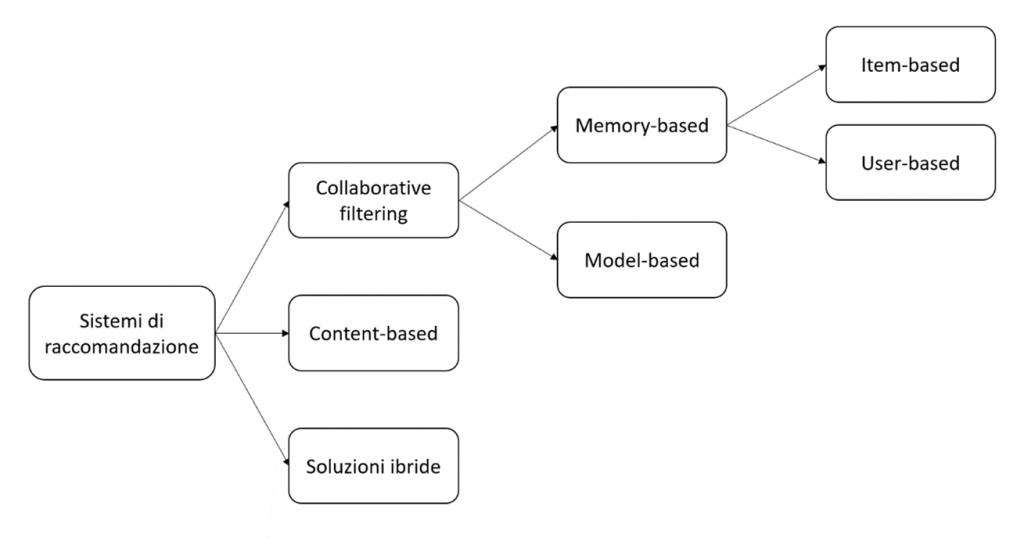
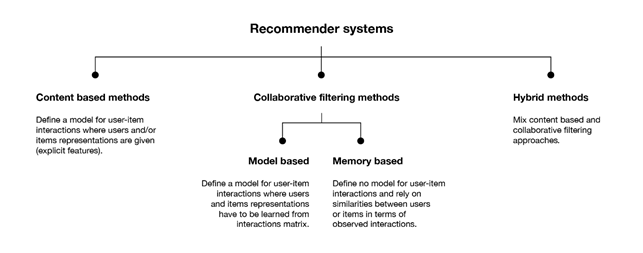
I sistemi di raccomandazione possono essere suddivisi principalmente in due macrocategorie: metodi collaborative filtering e metodi content-based. Inoltre, questi due approcci possono essere combinati per dare origine a delle soluzioni ibride che sfruttano i vantaggi di entrambi.
Figura 2. Categorie di metodi utilizzati per l’implementazione dei sistemi di raccomandazione
Metodi collaborative filtering
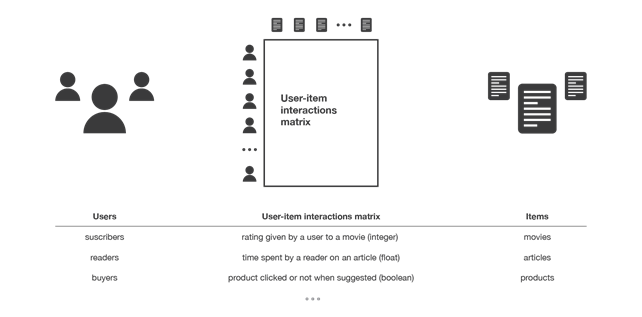
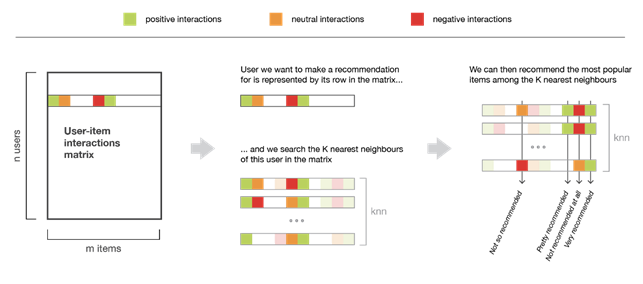
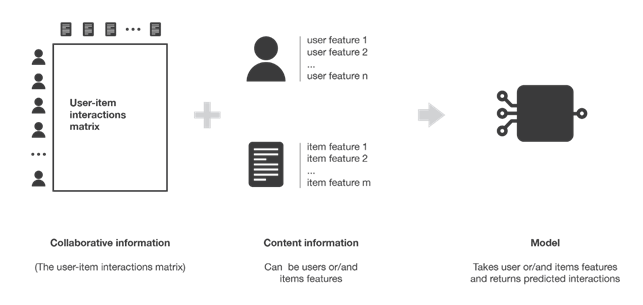
I sistemi di raccomandazione collaborative filtering utilizzano le interazioni avvenute tra utenti e articoli in passato per costruire la cosiddetta matrice di interazione utenti-articoli e da questa estrarre i nuovi suggerimenti. Si basano sull’assunzione che queste interazioni siano sufficienti per riconoscere gli utenti e/o gli articoli simili fra loro e che si possano fare delle predizioni concentrandosi su queste similarità.
Figura 3. Illustrazione della matrice di interazione utenti-articoli
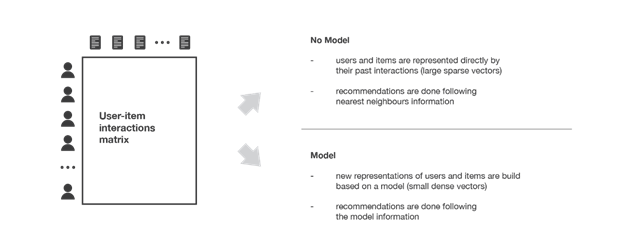
Questa classe di metodi si divide a sua volta in due sottocategorie, sulla base della tecnica utilizzata per individuare le similarità tra gli utenti e/o gli articoli: metodi memory-based e metodi model-based. I primi utilizzano direttamente i valori contenuti nella matrice di interazione utenti-articoli per ricercare “il vicinato” dell’utente o dell’articolo target, i secondi assumono che dai valori della matrice sia possibile estrarre un modello con cui effettuare le nuove predizioni.
Figura 4. Overview dei due tipi di metodi per implementare i sistemi di raccomandazione collaborative filtering
Il vantaggio principale dei metodi collaborative filtering è dato dal fatto che non richiedono l’estrazione di informazioni sugli utenti o sugli articoli dunque possono essere utilizzati in svariati contesti. Inoltre, più gli utenti interagiscono con gli articoli, maggiori informazioni si avranno a disposizione e più le nuove raccomandazioni saranno accurate.
Il loro svantaggio emerge nel momento in cui si hanno nuovi utenti o nuovi articoli perché non ci sono informazioni passate sulle loro interazioni, questa situazione viene definita cold start problem. In questo caso per stabilire quali debbano essere le nuove raccomandazioni si sfruttano diverse tecniche: si raccomandano articoli scelti casualmente ai nuovi utenti o nuovi articoli ad utenti scelti casualmente, si raccomandano articoli popolari ai nuovi utenti o nuovi articoli agli utenti più attivi, si raccomandano un set di vari articoli ai nuovi utenti o un nuovo articolo ad un set di vari utenti, oppure, si evita di utilizzare un approccio collaborative filtering in questa fase.
Metodi memory-based
I metodi memory-based si possono a loro volta suddividere in metodi user-based e metodi item-based.
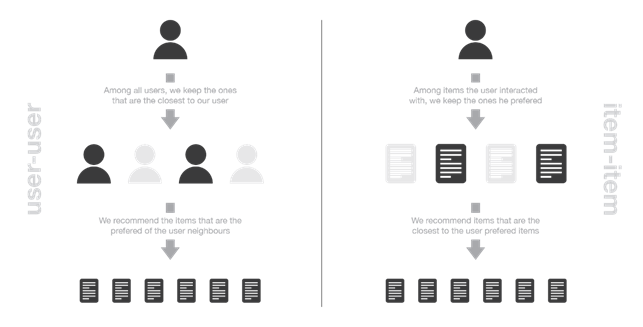
I metodi user-based rappresentano gli utenti considerando le loro interazioni con gli articoli e sulla base di questo valutano la similarità tra un utente e l’altro. In generale, due utenti sono considerati simili se hanno interagito con tanti articoli allo stesso modo. Per fare una nuova raccomandazione ad un utente si cerca di identificare quelli con i “profili di interazione” più simili al suo, in modo tale da suggerirgli gli articoli più popolari tra il suo vicinato.
