Recommender systems: principali metodologie degli algoritmi di suggerimento
Vi siete mai chiesti come faccia Netflix a suggerirvi il tipo di film adatto a voi? O Amazon a mostrarvi l’articolo di cui avevate bisogno? O come mai, le pubblicità che vi appaiono nei siti web facciano riferimento a qualcosa di vostro interesse? Questi sono solo alcuni esempi di un tipo di algoritmi che vengono oggigiorno usati dalla maggior parte dei siti web e dalle applicazioni per fornire agli utenti dei suggerimenti personalizzati, si tratta dei sistemi di raccomandazione.
In questo articolo scopriremo cosa sono, con quali metodi vengono implementati e come vengono valutate le loro performance.
Cosa sono i sistemi di raccomandazione
I sistemi di raccomandazione sono un tipo di sistemi di filtraggio dei contenuti. Possono essere descritti come degli algoritmi che hanno lo scopo di suggerire all’utente di un sito web o di un’applicazione degli articoli che possano risultare di suo interesse. Davanti ad una serie di prodotti devono essere in grado di selezionare e proporre quelli più adatti per ogni utente, quindi di fornire dei suggerimenti personalizzati.
Questo tipo di algoritmi vengono utilizzati in svariati settori. Gli esempi più evidenti possono essere quelli già citati all’inizio dell’articolo quindi nei servizi di e-commerce (es. Amazon), nei servizi di streaming di film, video o musica (es. Netflix, YouTube, Spotify), ma anche nelle piattaforme social (es. Instagram), nei servizi di delivery (es. Uber Eats) e così via. In generale, ogni qualvolta ci sia la possibilità di suggerire ad un utente un contenuto, può essere utilizzato un sistema di raccomandazione per renderlo specifico per l’utente stesso.
Come vengono implementati
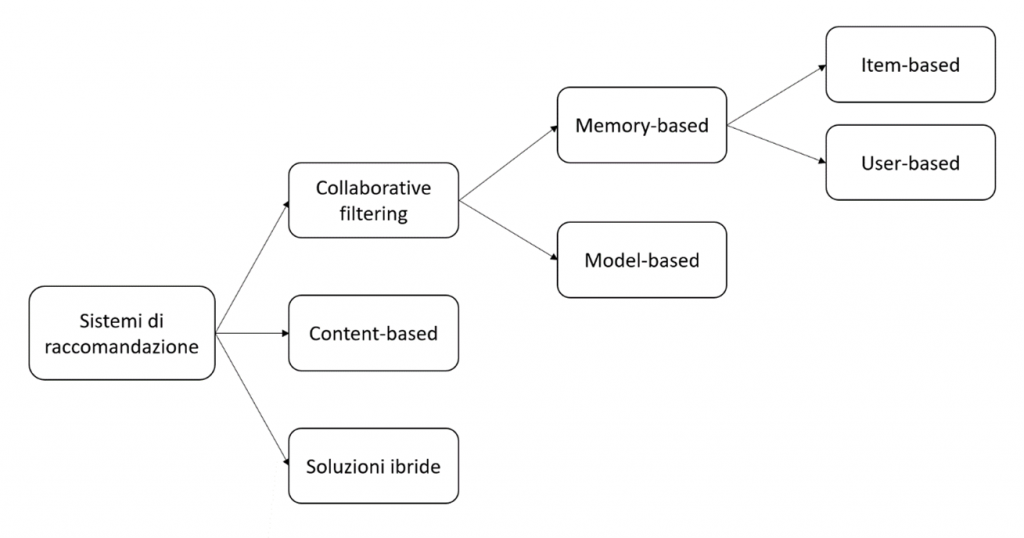
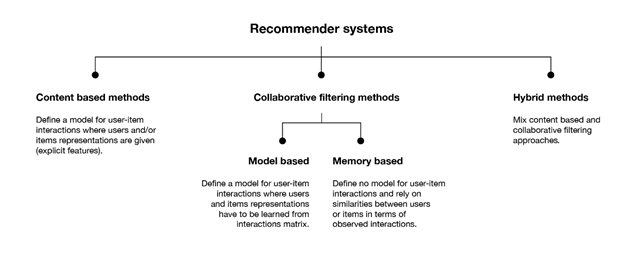
I sistemi di raccomandazione possono essere suddivisi principalmente in due macrocategorie: metodi collaborative filtering e metodi content-based. Inoltre, questi due approcci possono essere combinati per dare origine a delle soluzioni ibride che sfruttano i vantaggi di entrambi.
