I vantaggi di un Message Broker nelle moderne architetture distribuite (con riferimenti a RabbitMQ)
Le architetture moderne si stanno sviluppando in una direzione fortemente decentralizzata (si pensi a quanti software oggigiorno vengano progettati in un’ottica di microservizi, o come la distribuzione del consenso sia il cardine di un intero nuovo filone tecnologico quali le blockchain e le criptovalute). Non è in realtà un argomento nuovo nel mondo dell’informatica, già nei giorni della sua creazione nel 1969, il sistema operativo UNIX dovette operare una scelta nel disegno del kernel fra un approccio monolitico (struttura che oggi chiameremmo centralizzata) e uno a microkernel (decisamente prossimo al concetto di decentralizzato). Poiché nessuno dei due approcci presenta solo vantaggi, come spesso accade, si è assistito a guerre di religione in proposito, dove non sono mancati tentativi di compromesso con architetture kernel-ibride (ossia gli attuali Windows e MacOS). Al momento uno dei requisiti su cui si pone maggiore attenzione è fornire sempre e comunque un risultato, senza per questo doversi affidare unicamente alla replicazione di intere strutture hardware e software per garantire la continuità servizio. Dividere quello che un tempo era un singolo servizio su N microservizi porta una serie indubbia di vantaggi:
- maggiore facilità nella scalabilità: trattandosi di un’attività micro è ragionevole pensare che possa essere avviata e replicata molto in fretta (approccio che vede il suo attuale apice nei docker e in kubernates);
- maggiore manutenibilità del software: è di nuovo ragionevole pensare che un microservizio faccia un numero veramente ridotto di attività, portando vantaggi nella scrittura, nel testing e nel bug fixing;
- elevato disaccoppiamento dei processi: ognuno, almeno in teoria, dovrebbe poter vivere di vita propria attendendo richieste a cui dare risposta, disinteressandosi del sistema macroscopico in cui è stato inserito;
- minore impatto in caso di disservizio: se un microservizio non fosse disponibile questo non impatterebbe sul resto del sistema che continuerebbe a fornire risposta (sebbene magari solo parziale).
Questi solo per elencare i principali. C’è però un ovvio rovescio della medaglia: per quanto sarebbe perfetto poter disegnare un’architettura in cui ogni componente non ha mai necessità di scambio dati con gli altri, questo non si rivela possibile nella pratica. Ogni componente è costantemente interessato in uno scambio di informazioni con gli altri. Il colloquio fra i diversi processi (o moduli) può essere affrontato in svariati modi:
Per fare un’analogia, potremmo pensare ai due estremi: RPC e MOM. Il primo è l’equivalente di un messaggero medievale, istruito dal proprio committente sui tempi e le modalità con cui un messaggio accuratamente preparato e sigillato dovrà essere recapitato, ed eventualmente fornito di una scorta più o meno numerosa che possa garantire la sicurezza della missiva da consegnare. Sicuramente, essendo ogni aspetto curato e calibrato sull’importanza del messaggio, da ogni comunicazione otterremo il massimo dell’efficienza e dell’affidabilità, a fronte di un dispendio di energie e risorse notevole. Il secondo è più simile ad un ufficio postale, a cui affidiamo il nostro messaggio con un numero minimo di istruzioni a riguardo, a cui assegniamo una priorità e eventuali istruzioni per una notifica di recapito. Non ci si cura di altri aspetti, sapendo che l’ufficio postale è sicuro e affidabile (se non dovessimo fidarci delle poste