Figura 5. Illustrazione del metodo user-based
Un esempio di applicazione del metodo user-based viene utilizzato da Youtube per suggerirci i video presenti nella nostra Homepage.
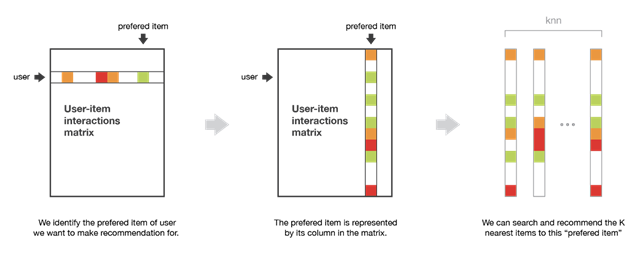
I metodi item-based rappresentano gli articoli basandosi sulle interazioni che gli utenti hanno avuto con loro. Due articoli vengono considerati simili se la maggior parte degli utenti che ha interagito con entrambi lo ha fatto allo stesso modo. Per fare una nuova raccomandazione ad un utente, questi metodi cercano articoli simili a quelli con la quale l’utente ha interagito positivamente.
Figura 6. Illustrazione del metodo item-based
Un esempio di applicazione del metodo item-basedviene utilizzato da Amazon quando clicchiamo su un articolo e ci appare la sezione “i clienti che hanno visto questo articolo hanno visto anche” mostrandoci altri articoli simili a quello che abbiamo selezionato.
Uno degli svantaggi dei metodi memory-based è il fatto che la ricerca del vicinato può richiedere molto tempo su grandi quantità di dati, quindi deve essere implementata attentamente e nel modo più efficiente possibile. Inoltre, bisogna evitare che il sistema raccomandi solo gli articoli più popolari e che agli utenti vengano suggeriti solo articoli molto simili a quelli che gli sono piaciuti in passato, deve essere in grado di garantire una certa diversità nei suggerimenti effettuati.
Figura 7. Confronto tra il metodo user-based e item-based
Metodi model-based
I metodi model-based si basano sull’assunzione che le interazioni tra articoli e utenti possano essere spiegate tramite un modello “nascosto”.
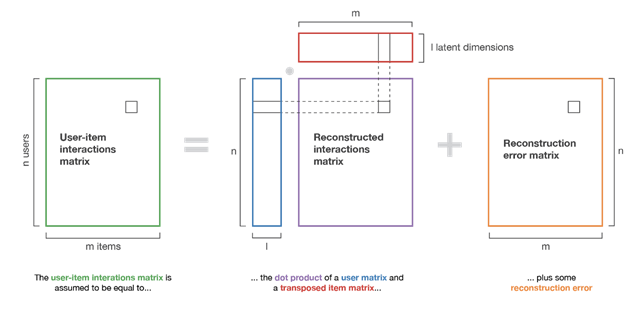
Un esempio di algoritmo per l’estrazione del modello è la matrix-factorization, questo consiste sostanzialmente nella decomposizione della matrice di interazione utenti-articoli nel prodotto di due sottomatrici, una contenente la rappresentazione degli utenti e l’altra la rappresentazione degli articoli. Utenti simili in termini di preferenze e articoli simili in termini di caratteristiche avranno delle rappresentazioni simili nelle nuove matrici.
Figura 8. Illustrazione del metodo matrix-factorization
Metodi content-based
A differenza dei sistemi di raccomandazione collaborative filtering che si basano solo sull’interazione tra utenti e articoli, i sistemi di raccomandazione content-based ricercano delle informazioni aggiuntive.
Supponiamo di avere un sistema di raccomandazione che deve occuparsi di suggerire film agli utenti, in questo caso le informazioni aggiuntive potrebbero essere l’età, il sesso e il lavoro per gli utenti così come la categoria, gli attori principali e il regista per i film.
I metodi content-based cercano di costruire un modello che sappia spiegare la matrice di interazione utenti-articoli basandosi sulle features disponibili per gli utenti e gli articoli.
Dunque, considerando l’esempio precedente, si cerca il modello che spieghi come ad utenti con certe features piacciano film con altrettante features. Una volta che questo modello è stato ottenuto, fare delle predizioni per un nuovo utente è facile, basta considerare le sue features e di conseguenza verranno fatte le nuove predizioni.
Figura 9. Overview dei sistemi di raccomandazione content-based
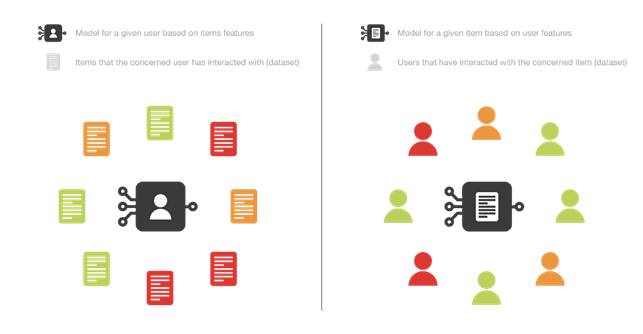
Nei metodi content-based il problema di raccomandazione viene trattato come un problema di classificazione (predire se ad un utente possa piacere o meno un articolo) o di regressione (predire il voto che un utente assegnerebbe ad un articolo).
In entrambi i casi il problema si può basare sulle features dell’utente (metodo item-centred), o sulle features dell’articolo (metodo user-centred). Nel primo caso si costruisce un modello per articolo cercando di capire qual è la probabilità che ad ogni utente piaccia quell’ articolo, nel secondo caso si costruisce un modello per utente per capire qual è la probabilità che a quell’utente piacciano gli articoli a disposizione. In alternativa si può anche valutare un modello che contenga sia le features degli utenti che quelle degli articoli.
Figura 10. Confronto tra il metodo item-centred e user-centred
Il vantaggio dei metodi content-based è che non soffrono del cold start problem perché i nuovi utenti e i nuovi articoli sono definiti dalle loro features e le raccomandazioni vengono fatte sulla base di queste.
Figura 11. Overview dei sistemi di raccomandazione presentati
Come vengono valutati
Per valutare le performance di un sistema di raccomandazione, quindi per cercare di capire se le raccomandazioni che sta effettuando sono appropriate, vengono utilizzati principalmente tre tipi di valutazioni: user studies, la valutazione online e la valutazione offline.
La valutazione user studiesprevede diproporre agli utenti delle raccomandazioni effettuate da diversi sistemi di raccomandazione e di chiedergli di valutare quali raccomandazioni ritengono migliori.
La valutazione online, chiamata anche A/B test, prevede di proporre agli utenti in real-time diverse raccomandazioni per poter valutare quali sono quelle che ottengono più “click”.
La valutazione offline prevede di fare delle simulazioni sul comportamento degli utenti partendo dai dataset passati che si hanno a disposizione.
Articolo a cura di Monica Mura, Data Scientist in Orbyta, 11.03.2021
Elena Diodato
Introduci la tua esperienza professionale dall’università fino all’ingresso in Orbyta
A seguito del conseguimento di maturità classica mi sono appassionata all’informatica ed ho deciso di percorrere questa strada iscrivendomi e conseguendo la qualifica professionale presso un centro di formazione informatica di Roma.
La mia carriera ha avuto inizio all’interno di una Software house della capitale nella quale ho iniziato a sviluppare programmi in ColdFusion e siti web utilizzando CMS, prevalentemente Joomla.
Nel 2017 approdo in Orbyta ed inizio ad utilizzare le tecnologie Microsoft.
Di cosa ti occupi e che valore porti all’azienda?
Oggi sono responsabile della manutenzione di alcuni software in ColdFusion. Attualmente mi occupo dello sviluppo di un software di gestione nell’ambito dell’assicurazione del credito per una società del gruppo Allianz.
Perché ti piace lavorare in Orbyta?
Quello che più mi ha colpito della realtà di Orbyta è l’ambiente giovane e dinamico con forte spirito di gruppo. Tutto ciò rende il lavoro piacevole e mai monotono.