Metodi collaborative filtering
I sistemi di raccomandazione collaborative filtering utilizzano le interazioni avvenute tra utenti e articoli in passato per costruire la cosiddetta matrice di interazione utenti-articoli e da questa estrarre i nuovi suggerimenti. Si basano sull’assunzione che queste interazioni siano sufficienti per riconoscere gli utenti e/o gli articoli simili fra loro e che si possano fare delle predizioni concentrandosi su queste similarità.
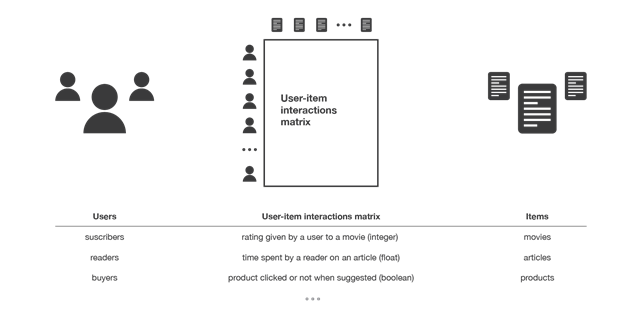
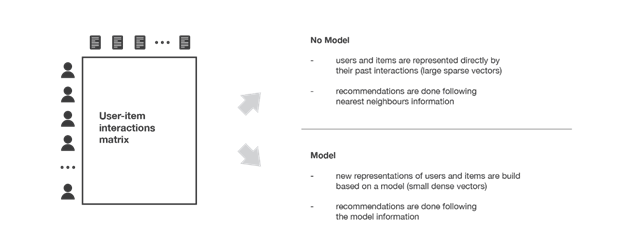
Questa classe di metodi si divide a sua volta in due sottocategorie, sulla base della tecnica utilizzata per individuare le similarità tra gli utenti e/o gli articoli: metodi memory-based e metodi model-based. I primi utilizzano direttamente i valori contenuti nella matrice di interazione utenti-articoli per ricercare “il vicinato” dell’utente o dell’articolo target, i secondi assumono che dai valori della matrice sia possibile estrarre un modello con cui effettuare le nuove predizioni.
Il vantaggio principale dei metodi collaborative filtering è dato dal fatto che non richiedono l’estrazione di informazioni sugli utenti o sugli articoli dunque possono essere utilizzati in svariati contesti. Inoltre, più gli utenti interagiscono con gli articoli, maggiori informazioni si avranno a disposizione e più le nuove raccomandazioni saranno accurate.
Il loro svantaggio emerge nel momento in cui si hanno nuovi utenti o nuovi articoli perché non ci sono informazioni passate sulle loro interazioni, questa situazione viene definita cold start problem. In questo caso per stabilire quali debbano essere le nuove raccomandazioni si sfruttano diverse tecniche: si raccomandano articoli scelti casualmente ai nuovi utenti o nuovi articoli ad utenti scelti casualmente, si raccomandano articoli popolari ai nuovi utenti o nuovi articoli agli utenti più attivi, si raccomandano un set di vari articoli ai nuovi utenti o un nuovo articolo ad un set di vari utenti, oppure, si evita di utilizzare un approccio collaborative filtering in questa fase.
Metodi memory-based
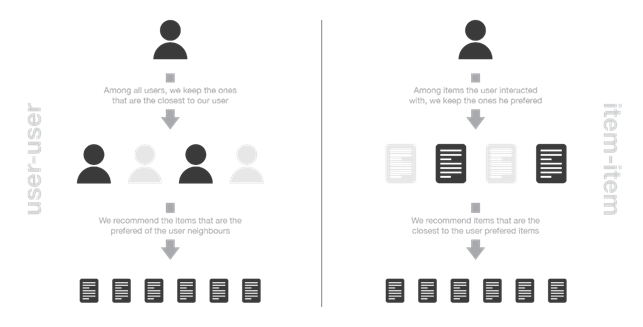
I metodi memory-based si possono a loro volta suddividere in metodi user-based e metodi item-based.
