Have you ever wondered how Netflix can suggest the right kind of movie for you? Or Amazon to show you the item you needed? Or how come, the advertisements that appear to you on websites refer to something you are interested in? These are just a few examples of a type of algorithms that are nowadays used by most websites and applications to provide users with personalized suggestions; these are recommendation systems.
In this article we will find out what they are, what methods they are implemented with, and how their performance is evaluated.
What are recommender systems
Recommender systems are a type of content filtering system. They can be described as algorithms that aim to suggest to the user of a website or application items that may be of interest to him or her. Faced with a range of products, they must be able to select and suggest those that are most suitable for each user, then make personalized suggestions.
These types of algorithms are used in a variety of areas. The most obvious examples may be those already mentioned at the beginning of the article so in e-commerce services (e.g., Amazon), movie, video or music streaming services (e.g., Netflix, YouTube, Spotify), but also in social platforms (e.g., Instagram), delivery services (e.g., Uber Eats) and so on. In general, whenever there is an opportunity to suggest content to a user, a recommendation system can be used to make it user-specific.
How they are implemented
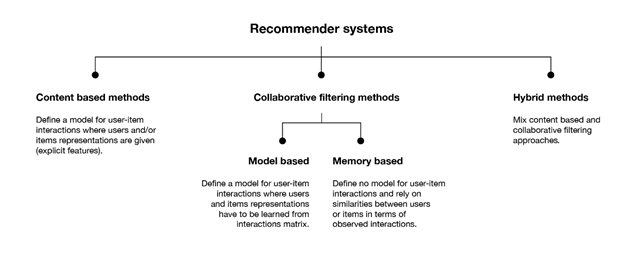
Recommender systems can be divided mainly into two macrocategories: collaborative filtering methods and content-based methods. In addition, these two approaches can be combined to give rise to hybrid solutions that exploit the advantages of both.
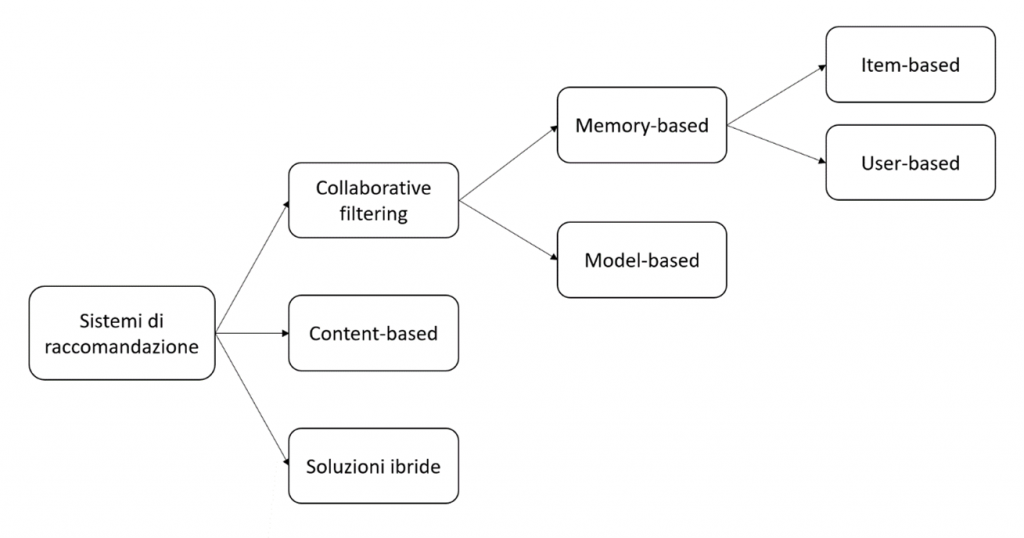
Collaborative filtering methods
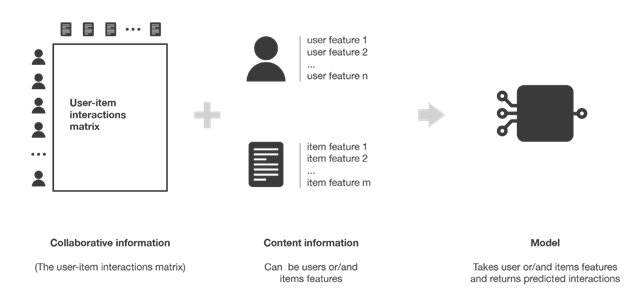
Collaborative recommendation filtering systems use interactions that have occurred between users and articles in the past to build the so-called user-article interaction matrix and extract new suggestions from it. They are based on the assumption that these interactions are sufficient to recognize users and/or articles similar to each other and that predictions can be made by focusing on these similarities.