Tra le iniziative più interessanti spicca l’Orbyta Space Academy che dà la possibilità a tutti di tenere seminari su svariati argomenti, anche lontani dal mondo dell’informatica.
Infine, i forti incentivi per la formazione e l’aggiornamento professionale fanno di Orbyta un ecosistema in cui tutti sono invogliati a migliorarsi costantemente e a non fermarsi mai!
Mauro Esposito
Introduci la tua carriera professionale fino al ruolo di CEO Tax & Finance e CFO di ORBYTA GROUP
Durante il percorso di studi Universitario, ho iniziato la mia carriera lavorativa nello Studio di Amministrazione Stabili di famiglia. È stata un’esperienza importante che mi ha consentito di iniziare a comprendere l’importanza della contabilità e della precisione delle rilevazioni, e di prendere confidenza con i primi adempimenti fiscali, in quanto mi curavo all’interno dello Studio anche dei rapporti con il Commercialista e della redazione e trasmissione delle dichiarazioni fiscali collegate alla gestione condominiale.
Durante il percorso di Laurea Specialistica in Professioni Contabili, conseguita a fine 2011, ho iniziato la pratica professione per diventare Dottore Commercialista presso uno dei maggiori Studi di Torino. Il percorso è stato breve, in quanto dopo soli due mesi sono stato chiamato da uno Studio di Rivoli, decisamente più piccolo, ma con un ruolo molto operativo e di “prima fila”. E’ in questo Studio che, a seguito di alcuni episodi, ho preso in mano la mia carriera lavorativa. Già ad Agosto 2011 avevo redatto oltre 150 dichiarazioni dei redditi e tenevo in autonomia rapporto con alcuni clienti di Studio.
Per motivi di salute del Commercialista senior, lo Studio ha dovuto chiudere. Immediatamente sono stato contattato da una decina di clienti che hanno manifestato la volontà di continuare il percorso con me. Questo mi ha dato il coraggio di aprire il mio Studio, dopo soli 8 mesi di pratica svolta, il mio Studio. Come spesso si dice “il passo più difficile è il primo da compiere”. Da lì in poi è stato tutto in discesa. Grazie alla collaborazione e supporto di uno Studio di Alpignano, ho velocemente maturato tutte le competenze per la gestione in autonomia di uno Studio Professionale.
I ritmi di crescita sono stati esponenziali, ogni anno raddoppiavo i volumi, ed è proprio in virtù dei risultati raggiunti e delle collaborazioni costruite che nel 2015 (a seguito dell’abilitazione all’esercizio della professione da Dottore Commercialista) fondiamo, con Sarah, la nostra società di servizi contabili (oggi Orbyta Tax & Finance) ed apriamo la nostra sede ad Orbassano. Nel frattempo, anche stimolato da progetti importanti, ricopro ruoli di CFO in Start Up Innovative e, per due anni, ricopro il ruolo di CEO in una società di Automazione Industriale orientata all’innovazione tecnologica ed al mercato mondiale. In questa esperienza, grazie al lavoro a stretto contatto con l’altro CEO della società, Daniele, maturo anche esperienze nei mercati internazionali e nella gestione imprenditoriale.
Il 2020 è stato l’anno in cui grazie a Fabio, sono entrato in contatto con il mondo Orbyta e gli altri membri del CdA del Gruppo, Daniela e Lorenzo. Da subito ho sposato il loro progetto. Entrare a far parte di un gruppo giovane, dinamico e con principi sani è qualcosa che immediatamente ha dato una ulteriore spinta alla crescita di Orbyta Tax & Finance, e siamo solo all’inizio.
Qual è il valore che ORBYTA TAX & FINANCE ha portato al Gruppo ORBYTA?
Ritengo che i valori siano molteplici. Dalla riorganizzazione e crescita dell’area Amministrativa, che ad oggi ha internalizzato tutti i processi di contabilità e tutti gli adempimenti fiscali e civilistici, alla possibilità di “attirare” e mettere in contatto con tutte le società del Gruppo le diverse PMI con cui, per ovvie ragioni, un commercialista ha costante contatto alla visione diversificata di alcune tematiche aziendali.
Inoltre, una diversificazione dell’offerta che consente al Gruppo di proporsi come guida e come una unica struttura per affiancare altre imprese nel proprio sviluppo e crescita, potendo aggiungere all’offerta di gruppo, anche la consulenza contabile, fiscale, manageriale e finanziaria.
Qual è la mission di un CFO all’interno di un gruppo come ORBYTA?
La mission è esplicitata dalla stessa natura del ruolo. Il CFO ha la responsabilità della supervisione della gestione finanziaria del Gruppo, di cui assicura la stabilità e ottimizza la performance. Il CFO svolge tre compiti fondamentali: Reportistica, Liquidità, Ritorno sull’investimento.
A dirla tutta, il Gruppo ha un’ottima solidità creata nel tempo grazie alle politiche del board, che rende veramente agevole questo ruolo in azienda.
Come ritieni che si evolverà nel prossimo futuro il settore della consulenza fiscale e societaria e quali ritieni che sia la giusta strategia per approcciarsi a questa evoluzione?
Il percorso evolutivo della professione è iniziato da alcuni anni. L’avvento della fatturazione elettronica, la crescita dei sistemi informatici e la crescita dei controlli automatizzati dell’Agenzia delle Entrate, stanno portando chi svolge la mia attività a potersi dedicare con maggiore attenzione alla consulenza, andando a ridurre le attività operative e contabili.
Ritengo che la strategia corretta, per approcciarsi alla trasformazione, sia proprio quella di trasformare la figura del Commercialista Contabile, nello Studio Commercialista Consulente di Impresa, ovvero una struttura complessa, basata sul lavoro in Team, che può affiancare l’imprenditore nelle scelte strategiche (dalla costituzione aziendale alla fine dell’attività imprenditoriale), utilizzando la contabilità ed i dati finanziari come strumento per analisi e ponendo sempre grande attenzione alle norme di settore che spesso nascondono importanti opportunità per le imprese.
Daniel Morohai
Introduci la tua esperienza professionale dall’università fino all’ingresso in Orbyta
Sono un geometra e mi sono diplomato a Torino nel 2014, concludendo il mio percorso di studio nel 2016 con l’abilitazione alla libera professione.
Durante il percorso di abilitazione alla professione mi sono specializzato come Tecnico nell’ambito della Sicurezza sui Luoghi di Lavoro, da dove è poi iniziato il mio percorso professionale sino ad arrivare a far parte della Orbyta Compliance Srl.
Durante i cinque anni di esperienza maturati ho avuto modo di vedere e imparare diverse sfaccettature, che mi hanno permesso di accrescere le mie competenze e conoscenze professionali, soprattutto durante il periodo di affiancamento con l’attuale fondatore della Orbyta Compliance Srl.
Di cosa ti occupi e che valore porti all’azienda?
All’interno del Gruppo svolgo il ruolo di H&S Consultant e mi occupo di:
Consulenza nell’ambito della Sicurezza aziendale e cantieristico secondo quanto previsto dal D.Lgs 81/08
Pratiche di prevenzione incendi
Attività di progettazione di impianti
Autorizzazioni per le attività produttive
Formazione per la salute e la sicurezza sui luoghi di lavoro
Il valore aggiunto che mi permette di fare la differenza sul lavoro è senz’altro la determinazione e la continuità con cui affronto le nuove sfide. Penso che la passione e la continua formazione siano la base per fare la differenza sul lavoro.
Perché ti piace lavorare in orbyta?
Sono fiero di fare parte del Gruppo Orbyta, perché è un contesto giovane che investe sulla formazione dei propri dipendenti valorizzandone le competenze. Il lavoro che faccio mi permette di vedere tanti clienti e realtà diverse, pertanto posso dire che a lavorare in Orbyta non ci si annoia mai.
Introduction to Quantum Computing and Qiskit
Traditional VS quantum computers
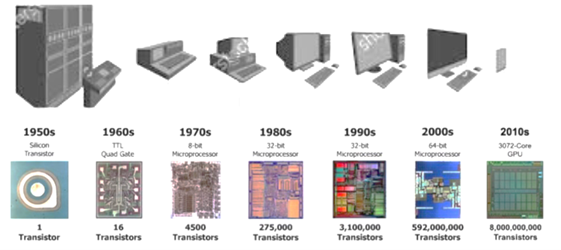
Since the 1960’s, the power of our computers has kept growing exponentially, allowing them to get smaller and more powerful.