I metodi user-based rappresentano gli utenti considerando le loro interazioni con gli articoli e sulla base di questo valutano la similarità tra un utente e l’altro. In generale, due utenti sono considerati simili se hanno interagito con tanti articoli allo stesso modo. Per fare una nuova raccomandazione ad un utente si cerca di identificare quelli con i “profili di interazione” più simili al suo, in modo tale da suggerirgli gli articoli più popolari tra il suo vicinato.
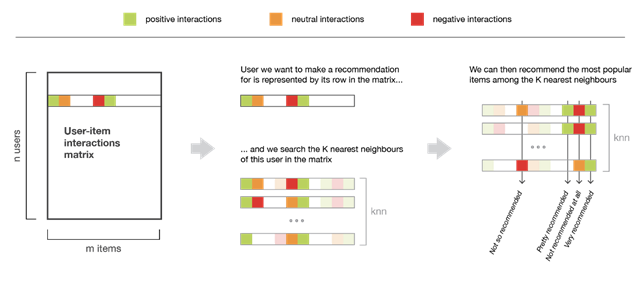
Un esempio di applicazione del metodo user-based viene utilizzato da Youtube per suggerirci i video presenti nella nostra Homepage.
I metodi item-based rappresentano gli articoli basandosi sulle interazioni che gli utenti hanno avuto con loro. Due articoli vengono considerati simili se la maggior parte degli utenti che ha interagito con entrambi lo ha fatto allo stesso modo. Per fare una nuova raccomandazione ad un utente, questi metodi cercano articoli simili a quelli con la quale l’utente ha interagito positivamente.
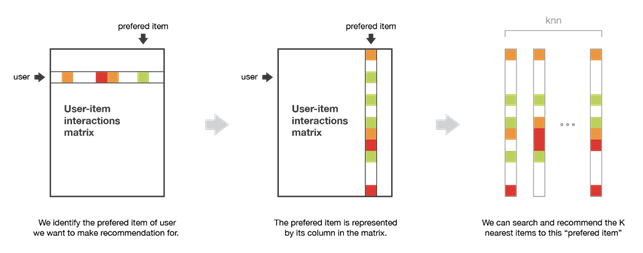
Un esempio di applicazione del metodo item-based viene utilizzato da Amazon quando clicchiamo su un articolo e ci appare la sezione “i clienti che hanno visto questo articolo hanno visto anche” mostrandoci altri articoli simili a quello che abbiamo selezionato.
Uno degli svantaggi dei metodi memory-based è il fatto che la ricerca del vicinato può richiedere molto tempo su grandi quantità di dati, quindi deve essere implementata attentamente e nel modo più efficiente possibile. Inoltre, bisogna evitare che il sistema raccomandi solo gli articoli più popolari e che agli utenti vengano suggeriti solo articoli molto simili a quelli che gli sono piaciuti in passato, deve essere in grado di garantire una certa diversità nei suggerimenti effettuati.
Metodi model-based
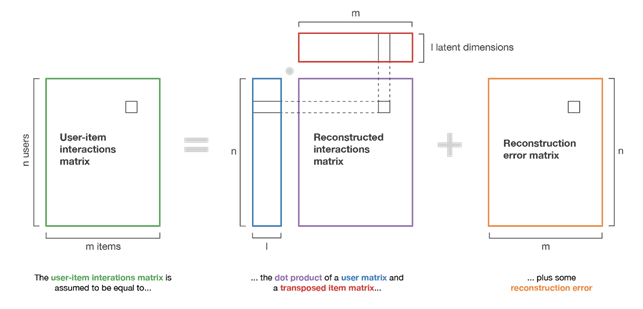
I metodi model-based si basano sull’assunzione che le interazioni tra articoli e utenti possano essere spiegate tramite un modello “nascosto”.
Un esempio di algoritmo per l’estrazione del modello è la matrix-factorization, questo consiste sostanzialmente nella decomposizione della matrice di interazione utenti-articoli nel prodotto di due sottomatrici, una contenente la rappresentazione degli utenti e l’altra la rappresentazione degli articoli. Utenti simili in termini di preferenze e articoli simili in termini di caratteristiche avranno delle rappresentazioni simili nelle nuove matrici.