potremmo sempre affidarci ad altri corrieri volendo). I Message Broker sono i software che implementano il paradigma MOM e forniscono tutti i servizi (in forma di API) necessari alla distribuzione di messaggi, definendo al loro interno le strutture necessarie a definire le rotte di instradamento e le politiche di recapito. Uno dei più vecchi software di questo tipo è IBM MQ, nato nel 1993, mentre ai giorni nostri i sistemi più diffusi sono RabbitMQ e Kafka. I sistemi collocati all’interno dei Cloud possiedono ovviamente le proprie versioni gestite, abbiamo ad esempio Azure Service Bus fornito da Microsoft e Simple Queue Service fornito da Amazon. Fondamentalmente tutti questi sistemi offrono le medesime funzionalità, sebbene le specifiche implementazioni presentino punti deboli e punti forti rispetto ai contesti iniziali in cui sono stati concepiti. Giusto per fare un esempio:
Il paradigma MOM
Poste queste indicazioni di massima, possiamo però definire quelli che sono i capi saldi del paradigma MOM:
Con questi due semplici oggetti, è possibile costruire topologie in cui la comunicazione avviene punto-punto (tra mittente e destinatario è presente una coda) oppure punto-multipunto (in cui un mittente inoltra un messaggio ad un nodo, e questo lo distribuisce a tutti i sottoscrittori collegati). Punto di forza di questi sistemi è la possibilità di definire delle politiche di sottoscrizione ai nodi. I nodi più semplici, di base, replicano il medesimo messaggio a tutti i sottoscrittori, ma impostando delle regole, ed eventualmente ponendo dei nodi in cascata, è possibile recapitare i messaggi con certe caratteristiche ai sottoscrittori che le hanno richieste. Vediamo alcuni esempi per chiarire tutti questi concetti.
Creazione di una coda in RabbitMQ (in C#)
Nel classico paradigma Produttore/Consumatore immaginiamo di voler mettere in collegamento le due entità grazie a RabbitMQ. Lo strumento adottato è la Coda.

Il produttore deve semplicemente inserire il messaggio nella coda, e confidare nella bontà di RabbitMQ. La coda conserverà i messaggi fintanto che il consumatore non avrà la possibilità di prenderli in carico, fornendo implicitamente un meccanismo persistente di gestione dei dati. La lettura dei messaggi può avvenire in modo:
Proprietà della coda
La coda può essere definita con una serie di proprietà:
Il codice necessario per implementare questo dialogo punto-punto prevede la creazione di un metodo di spedizione (che chiameremo Send) e uno di ricezione (analogamente Receive):
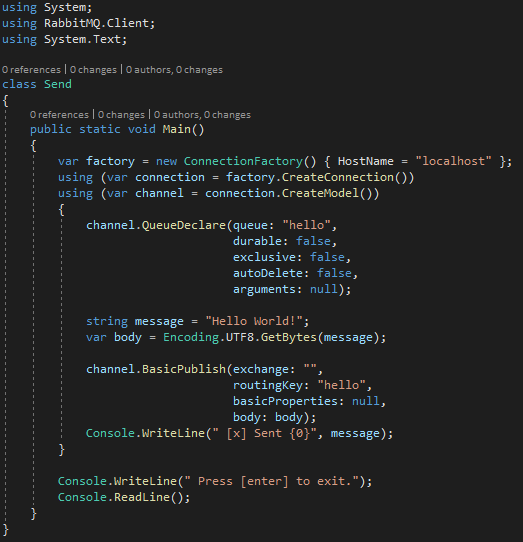
Punti di interesse di questo codice sono la factory, ossia la classe fornita dalla libreria RabbitMQ .NET per la creazione e la gestione del servizio. È sufficiente indicare l’indirizzo del server su cui RabbitMQ è in funzione, ed è possibile aggiungere i classici dati generali quali user e password (N.B. se RabbitMQ è installato in localhost, non è necessario nulla per poter funzionare oltre all’HostName, ma se ci si collega da remoto è indispensabile creare un utente, dal momento che l’utente di default è abilitato alle API solo se queste richieste provengono dal sistema locale). Una volta ottenuta la factory, è possibile usarla per creare una connection, ovvero aprire una connessione TCP per dialogare con RabbitMQ. Attraverso la connection possiamo creare un model, esso rappresenta il collegamento verso le strutture interne di RabbitMQ. Possiamo pensare alle due entità in questo modo:
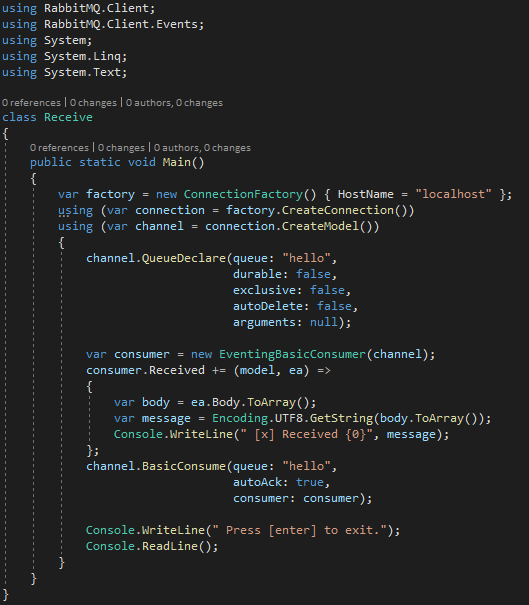