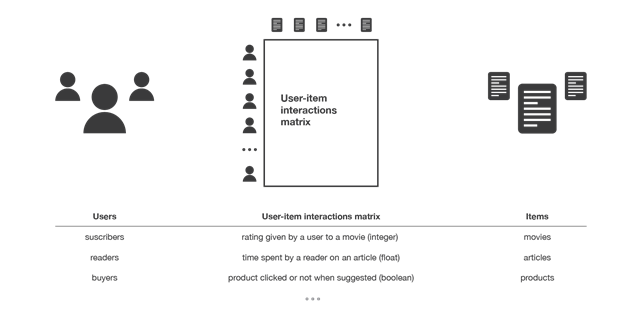
This class of methods is in turn divided into two subcategories, based on the technique used to identify similarities between users and/or items: memory-based and model-based methods. The former directly use the values contained in the user-article interaction matrix to search for the “neighborhood” of the target user or article; the latter assume that a model can be extracted from the matrix values with which to make the new predictions.
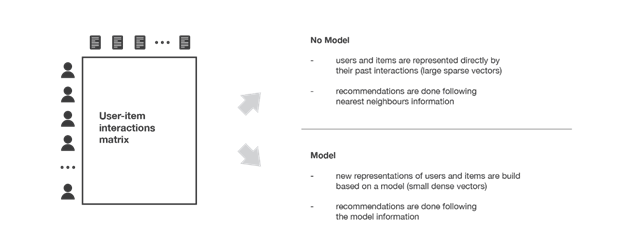
The main advantage of collaborative filtering methods is that they do not require extraction of information about users or articles therefore they can be used in a variety of contexts. In addition, the more users interact with the articles, the more information will be available and the more accurate the new recommendations will be.
Their disadvantage emerges when having new users or new articles because there is no past information about their interactions, this situation is called cold start problem. In this case, several techniques are exploited to determine what the new recommendations should be: randomly selected articles are recommended to new users or new articles to randomly selected users, popular articles are recommended to new users or new articles to the most active users, a set of several articles are recommended to new users or a new article is recommended to a set of several users, or, a collaborative filtering approach is avoided at this stage.
Memory-based methods
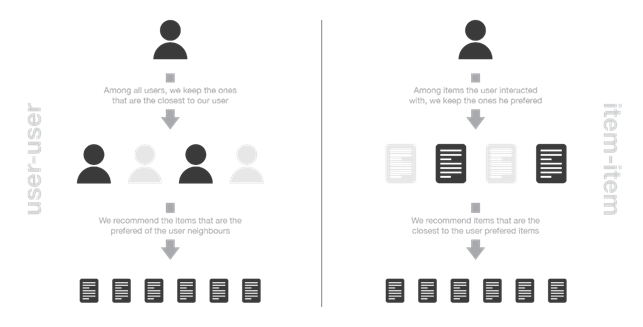
Memory-based methods can in turn be divided into user-based and item-based methods.
User-based methods represent users by considering their interactions with items, and based on this they evaluate the similarity between one user and another. In general, two users are considered similar if they have interacted with many articles in the same way. To make a new recommendation to a user, an attempt is made to identify those with the “interaction profiles” most similar to his or her own, so as to suggest the most popular articles among his or her neighborhood.
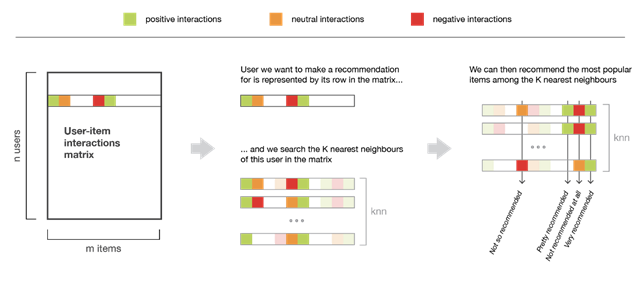
An example of applying the user-based method is used by Youtube to suggest videos on our Homepage.
Item-based methods represent items based on the interactions users had with them. Two items are considered similar if the majority of users who interacted with both did so in the same way. To make a new recommendation to a user, these methods look for items similar to those with which the user has positively interacted.