A computer is made up of very simple components: computer chips contain modules, that contain logic gates, that contain transistors.
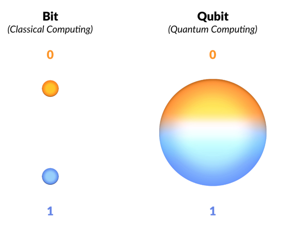
A transistor is the simplest form of a data processor in computers, and it basically consists of an electric switch that can either block or open the way for information flow. This information is made up of bits that can be set to either 0 or 1 and that are the smallest unit of information.
These switches are approaching smaller and smaller sizes as technology improves. Today, a typical scale for transistors is 14 nm, about 500 times smaller than a red blood cell, but they can be also smaller.
In the quantum world, physics works quite differently from the predictable ways we are used to, and traditional computers just stop making sense. We are approaching a real physical barrier for our technological progress. Now, scientists are trying to use these unusual quantum properties to their advantage by building quantum computers.
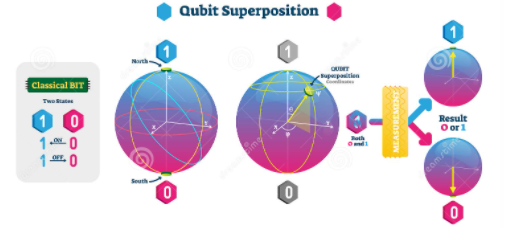
Quantum computers do not use bits but qubits that can be created using electrons, atoms, photons, or even molecules. These qubits can be in any proportions of both 1 and 0 states at once and this property is called superposition.
However, as soon as a qubits value is tested, for example by sending the photon through a filter, it must decide to be either vertically or horizontally polarized. So, as long as it’s unobserved, the qubit is in a superposition of probabilities for 0 and 1, and you can’t predict which it’ll be. But the instant you measure it, it collapses into one of the definite states.
Curiosity In 1935, Erwin Schrödinger devised a well-known thought experiment, now known as Schrödinger’s cat, which highlighted this dissonance between quantum mechanics and classical physics. For more info about quantum superposition visit the following link (https://www.youtube.com/watch?v=lZ3bPUKo5zc).
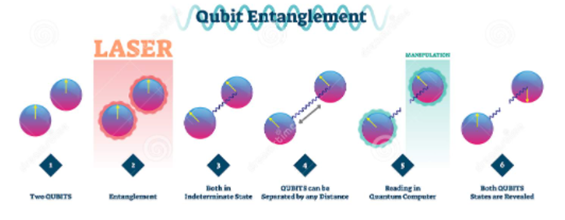
Another property qubits can have is entanglement, a close connection that makes each of the qubits react to a change in the other’s state instantaneously, no matter how far they are apart. This means when measuring just one entangled qubit, you can directly deduce properties of its partners without having to look.
Also, Qubit manipulation is very interesting: a normal logic gate gets a simple set of inputs and produces one definite output. A quantum gate manipulates an input of superpositions, rotates probabilities, and produces another superposition as its output. For further details check this link (https://towardsdatascience.com/demystifying-quantum-gates-one-qubit-at-a-time-54404ed80640).
So, in summary, a quantum computer sets up some qubits, applies quantum gates to entangle them and manipulate probabilities, then finally measures the outcome, collapsing superpositions to an actual sequence of 0s and 1s. What this means is that you get the entire lot of calculations that are possible with your setup, all done at the same time.
So, while quantum computers will not probably replace our home computers, in some areas, they are vastly superior: one of them is database searching.
To find something in a database, a normal computer may have to test every single one of its entries. Quantum computers algorithms need only the square root of that time. Moreover, the magnitude in data storing of quantum computing is incredible, in fact, 4 classical bits can be in one of 16 possible combinations at time. Four qubits in superposition, however, can be in all those 16 combinations at once. This number grows exponentially with each extra qubit, so 20 of them can already store a million values in parallel. This is why a 500-bit quantum computer can store more amplitudes than there are atoms in the universe.
Examples of quantum computers
In this last years companies like Google and IBM have invested highly in quantum computing. In 2019, Google built the first machine that achieved quantum supremacy, that is the first to outperform a supercomputer. Then the Jian-Wei Pan’s team at the University of Science and Technology of China has developed the world’s most powerful quantum computer, Jiuzhang, that can perform a task 100 trillion times faster than the world’s fastest supercomputer. Jiuzhang is reported to be 10 billion times faster than Google’s machine and to be able to perform calculations, that a traditional computer would take 600 million years, in just 200 seconds.
However, China has not built a fully functional quantum computer: there are lots of challenges to build a practical quantum computer. For example, the qubits must be created and stored at a temperature close to absolute zero and the computers must be isolated from atmospheric pressure and magnetic field of Earth.
Qiskit
However, if you are interested in having a first try in quantum programming now you can. Qiskit is an open-source framework that provides tools for implementing and manipulating quantum programs and running them on prototype quantum devices also on simulators on a local computer.
The primary version of Qiskit uses the Python programming language and here (https://qiskit.org/textbook/preface.html) you can find a textbook for learning how it works. Quantum computing is new and writing quantum algorithms can be very tricky, but Qiskit helps making it simpler and more visual.
“The best way to learn is by doing. Qiskit allows users to run experiments on state-of-the-art quantum devices from the comfort of their homes. The textbook teaches not only theoretical quantum computing but the experimental quantum physics that realises it.” Qiskit.org
Now, let’s try to use Qiskit by combining it with a machine learning process with the help of the textbook.
Example of quantum machine learning (QML)
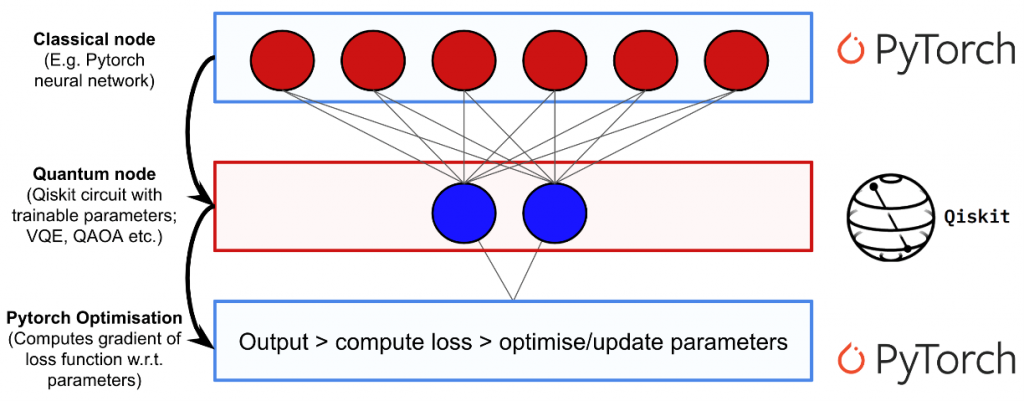
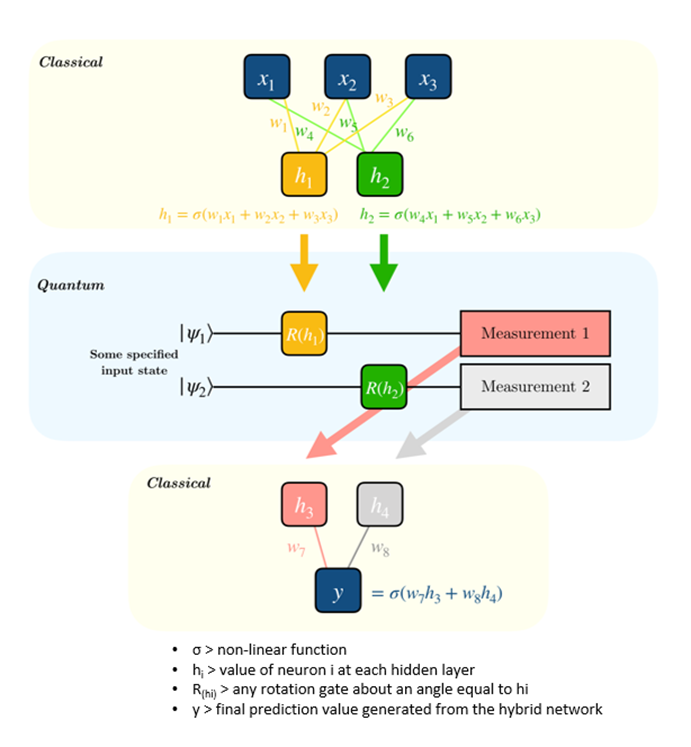
Quantum machine learning (QML) is an area of research that aims to exploit the advantages of quantum computing to enhance machine learning algorithms. In this example, we will see how to create a hybrid quantum-classical neural network on Python using PyTorch and Qiskit. To do this, we have to insert a quantum node inside a classical neural network.