La flessibilità è totale, ma le best practice consigliano di creare una sola connection verso RabbitMQ da tenere attiva il più a lungo possibile, mentre di creare i model al bisogno quando si vuole spedire. Nulla vieta di mantenere un model per un tempo indefinito, specie se si avesse un traffico continuo e l’overhead di creazione e distruzione del model fosse eccessivo. Una volta ottenuto il model è possibile creare o collegarsi ad una coda. Una coda deve avere un nome univoco e una serie di caratteristiche che possono essere definite alla creazione, e devono coincidere per chiunque intenda collegarcisi sia in spedizione che in ricezione. L’invio del messaggio avviene semplicemente attraverso il metodo BasicPublish, a cui è normalmente sufficiente fornire il messaggio sotto forma di byte array. Gli altri elementi del BasicPublish li vedremo tra poco nel prossimo esempio. Il Receive invece verrà scritto in questo modo:
I punti di interesse in questo caso sono due: la registrazione dell’EventingBasicConsumer, ossia il gestore a cui sarà legato l’evento di ricezione e il metodo da invocare ogni qual volta la coda notificherà la presenza di un nuovo messaggio; il metodo BasicConsume, in cui è possibile definire una peculiarità del ricevente: quando il messaggio viene notificato è possibile stabilire due momenti differenti in cui confermare la rimozione di quest’ultimo dalla coda:

È possibile, mettere più consumatori in concorrenza sulla medesima coda, in questo caso RabbitMQ notificherà ai consumatori rispetto ai parametri che questi hanno impostato. Tipicamente, in presenza di Ack impliciti, la risoluzione avviene in round robin sui consumatori. Se invece gli Ack sono espliciti, possiamo andare a definire il BasicQos (Quality of Service).channel.BasicQos(prefetchSize: 0, prefetchCount: 1, global: false);Aggiungendo questa istruzione dopo la QueueDeclare è possibile definire a livello globale (qualora si voglia fornire questi parametri a tutti i model) o solo al model specifico che sta invocando il metodo BasicQos, due parametri: il prefetchSize e il prefetchCount.
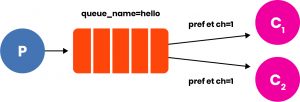
Per inviare un Ack esplicito, normalmente al termine del metodo usato come handler del consumer.Received si ponechannel.BasicAck(deliveryTag: ea.DeliveryTag, multiple: false); In cui il DeliveryTag indica il messaggio per cui si sta notificando l’Ack, mentre il flag seguente serve a gestire le politiche di rimozione, ossia se un messaggio debba essere rimosso subito alla prima notifica oppure se debba essere recapitato a tutti i consumatori, pertanto fin quando non sarà ricevuto un numero di Ack pari al numero di consumatori collegati (o un Ack che non richieda ulteriori attese), il messaggio resterà in coda (fatte salve eventuali politiche legate al TTL). Sarà compito di RabbitMQ notificare un nuovo messaggio coerentemente con le politiche impostate a ciascun consumatore. Se ad esempio C1 e C2 debbono entrambi processare gli stessi messaggi, ma C1 è molto più veloce di C2, avremo che per ogni nuovo messaggio, C1 riceverà una notifica coerente con la sua impostazione di prefetch, e i messaggi gli verranno inoltrati non soltanto dalla testa della coda, dove sono presenti messaggi a lui già recapitati che sono in attesa di essere notificati anche a C2 o che semplicemente sono ancora in attesa di un Ack. È importante notare come tutta questa gestione sarebbe normalmente molto complessa, ma viene compresa tra le comuni configurazioni di base di RabbitMQ che fornisce questo scenario senza alcuno sforzo o degrado di performance.