Metodi content-based
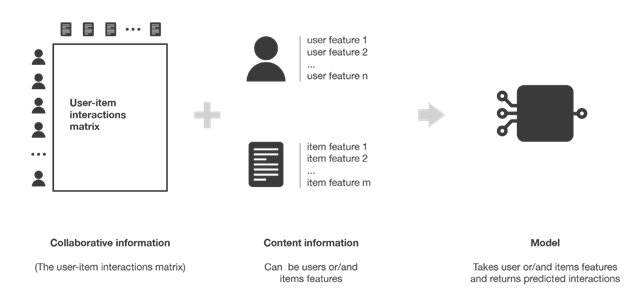
A differenza dei sistemi di raccomandazione collaborative filtering che si basano solo sull’interazione tra utenti e articoli, i sistemi di raccomandazione content-based ricercano delle informazioni aggiuntive.
Supponiamo di avere un sistema di raccomandazione che deve occuparsi di suggerire film agli utenti, in questo caso le informazioni aggiuntive potrebbero essere l’età, il sesso e il lavoro per gli utenti così come la categoria, gli attori principali e il regista per i film.
I metodi content-based cercano di costruire un modello che sappia spiegare la matrice di interazione utenti-articoli basandosi sulle features disponibili per gli utenti e gli articoli.
Dunque, considerando l’esempio precedente, si cerca il modello che spieghi come ad utenti con certe features piacciano film con altrettante features. Una volta che questo modello è stato ottenuto, fare delle predizioni per un nuovo utente è facile, basta considerare le sue features e di conseguenza verranno fatte le nuove predizioni.
Nei metodi content-based il problema di raccomandazione viene trattato come un problema di classificazione (predire se ad un utente possa piacere o meno un articolo) o di regressione (predire il voto che un utente assegnerebbe ad un articolo).
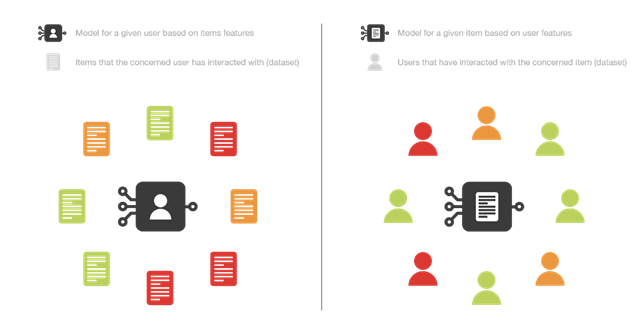
In entrambi i casi il problema si può basare sulle features dell’utente (metodo item-centred), o sulle features dell’articolo (metodo user-centred). Nel primo caso si costruisce un modello per articolo cercando di capire qual è la probabilità che ad ogni utente piaccia quell’ articolo, nel secondo caso si costruisce un modello per utente per capire qual è la probabilità che a quell’utente piacciano gli articoli a disposizione. In alternativa si può anche valutare un modello che contenga sia le features degli utenti che quelle degli articoli.
Il vantaggio dei metodi content-based è che non soffrono del cold start problem perché i nuovi utenti e i nuovi articoli sono definiti dalle loro features e le raccomandazioni vengono fatte sulla base di queste.
Come vengono valutati
Per valutare le performance di un sistema di raccomandazione, quindi per cercare di capire se le raccomandazioni che sta effettuando sono appropriate, vengono utilizzati principalmente tre tipi di valutazioni: user studies, la valutazione online e la valutazione offline.
La valutazione user studies prevede di proporre agli utenti delle raccomandazioni effettuate da diversi sistemi di raccomandazione e di chiedergli di valutare quali raccomandazioni ritengono migliori.
La valutazione online, chiamata anche A/B test, prevede di proporre agli utenti in real-time diverse raccomandazioni per poter valutare quali sono quelle che ottengono più “click”.
La valutazione offline prevede di fare delle simulazioni sul comportamento degli utenti partendo dai dataset passati che si hanno a disposizione.
Condividi tramite