The quantum node is a hidden layer of the network between two classical ones. It fits as a parameterized quantum circuit: a quantum circuit where the rotation angles for each gate are specified by the input vector of the previous classical layer. The measurements made by the quantum circuit are then collected and used as inputs for the following layer.
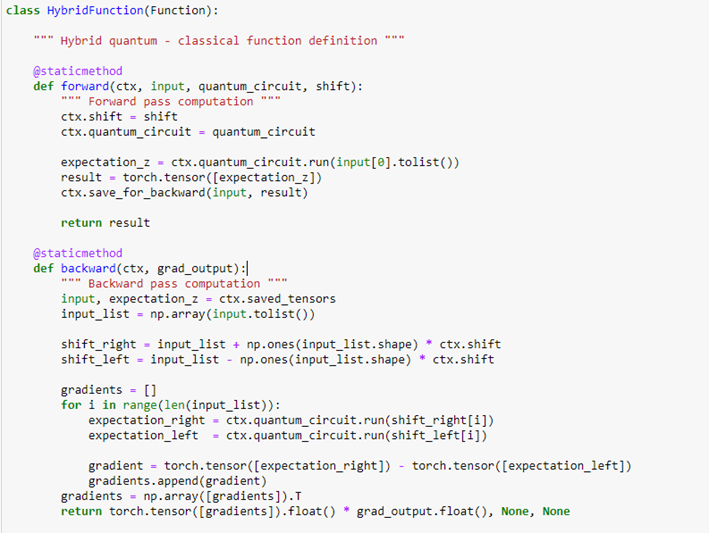
Let’s see how we can implement and test our hybrid network. First of all, we need to describe the quantum circuit, the “quantum layer” and the specific functions for the forward-propagation and back-propagation steps.
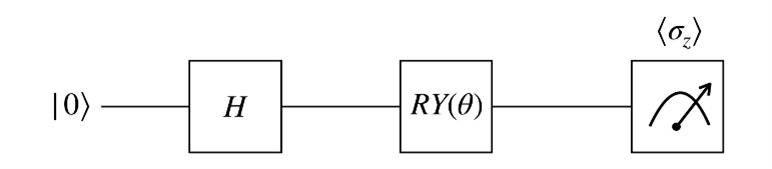
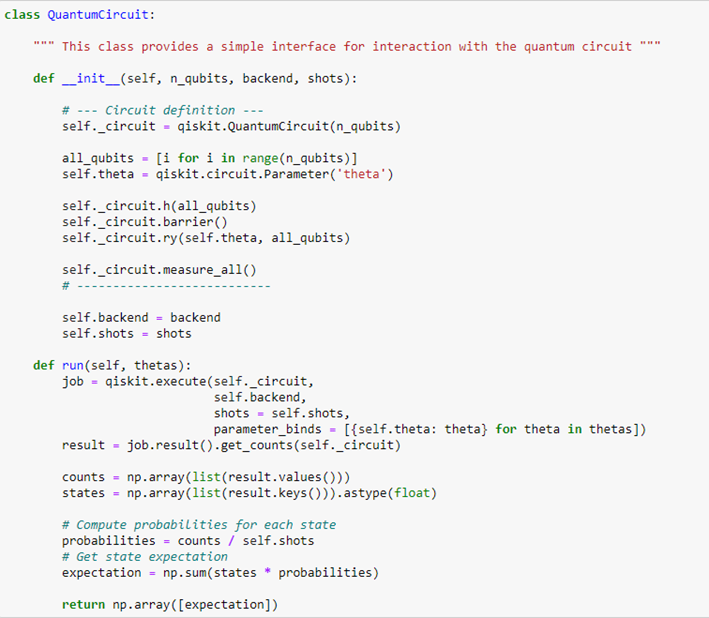
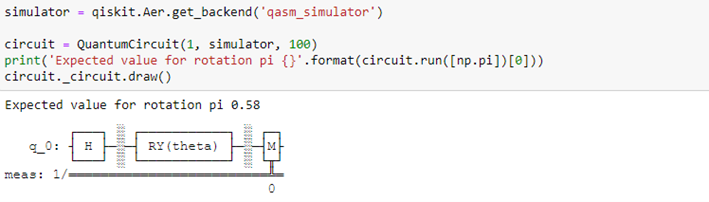
The quantum circuit is defined by the class “QuantumCircuit” using QiSkit: it requires to specify how many trainable quantum parameters and shots we want to use. In this case, for simplicity, we will use a 1-qubit circuit with one trainable quantum parameter θ and an RY−rotation by the angle θ to train its output. This last is measured in the z-basis computing the σz expectation.
The functions for forward-propagation and back-propagation are defined by the class “HybridFunction” and the quantum layer of the network is defined by the class “Hybrid“.
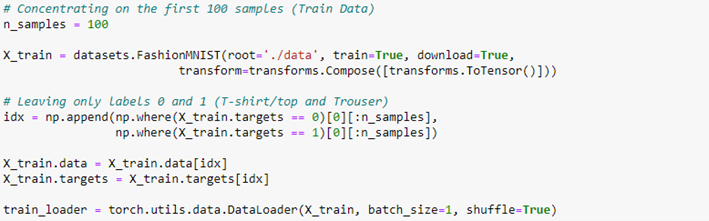
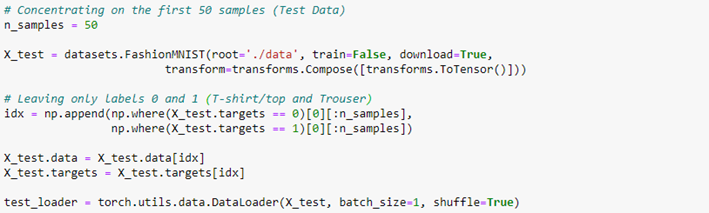
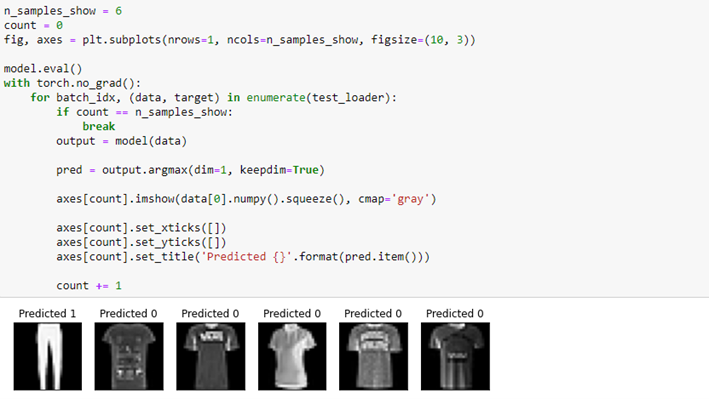
We want to develop an image classifier using the first two categories of the Fashion-MNIST dataset: T-shirt/top and Trouser. So, now we have to organize our dataset into training and test data and create our hybrid network.