Creazione di un nodo di distribuzione in RabbitMQ (in C#)
Molto più interessante è la possibilità di creare nodi di distribuzione (chiamati Exchange) e definirne le politiche di instradamento. È giusto svelare che le immagini viste poco fa sono in realtà la concettualizzazione della comunicazione punto-punto, ma nella realtà le implementazioni prevedono tutte l’introduzione di un nodo di distribuzione tra il produttore e la coda di consegna. Da notare quindi, in riferimento al precedente Send, che quelle due proprietà lasciate un attimo in sospeso (exchange: “”, routingKey: “hello”) vanno ad indicare che non abbiamo dato un nome all’exchange (sebbene esista per costruzione, ma di cui ci disinteressiamo in quanto parte del funzionamento interno di RabbitMQ) e opzionalmente una routingKey. Tale routingKey è inutile nell’esempio ma ci permette di dire che volendo possiamo precisare al consumatore che deve conoscere la routingKey dei messaggi per poterli ascoltare, e anche se non rappresenta un meccanismo di sicurezza, è utile definirne sempre una per evitare errori e non veder recapitati messaggi sbagliati ad un consumatore che stiamo testando.
Quel nodo, chiamato Exchange, diventa molto importante qualora la distribuzione non sia su una coda soltanto, ma su una serie di Subscriber, vengono infatti chiamati sottoscrittori i consumatori che collegano una coda ad un nodo di distribuzione. I nodi in RabbitMQ sono di 4 tipi, e bene o male ritroviamo concetti analoghi in altri software, anche se con nomi differenti:
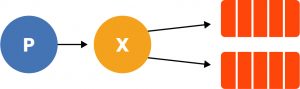
Facendo un esempio analogo al precedente, avremo un produttore fatto in questo modo:
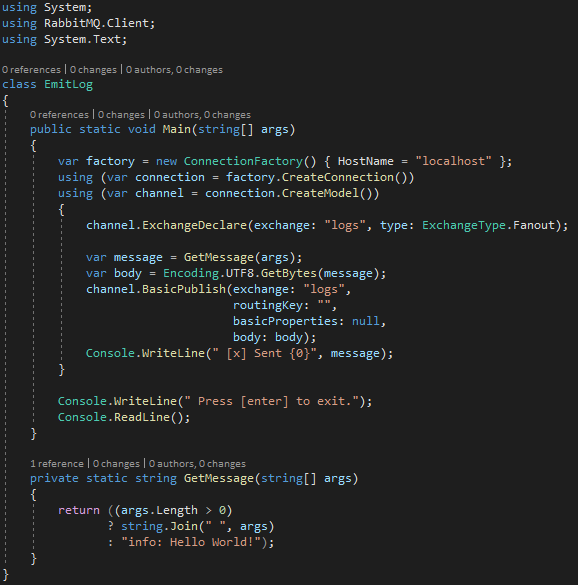
In sostanza l’unica differenza consiste nell’uso di ExchangeDeclare in sostituzione al QueueDeclare. Uno dei sottoscrittori invece, avrà questa forma:
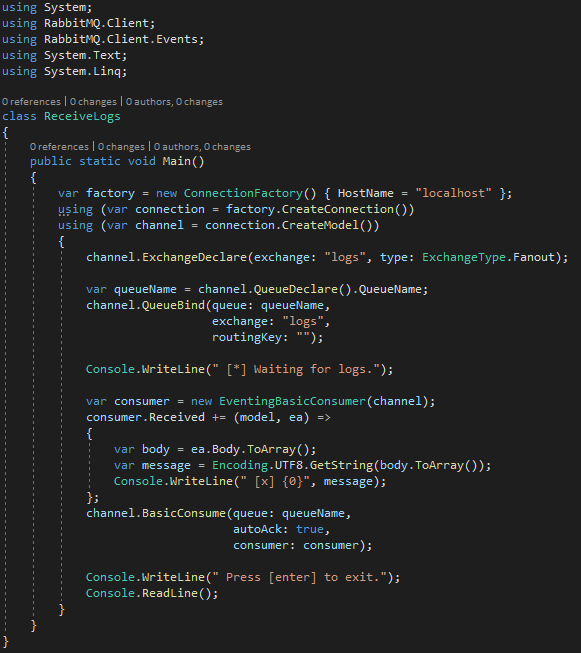
I punti di interesse qui sono i seguenti:
Il sottoscrittore collega la coda appena creata al nodo (con l’operazione di QueueBind). In questo modo andiamo a disegnare la struttura della rete che poi useremo per la distribuzione dei messaggi. In particolare in RabbitMQ si osservi che il QueueBind va ripetuto per ogni RoutingKey che si vuole ricevere su quella sottoscrizione, mentre altri broker consentono sottoscrizioni multikey (passando ad esempio degli array di string).
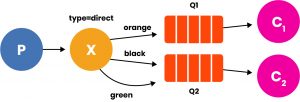
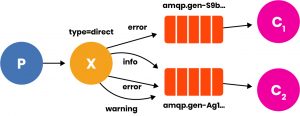
Questa potrebbe, ad esempio, essere la topologia di un sistema di log differenziato per livello. E infine un esempio di Topic, in cui lo smistamento avviene per mezzo di caratteri speciali:
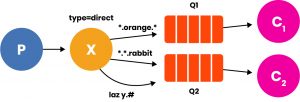
In RabbitMQ abbiamo che:
Adottando questi caratteri speciali con questi significati, per costruzione le Routing Key prendono la forma di frasi separate da punto.
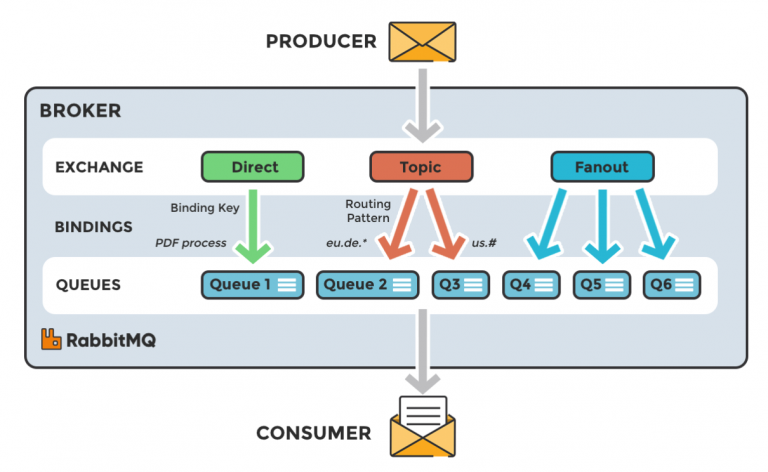
Infine, volendo schematizzare un exchange di tipo header è bene precisare che l’estrema potenza nella definizione delle regole di instradamento si paga con un degrado del throughput finale del sistema.