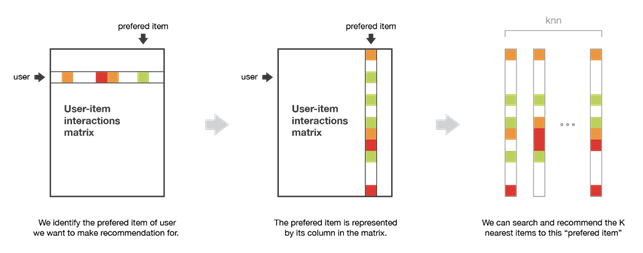
An example of applying the item-based method is used by Amazon when we click on an item and the section “customers who viewed this item also viewed” appears showing us other items similar to the one we selected.
One of the disadvantages of memory-based methods is the fact that neighborhood search can take a long time on large amounts of data, so it must be implemented carefully and as efficiently as possible. In addition, it must be avoided that the system recommends only the most popular items and that users are only suggested items that are very similar to those they have liked in the past; it must be able to ensure some diversity in the suggestions made.
Model-based methods
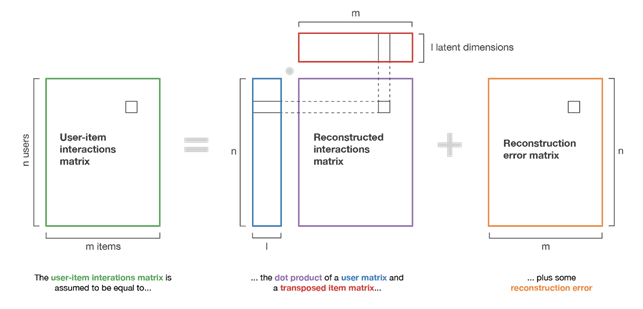
Model-based methods are based on the assumption that interactions between items and users can be explained through a “hidden” model.
An example of a model extraction algorithm is matrix-factorization, this basically consists of decomposing the user-article interaction matrix into the product of two sub-matrices, one containing the representation of users and the other the representation of items. Similar users in terms of preferences and similar items in terms of characteristics will have similar representations in the new matrices.
Content-based methods
Unlike collaborative filtering recommendation systems that rely only on user interaction with articles, content-based recommendation systems search for additional information.
Suppose we have a recommendation system that has to deal with suggesting movies to users, in this case the additional information could be age, gender, and job for users as well as category, main actors, and director for movies.
Content-based methods attempt to build a model that can explain the user-article interaction matrix based on the features available to users and articles.
So, considering the previous example, we look for the model that explains how users with certain features like movies with as many features. Once this model has been obtained, making predictions for a new user is easy, just consider his or her features and new predictions will be made accordingly.
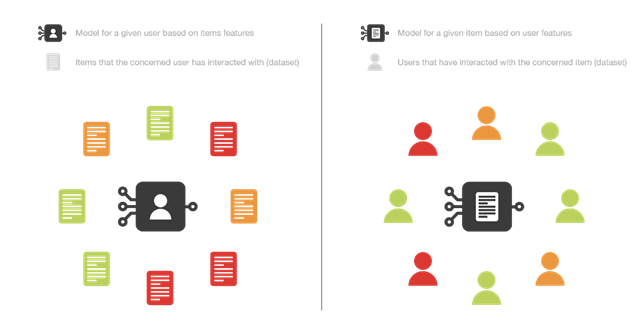
In content-based methods, the recommendation problem is treated as a ranking problem (predicting whether or not a user might like an article) or a regression problem (predicting the rating a user would assign to an article).
In either case the problem can be based on user features (item-centred method), or on article features(user-centred method). In the former case one builds a model per item trying to figure out what is the probability that each user likes that ‘item, in the latter case one builds a model per user to figure out what is the probability that that user likes the items available. Alternatively, one can also evaluate a model that contains both user and article features.
The advantage of content-based methods is that they do not suffer from the cold start problem because new users and new items are defined by their features and recommendations are made based on these.
How they are evaluated
To evaluate the performance of a recommender system, thus to try to understand whether the recommendations it is making are appropriate, three main types of evaluations are used: user studies, online evaluation, and offline evaluation.
User studies evaluation involves proposing recommendations made by different recommendation systems to users and asking them to rate which recommendations they think are best.
Online evaluation, also called A/B testing, involves proposing different recommendations to users in real-time so that they can evaluate which ones get the most “clicks.”
Offline evaluation involves running simulations of user behavior from the past datasets you have available.
Condividi tramite