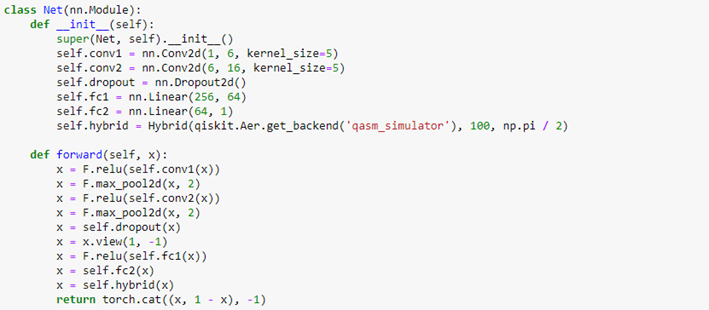
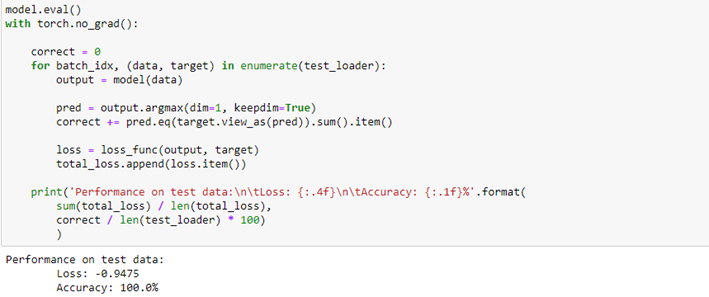
We create a simple Convolutional Neural Network consisting of two convolutional layers, one dropout layer, two fully-connected layers, and finally the quantum layer. Since our quantum circuit contains one parameter, we must ensure the network condenses neurons down to size 1, as it happens in the second fully-connected layer. The value of its last neuron is used as the parameter θ into the quantum circuit to compute the σz measurement and obtain the final prediction.
Now we have all the elements to train and test our hybrid network.
This is a simple example of what we can do using Qiskit, for the complete and editable version of the code click here (https://qiskit.org/textbook/ch-machine-learning/machine-learning-qiskit-pytorch.html).
Feynman, R. P., Leighton, R. B., Sands, M. (1965), § 1-1
Article by Carla Melia and Monica Mura, data scientists at Orbyta Srl, 11.01.2021
Matteo Malgesini
Introduci la tua esperienza professionale dall’università fino all’ingresso in ORBYTA
Ho frequentato il corso di laurea in informatica presso l’Università degli studi di Milano Bicocca. Durante gli studi ho iniziato uno stage curriculare con l’azienda sul quale poi ho scritto la tesi di laurea. Al completamento del corso di laurea sono stato assunto come consulente IT.
Di cosa ti occupi e che valore porti all’azienda?
Attualmente sono consulente presso Engineering dove mi occupo di analisi funzionale e di sviluppo software in ambito Microsoft .NET per progetti di Costa Crociere. In questo modo mi occupo dell’intero processo di creazione del software dalla raccolta e formalizzazione dei requisiti del cliente alla scrittura del codice.
Perché ti piace lavorare in ORBYTA?
Mi piace lavorare in orbyta perché è un ambiente dinamico pieno di ragazzi e ragazze della mia età. Inoltre è un’azienda in continua crescita e miglioramento.
Daniele Bosio
Racconta come è nato il progetto Basedue.
E’ nato nel 2001 per mettere a frutto l’esperienza maturata negli anni precedenti nel settore della consulenza in ambito informatico e nella gestione delle risorse umane.
Dopo la laurea in ingegneria elettronica, indirizzo informatico, e tre anni di formazione presso il centro elaborazione dati e presso l’area di progettazione reti della Olivetti di Ivrea, ho iniziato l’attività di consulenza sistemistica per conto di una delle prime software house torinesi (la famosa MesarTeam) presso l’ufficio sistemi di rete di telecomunicazioni di IVECO.
Dopo tre anni di permanenza ho cominciato a fornire servizi sempre sulle reti di telecomunicazione per altri grandi centri dell’area torinese, come Toro Assicurazioni, Real Mutua, Fiat Auto, RAI, Ferrovie dello Stato, Sema Group di Pont Saint Martin, unendo al ruolo tecnico l’attività di formazione di risorse junior, che man mano mi sostituivano nelle mansioni.
A metà degli anni 90 sono arrivato all’ufficio reti Sanpaolo di Moncalieri, nel momento in cui le reti di trasmissione dati generavano il radicale cambiamento dalla logica mainframe alla logica di informatica distribuita. Parallelamente avevo cambiato società di appartenenza, con ruoli sia amministrativi che di gestione delle risorse.
Questo per spiegare come tutte queste esperienze abbiano avuto il naturale sfogo nel creare una realtà informatica a partire dalla consulenza informatica e dalla sua gestione. A questo punto insieme ad un altro socio e amico dai tempi di Olivetti è nata Basedue.
Le attività di consulenza in Basedue servivano come punto di partenza e di “finanziamento” di altre attività progettuali e di sviluppo sempre nell’ambito reti di telecomunicazione. Basedue è cresciuta molto e negli anni a seguire è stato il primo partner scelto da Eutelsat/Skylogic per l’installazione e la diffusione della tecnologia satellitare bidirezionale di trasmissione dati; è stata azienda pilota scelta dal Csi Piemonte per conto della Regione per la creazione e lo sviluppo di reti wireless sui territori di 10 comunità montane, per colmare il cosiddetto “Digital Divide”; è stata la società che ha organizzato e realizzato la rete di connessione satellitare ad Internet per 70 rifugi alpini piemontesi (e successivamente 24 veneti).
Poi è arrivata la crisi del 2009, con la fine drastica dei finanziamenti nel settore pubblico, il resizing delle attività e dei ricavi della consulenza, la difficoltà a mantenere a pieno regime i collaboratori rispetto ai volumi di lavoro inferiori agli anni precedenti.
Le attività progettuali si sono man mano ridotte a causa della mancanza di risorse economiche che permettessero il salto da una prima fase di sviluppo prototipale e di sperimentazione verso una fase di consolidamento della produzione aziendale. L’attività di consulenza sistemistica è invece continuata nel tempo e ha dato valore alla società nel momento in cui è venuta in contatto con ORBYTA.
Quali sono i vantaggi per Basedue con l’ingresso nel Gruppo ORBYTA?
Dopo un anno e mezzo dall’ingresso di Basedue nel gruppo ORBYTA i vantaggi sono evidenti: Basedue ha potuto presentarsi presso i clienti con una veste completamente diversa, proponendo tutte le competenze del gruppo.
Le dimensioni e la solidità del gruppo vengono inoltre valutati da parte del cliente come fondamentali a garanzia di progetti di sempre maggior portata.
Inoltre Basedue si avvale internamente della parte commerciale, di selezione del personale e della gestione amministrativa con notevoli economie di scala.
In che modo la tua esperienza ha portato del valore aggiunto in ORBYTA?
Forse questo è meglio chiederlo ai miei collaboratori, ma dai risultati ottenuti penso di poter dire che la presenza per anni all’interno di gruppi di lavoro ed il rapporto di reciproca stima instaurato in anni di collaborazione con numerosi riferimenti presso il cliente, mi hanno consentito di chiarire e risolvere situazioni di difficoltà e di far emergere maggiori opportunità.
Quali sono i tuoi progetti per il futuro?
ORBYTA è veramente un bel gruppo, giovane ma con all’interno competenze di ogni genere e un’enorme capacità di innovarsi.
Finora penso di aver dato un buon contributo, sia nella fase di integrazione che per il consolidamento delle posizioni in Sanpaolo. Tuttavia le situazioni e le competenze cambiano molto rapidamente, può darsi che ben presto non sia più utile, vedremo.
A fine aprile Basedue compie 20 anni, quindi per l’imminente futuro mi preparo per festeggiare questo grande traguardo!
AMRITA
Amrita (Automatic, Maintenance, Reengineering, Integrated, Technology Application) è un prodotto progettato per il mondo mainframe, tipicamente IBM COBOL/CICS/DB2 e Cobol Microfocus, con il primario obbiettivo di fornire strumenti innovativi per ridurre drasticamente i tempi di manutenzione e comprensione del sistema informativo, oltre a dettagliate informazioni di assesment, indispensabili per la valutazione e riduzione del rischio.
La valutazione del rischio è supportata a livello decisionale, attraverso le informazioni di qualità estratte dal sistema a livello elementare successivamente riaggregate e a livello di analisi e sviluppo, dove le innumerevoli informazioni, disponibili con un click, vanno dalle generali relazioni fra i programmi fino all’istruzione elementare che ne sono origine.
Partendo dai soli codici sorgente, senza nessuna altra informazione aggiuntiva, attraverso progressivi processi di analisi, Amrita è in grado di mappare il sistema applicativo arrivando fino al dettaglio della singola istruzione. Tutti i moduli di Amrita utilizzano la stessa base dati generata in fase di analisi per fornire informazioni in tempo reale, dal livello generale fino al dettaglio elementare.