Parlando di prestazioni
Ogni message broker ha punti di forza su cui cerca di fare leva per guadagnarsi una posizione di rilievo in uno specifico settore. Kafka punta sul numero di messaggi trasmessi, ActiveMQ punta ad essere il compromesso migliore tra dimensione dei messaggi, numeri di messaggi e latenza complessiva senza eccellere in nulla, RabbitMQ punta sulla estrema flessibilità della sua capacità di routing senza che questa impatti troppo sul risultato finale. Prima di adottare uno di questi è sempre bene documentarsi e cercare i benchmark che rispecchiano il proprio caso di utilizzo, e non cercare di risolvere ogni problema con il medesimo strumento. Quasi tutti i message broker possono reggere messaggi di piccole dimensioni (1Kb) su normali PC di sviluppo possono raggiungere i 50.000 messaggi al secondo, un valore discreto per ogni genere di test. Giusto per dare un’idea del tipo di analisi che si possono fare su un message broker, vediamo brevemente alcuni dei risultati pubblicati di test effettuati con RabbitMQ.
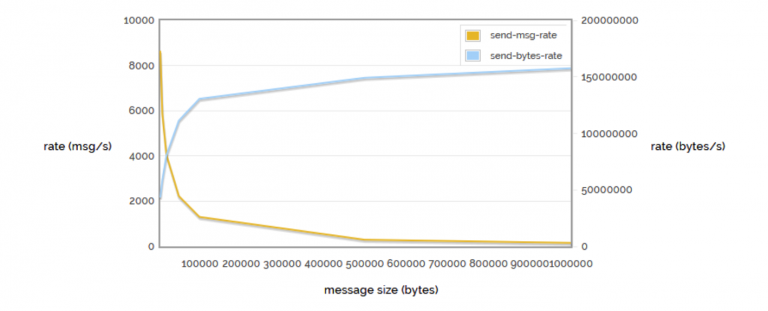
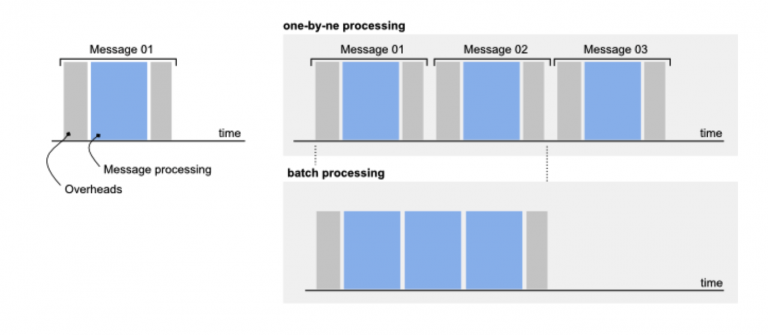
Un test molto importante è il confronto fra messaggi inviati e byte inviati. Mandare molti messaggi di pochi byte comporta un overhead notevole, con conseguente degrado di performance, mentre inviare pochi messaggi di alcuni mega si rivela particolarmente deleterio per il numero di messaggi che si possono recapitare. Qualora si fosse nella prima condizione, una possibile strategia è l’invio di liste di messaggi, in modo da avvicinarmi all’incrocio del trade off. Con il grafico riportato, ad esempio, vediamo che abbiamo la possibilità di inviare 4000 messaggi da circa 256 byte. Se i nostri messaggi fossero da 20 byte, opportunamente serializzati ci permetterebbero un risultato finale di 4000 messaggi da liste di 240 byte (approfittando quindi di un fattore moltiplicativo pari a 12, portando il numero di messaggi reali inviati a 48.000)
Questa tecnica rientra nell’approccio batch processing, e si possono ottenere moltiplicatori importanti se ben sfruttata.
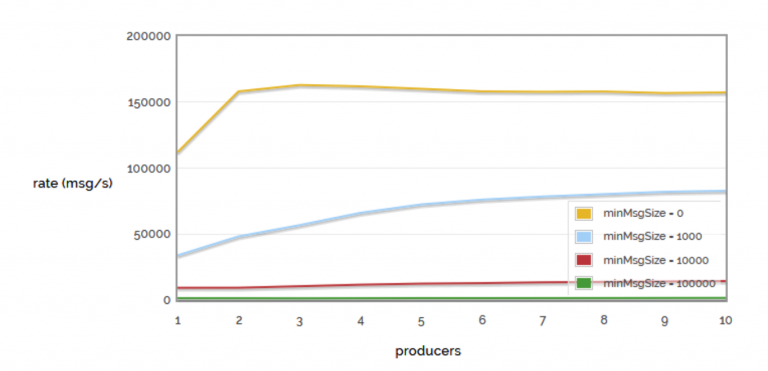
Un altro test riguarda la valutazione del message rate rispetto alla dimensione del messaggio in byte all’aumentare del numero di produttori.
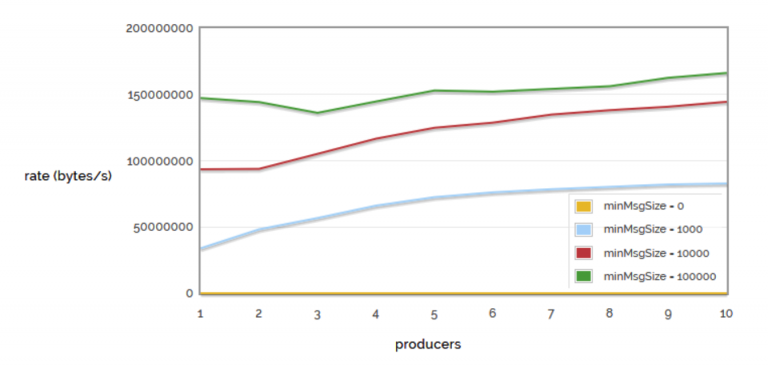
Da confrontarsi con il corrispettivo andamento del traffico dati se si analizzano i byte trasmessi anziché i singoli messaggi.
Tirando le fila
In conclusione, i vantaggi nell’utilizzare i message broker sono da ricercarsi nell’elevata efficienza e scalabilità che possono fornire all’interno di un’architettura distribuita e nella rapidità dello sviluppo del software secondo l’approccio a microservizi, soluzione nella quale la parte di colloquio tra processi può essere ampiamente delegata ai servizi di message broking.
Gli svantaggi sono principalmente due:
Restano quindi svariate attività per cui è comunque richiesto di implementare interfacce e protocolli di comunicazione allo sviluppatore, sebbene anche per questo scenario esistono ormai valide librerie che semplificano molto la vita (ad esempio gRPC).
Come corollario e per completezza è bene fare alcune precisazioni: l’approccio Message Oriented non necessariamente prevede la persistenza come requisito. Esistono casi in cui è preferibile una comunicazione transiente. I sistemi paralleli sono un caso particolare dei sistemi distribuiti, e nel caso di sistemi paralleli ci sono delle peculiarità che possono essere ottimizzate con soluzioni specifiche. Non esiste una linea di demarcazione netta tra ciò che è calcolo distribuito e calcolo parallelo, ma osservando gli estremi delle definizioni, possiamo dire che nei processi distribuiti un singolo problema viene diviso in più attività, e ciascuna attività viene svolta da un componente specifico, che dialoga in un flusso più o meno continuo con gli altri componenti. Nelle applicazioni parallele, ciascun componente svolge il medesimo compito concentrandosi su un sotto insieme dei dati disponibili. Le necessità di comunicazione in questi due scenari sono differenti, e quindi è preferibile adottare un sistema di scambio messaggi che non sfrutti le code e la loro persistenza, come il Message Passing Interface (MPI), dove il messaggio è più un sistema di coordinamento che non un vero e proprio input per gli altri componenti.
Per chi volesse approfondire un buon testo che presenta i diversi scenari dei paradigmi accennati è: S. Tanenbaum, M. Van Steen, “Sistemi distribuiti. Principi e paradigmi”, Pearson Education Italia, 2007. Mentre per approfondire i dettagli di RabbitMQ: https://www.rabbitmq.com/documentation.html, https://www.cloudamqp.com/
Infine, un ottimo esempio di test comparativo tra RabbitMQ e Kafka: https://arxiv.org/pdf/1704.00411.pdf
Leggi anche

Gestione ottimizzata della messaggistica aziendale e delle code MQ con Infrared360®
Gestione delle code MQ e della messaggistica aziendale con Infrared360®: monitoraggio e automazione per prestazioni ottimali.