Questo processo di Assesment automatizzato, fornisce una completa comprensione dell’infrastruttura dell’applicazione e delle componenti di un ambiente mainframe. Attraverso questa tecnologia organizzazioni complesse potrebbero scoprire relazioni fra componenti del sistema che non si era consapevoli di avere, oggetti obsoleti non più utilizzati nell’ambiente mainframe e oggetti quali programmi, tabelle o altro di cui si ignorava l’esistenza.
Perseguendo i suoi obbiettivi principali, Amrita fornisce altresì una moderna piattaforma tecnologica in grado di supportare servizi di conversione, refactoring, rehosting, documentazione.
Il risultato dell’analisi sono informazioni organizzate e fruibili per ogni utilizzo e servizio del tipo
Dimensionale Di ogni programma si danno dimensioni, commenti, istruzioni di definizione dati, procedure et. Questi dati concorrono alla valorizzazione degli indici di qualità
Qualita & Metriche A livello di programma, con il dettaglio fino alla singola procedure vengono calcolati indici di complessità di McCabe, Halstead, Function Point, Fan-in, Fan-out, SQUALE, dead code etc. Gli indici di qualità concorrono alla definizione dello stato di salute dell’applicazione o di una sua componente, per identificare i programmi critici dal punto di vista strutturale, di leggibilità del programma, di modificabilità etc In particolare il sistema SQUALE, orientato ai costi di remediation e non alla qualità intrinseca, con i suoi 5 parametri di qualità, fornisce lo strumento ideale per eventuali servizi in questa area.
Violazione a regole di qualità A supporto del sistema di qualità SQUALE ma utilizzabile in generale, l’analisi del programma può fornire informazioni, a livello di dettaglio, delle violazioni ritenute pericolose per uno specifico parametro di qualità (per esempio MAINTENABILITY) Sono codificate circa 160 regole del tipo : R0085_AVOID_UNINITIALIZED_COPY_FIELD, R0094_AVOID_GOBACK_NOT_IN_MAINLINE, R0079_AVOID_UNUSED_PGM_FIELD etc R0142_AVOID_SQL_OPEN_CURSOR_INSIDE_LOOP
Ogni violazione si riferisce a una caratteristica di qualità a cui è associato un tempo di remediation e che influenza i 5 parametri di qualità generali. Questo strumento può servire al management per prendere decisioni in merito al destino dell’applicazione o ai costi per una riscrittura.
Relazioni A valle dell’analisi sono disponibili tutte le relazione fra gli oggetti del sistema, ovvero programmi, mappe video, tabelle, files di file system, codici di abend, etc, anche se originate da codice dinamico.
Where-Used Tutti gli utilizzi dei campi di moduli copy e di tabelle vengono tracciati con indicazione se in Input o Output, in quale programma e in quale istruzione di programma.
Codice Dinamico
Quando una istruzione, per esempio la call a un programma, non può essere risolta nell’istruzione stessa, in quanto il nome del programma è un campo, il contenuto effettivo viene ricercato seguendone le trasformazioni del campo nello stesso programma e nei programmi chiamati/chiamanti.
Oggetto Java
L’analisi dei programmi e dei moduli copy produce un oggetto Java serializzato con tutti i metodi disponibili per conoscere nel dettaglio: Istruzioni codificate con campi in Input/Output Dead Code Utilizzi campi nel programma Paths di esecuzione Sorgente del programma Etc L’oggetto Java serializzato, utilizzato dal modulo INSPECTOR può essere uno strumento nell’erogazione di servizi tecnici specifici.
Elenco i tipi di sorgenti analizzati:
Pgm Cobol Sono gestiti tutti i livelli di Cobol IBM e tutte le varianti del Cobol Micro Focus In generale, ai fini degli obbiettivi dell’analisi, qualsiasi tipo di Cobol viene analizzato
Copy book I moduli copy nel mondo Cobol solo assimilabili alle Include del C o di altri linguaggi. Amrita può analizzare separatamente i moduli copy o farlo durante il processo di analisi del sorgente. Vengono gestiti i copy che contengono altri copy a qualsiasi livello.
Mappe BMS Nel mondo IBM mainframe lo screen layout 80X24 si definisce con dichiarazioni in linguaggio Assembler chiamate BMS
JCL Job Control Language, si tratta del linguaggio standard di controllo di esecuzione dei programmi. Si può assimilare a Shell Script
CICS precompiler Ogni istruzione Cics viene analizzata e per quelle significative vencono generate le apposite relazioni, per esempio fra il programma sorgente e il TRANSID, MAP etc
SQL precompiler Amrita analizza nel dettaglio, codificandole, le singole istruzioni DML Sql individuando i nomi delle tabelle interessate, le colonne, il tipo di operazione e cosi via.
SQL DDL Le informazioni di definizione del database, tabelle, indici etc fanno parte integrante del processo di analisi.
A fronte dell’analisi dei sorgenti con gli analizzatori specifici, il sistema viene completamente mappato fino alla singola istruzione per ottenere relazioni fra programmi, utilizzi dei dati elementari definiti in moduli copy o tabelle Sql,
Una caratteristica importante da sottolineare è che Amrita non effettua solo l’analisi sorgenti ma è in grado di seguire le logiche elementari di trasformazione dei dati attraverso la catena di programmi chiamati/chiamanti e risolvere, quindi, istruzioni dinamiche quali call a programmi, accesso a tabelle etc.
Questo permette di avere certezza delle relazioni fra gli oggetti analizzati ed è fondamentale ai fini della manutenzione, documentazione ed, eventualmente, re-engineering.
MODULI DI AMRITA
Amrita è completamente scritto in Java, utilizza MySQL come database e la Web Application accede al db via Web Services Rest.
ANALYZER Rappresenta il motore di analisi di Amrita ed è completamente configurabile per un utilizzo semplice e intuitivo. Permette una analisi scalabile, progressiva, con visualizzazione in chiaro della progressione dell’analisi, del dettaglio analizzato, degli eventuali errori riscontrati, i tempi di analisi etc.
VIEWER Permette di visualizzare tutte le informazioni memorizzate su database in termini di oggetti, relazioni, where used, dati di qualità, di conoscere con un click chi aggiorna una tabella, un campo, etc, con contestuale visualizzazione del sorgente nel punto Una funzione specifica fornisce la matrice CRUD di quali programmi fanno Create, Read, Update e Delete di tabelle. Questo modulo assolve alla principale necessità del processo di manutenzione, riducendo i tempi di comprensione, che per sistemi Cobol sono almeno del 50%, tramite l’individuazione degli oggetti da manutenere. Con pochi click si può individuare immediatamente il programma, l’istruzione o l’area di programma su cui intervenire, le tabelle e i campi di tabella interessati.
INSPECTOR Questo modulo interviene a fronte del programma o istruzione individuato da VIEWER e permette di continuare l’analisi tecnica a livello di programma, chiamati e chiamanti. Sono disponibili funzioni per individuare i path di escuzione, verificare se variabili sono utilizzate nei path, seguire le trasformazioni del dato nel programma e nella catena di chiamati/chiamanti. Il tempo di analisi tecnica nei vecchi sistemi Cobol è di almeno il 20% del tempo di manutenzione totale.
ASSESMENT Questo modulo, a fronte dei risultati prodotti da ANALYZER, fornisce tutti i dati di qualità aggregati per sottosistema applicativo con possibilità di visualizzazione progressiva fino al dettaglio di programma, sotto forma di grafici. Lo scopo di questo modulo è di fornire una fotografia aggiornata dello stato di salute del sistema per prendere decisioni in merito a eventuali refactoring, conversioni, sostituzioni di sottosistemi o semplicemente cambiare la priorità delle attività di manutenzione.
SERVIZI E TIPOLOGIA DI UTILIZZI
Non bisogna considerare Amrita solo come uno strumento tecnico che analizza programmi e fornisce informazioni ma anche come base per servizi che è possibile erogare on demand.
I possibili utilizzi potrebbero essere:
Documentazione interattiva (VIEWER)
Documentazione per programma come pagina Web o PDF (VIEWER)
Manutenzione (VIEWER, INSPECTOR)
Pianificazione manutenzione (VIEWER, ASSESMENT)
Valutazione rischio (ASSESMENT)
Servizi (sfruttando gli output di analisi)
Assesment
Refactoring
Re-hosting
Conversioni
Ottimizzazioni
Re-engineering
Isolamento di un sottosistema Individuazione accessi diretti da un sottosistema ad un altro e sostituzione con chiamate a interfacce
IL COBOL IN ITALIA E NEL MONDO
Sembra che la quantità di Cobol ancora attivo nel mondo sia considerevole, anche se nascosto da strati e strati di software, per interfacciarlo con le nuove tecnologie e si parla di percentuali attorno al 70%.
Se liberarsi del parco applicativo Cobol è impensabile per i costi di riscrittura di sistemi spesso scritti ad hoc cuciti su misura, d’altra parte manutenere i vecchi programmi Cobol diventa problematico per mancanza di know-how, carenza di competenze e di giovani che sicuramente preferiscono imparare nuove tecnologie invece che Cobol.
In questa ottica uno strumento come Amrita potrebbe soddisfare la necessità di conoscenza applicativa, riduzione dei tempi/costi di manutenzione e del rischio. Oppure si potrebbe utilizzare Amrita come supporto alla sostituzione di un sottosistema, per costruire le interfacce verso i sottosistemi collegati, acquisire informazioni, etc.
Sicuramente ci sono realtà italiane con molto Cobol da gestire (come la PA, INPS etc.), tuttavia Il mercato è di tipo globale.
Su questo sito utilizziamo cookie tecnici necessari alla navigazione e funzionali all’erogazione del servizio. Utilizziamo i cookie anche per fornirti un’esperienza di navigazione sempre migliore, per facilitare le interazioni con le nostre funzionalità social.
Puoi esprimere il tuo consenso cliccando su ACCETTA TUTTI.
I cookie necessari sono assolutamente essenziali per il corretto funzionamento del sito web. Questi cookie garantiscono le funzionalità di base e le caratteristiche di sicurezza del sito web, in modo anonimo.
Cookie
Durata
Descrizione
__hssrc
session
This cookie is set by Hubspot whenever it changes the session cookie. The __hssrc cookie set to 1 indicates that the user has restarted the browser, and if the cookie does not exist, it is assumed to be a new session.
cookielawinfo-checkbox-analytics
11 months
Questo cookie è impostato dal plug-in GDPR Cookie Consent. Il cookie viene utilizzato per memorizzare il consenso dell'utente per i cookie nella categoria "Analytics".
cookielawinfo-checkbox-functional
11 months
Il cookie è impostato dal consenso cookie GDPR per registrare il consenso dell'utente per i cookie nella categoria "Funzionali".
cookielawinfo-checkbox-necessary
11 months
Questo cookie è impostato dal plug-in GDPR Cookie Consent. I cookie vengono utilizzati per memorizzare il consenso dell'utente per i cookie nella categoria "Necessari".
cookielawinfo-checkbox-others
11 months
Questo cookie è impostato dal plug-in GDPR Cookie Consent. Il cookie viene utilizzato per memorizzare il consenso dell'utente per i cookie nella categoria "Altri.
cookielawinfo-checkbox-performance
11 months
Questo cookie è impostato dal plug-in GDPR Cookie Consent. Il cookie viene utilizzato per memorizzare il consenso dell'utente per i cookie nella categoria "Prestazioni".
JSESSIONID
session
Utilizzato da siti scritti in JSP. Cookie di sessione della piattaforma per scopi generici che vengono utilizzati per mantenere lo stato degli utenti attraverso le richieste di pagina.
viewed_cookie_policy
11 months
Il cookie è impostato dal plug-in GDPR Cookie Consent e viene utilizzato per memorizzare se l'utente ha acconsentito o meno all'uso dei cookie. Non memorizza alcun dato personale.
I cookie funzionali aiutano a eseguire determinate funzionalità come condividere il contenuto del sito Web su piattaforme di social media, raccogliere feedback e altre funzionalità di terze parti.
Cookie
Durata
Descrizione
__cf_bm
30 minutes
Questo cookie, impostato da Cloudflare, viene utilizzato per supportare la gestione dei bot di Cloudflare.
__hssc
30 minutes
HubSpot imposta questo cookie per tenere traccia delle sessioni e per determinare se HubSpot deve incrementare il numero di sessione e i timestamp nel cookie __hstc.
bcookie
2 years
LinkedIn imposta questo cookie dai pulsanti di condivisione di LinkedIn e aggiunge tag per riconoscere l'ID del browser.
lang
session
Questo cookie viene utilizzato per memorizzare le preferenze di lingua di un utente per fornire contenuti in quella lingua memorizzata la prossima volta che l'utente visita il sito web.
lidc
1 day
LinkedIn imposta il cookie lidc per facilitare la selezione del data center.
I cookie per le prestazioni vengono utilizzati per comprendere e analizzare gli indici di prestazioni chiave del sito Web che aiutano a fornire una migliore esperienza utente per i visitatori.
I cookie analitici vengono utilizzati per capire come i visitatori interagiscono con il sito web. Questi cookie aiutano a fornire informazioni sulle metriche del numero di visitatori, della frequenza di rimbalzo, della sorgente del traffico, ecc.
Cookie
Durata
Descrizione
__hstc
1 year 24 days
This is the main cookie set by Hubspot, for tracking visitors. It contains the domain, initial timestamp (first visit), last timestamp (last visit), current timestamp (this visit), and session number (increments for each subsequent session).
_ga
2 years
Il cookie _ga, installato da Google Analytics, calcola i dati di visitatori, sessioni e campagne e tiene anche traccia dell'utilizzo del sito per il report di analisi del sito. Il cookie memorizza le informazioni in modo anonimo e assegna un numero generato casualmente per riconoscere i visitatori unici.
_gat_gtag_UA_162571803_1
1 minute
This cookie is set by Google and is used to distinguish users.
_gid
1 day
Installato da Google Analytics, il cookie _gid memorizza informazioni su come i visitatori utilizzano un sito web, creando anche un report analitico delle prestazioni del sito web. Alcuni dei dati raccolti includono il numero di visitatori, la loro fonte e le pagine che visitano in modo anonimo.
CONSENT
16 years 3 months 10 days 7 hours 5 minutes
Questi cookie vengono impostati tramite video di YouTube incorporati. Registrano dati statistici anonimi su ad esempio quante volte viene visualizzato il video e quali impostazioni vengono utilizzate per la riproduzione. Nessun dato sensibile viene raccolto a meno che non accedi al tuo account google, in tal caso le tue scelte sono legate al tuo account, ad esempio se fai clic su "mi piace" su un video.
hubspotutk
1 year 24 days
Questo cookie viene utilizzato da HubSpot per tenere traccia dei visitatori del sito web. Questo cookie viene passato a Hubspot all'invio del modulo e utilizzato durante la deduplicazione dei contatti.
I cookie pubblicitari vengono utilizzati per fornire ai visitatori annunci e campagne di marketing pertinenti. Questi cookie tengono traccia dei visitatori sui siti Web e raccolgono informazioni per fornire annunci personalizzati.
Cookie
Durata
Descrizione
bscookie
2 years
Questo cookie è un cookie ID del browser impostato dai pulsanti di condivisione collegati e dai tag degli annunci.
IDE
1 year 24 days
I cookie di Google DoubleClick IDE vengono utilizzati per memorizzare informazioni su come l'utente utilizza il sito Web per presentargli annunci pertinenti e in base al profilo dell'utente.
test_cookie
15 minutes
Il test_cookie è impostato da doubleclick.net e viene utilizzato per determinare se il browser dell'utente supporta i cookie.
VISITOR_INFO1_LIVE
5 months 27 days
Un cookie impostato da YouTube per misurare la larghezza di banda che determina se l'utente ottiene la nuova o la vecchia interfaccia del lettore.
YSC
session
Il cookie YSC è impostato da Youtube e viene utilizzato per tenere traccia delle visualizzazioni dei video incorporati nelle pagine di Youtube.
yt-remote-connected-devices
never
YouTube imposta questo cookie per memorizzare le preferenze video dell'utente utilizzando il video YouTube incorporato.
yt-remote-device-id
never
YouTube imposta questo cookie per memorizzare le preferenze video dell'utente utilizzando il video YouTube incorporato.
yt.innertube::nextId
never
Questi cookie vengono impostati tramite video di YouTube incorporati.
yt.innertube::requests
never
These cookies are set via embedded youtube-videos.