The advantages of a Message Broker in modern distributed architectures (with references to RabbitMQ)
Modern architectures are developing in a highly decentralized direction (think of how much software nowadays is being designed from a microservices perspective , or how consensus distribution is the cornerstone of a whole new strand of technology such as blockchain and cryptocurrencies). This is actually not a new topic in the world of computing; back in the days of its creation in 1969, the UNIX operating system had to make a choice in the design of the kernel between a monolithic approach (a structure we would call centralized today) and a microkernel approach (definitely close to the concept of decentralized). Since neither approach has only advantages, as is often the case, there have been religious wars on the subject, where there has been no shortage of attempts to compromise with kernel-hybrid architectures (i.e., today’s Windows and macOS). At present, one of the requirements that is being focused on the most is to always provide a result, without relying solely on the replication of entire hardware and software structures to ensure service continuity. Dividing what used to be a single service over N microservices brings an undoubted set of advantages:
- greater ease in scalability: since this is a micro activity, it is reasonable to assume that it can be started and replicated very quickly (an approach that sees its current zenith in dockers and kubernates);
- increased software maintainability: it is again reasonable to think that a microservice does a really small number of tasks, bringing advantages in writing, testing, and bug fixing;
- high decoupling of processes: each, at least in theory, should be able to live a life of its own by waiting for demands to be answered, disinterested in the macroscopic system in which it has been embedded;
- less impact in the event of a service disruption: if a microservice were unavailable this would not impact the rest of the system, which would continue to provide response (albeit perhaps only partial).
These are just to list the main ones. However, there is an obvious downside: as perfect as it would be to be able to design an architecture in which each component never needs to exchange data with the others, this does not prove possible in practice. Each component is constantly involved in an exchange of information with the others. The conversation between different processes (or modules) can be approached in a variety of ways:
To make an analogy, we could think of the two extremes: RPC and MOM. The former is the equivalent of a medieval messenger, instructed by his principal on the time and manner in which a carefully prepared and sealed message is to be delivered, and possibly provided with a more or less numerous escort that can guarantee the security of the missive to be delivered. Certainly, as every aspect is taken care of and calibrated to the importance of the message, we will get maximum efficiency and reliability out of every communication, at the expense of a considerable expenditure of energy and resources. The second is more like a post office, to which we entrust our message with a minimum number of instructions about it, to which we assign a priority and possible instructions for a delivery notification. We do not care about other aspects, knowing that the post office is safe and reliable (if we should not trust the post office we could always rely on other couriers if we wanted to). Message brokers are the software that implements the MOM paradigm and provides all the services (in the form of APIs) needed for message distribution, defining within them the structures needed to define routing routes and delivery policies. One of the oldest software of this type is IBM MQ, created in 1993, while in the present day the most popular systems are RabbitMQ and Kafka. Systems placed within the Clouds obviously have their own managed versions, we have for example Azure Service Bus provided by Microsoft and Simple Queue Service provided by Amazon. Basically all these systems offer the same functionality, although the specific implementations have weaknesses and strengths with respect to the initial contexts in which they were conceived. Just to give an example:
The MOM paradigm
Having posed these broad guidelines, however, we can define what are the firm heads of the MOM paradigm:
With these two simple objects, it is possible to build topologies in which communication takes place either point-to-point (there is a queue between sender and receiver) or point-to-multipoint (in which a sender forwards a message to a node, and that node distributes it to all connected subscribers). The strength of these systems is the ability to define subscription policies at the nodes. The simplest, basic nodes replicate the same message to all subscribers, but by setting rules, and possibly placing nodes in cascades, it is possible to deliver messages with certain characteristics to subscribers who have requested them. Let’s look at some examples to clarify all these concepts.
Creating a queue in RabbitMQ (in C#)
In the classic Producer/Consumer paradigm we imagine that we want to connect the two entities through RabbitMQ. The tool adopted is Coda.

The producer simply needs to place the message in the queue, and trust in the goodness of RabbitMQ. The queue will hold the messages until the consumer has a chance to take them over, implicitly providing a persistent data management mechanism. Reading messages can be done in the following ways:
Tail properties
The queue can be defined with a number of properties:
The code needed to implement this point-to-point dialogue involves creating a send method (which we will call Send) and a receive method (similarly Receive):
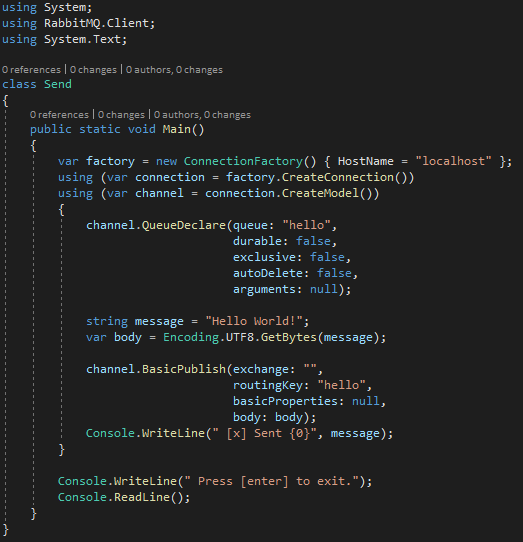
Points of interest in this code are the factory, which is the class provided by the RabbitMQ .NET library for creating and managing the service. You only need to indicate the address of the server on which RabbitMQ is running, and you can add the classic general data such as user and password (N.B. if RabbitMQ is installed in localhost, nothing is needed to run other than the HostName, but if you connect remotely, it is essential to create a user, since the default user is enabled to the API only if these requests come from the local system). Once you have the factory, you can use it to create a connection, that is, open a TCP connection to talk to RabbitMQ. Through the connection we can create a model; it represents the connection to RabbitMQ’s internal structures. We can think of the two entities in this way:
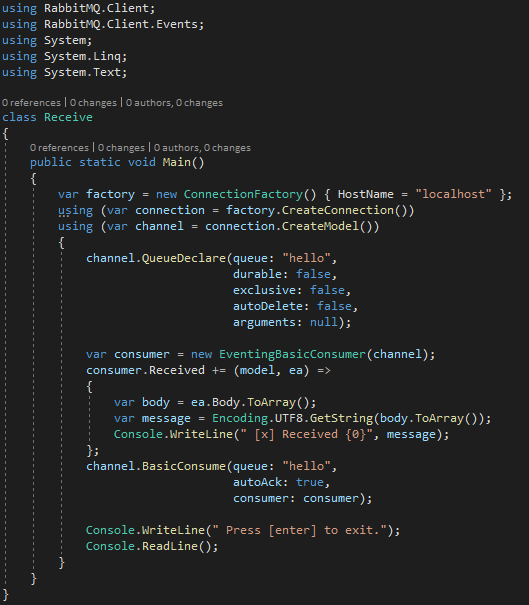
Flexibility is total, but best practices recommend creating a single connection to RabbitMQ to keep active for as long as possible, while creating models as needed when you want to ship. Nothing prohibits maintaining a model indefinitely, especially if you had continuous traffic and the overhead of creating and destroying the model was excessive. Once you have the model, you can create or connect to a queue. A queue must have a unique name and a set of characteristics that can be defined at creation, and must match for anyone intending to connect to it either sending or receiving. Sending the message is done simply through the BasicPublish method, to which it is normally sufficient to supply the message in the form of a byte array. The other elements of BasicPublish we will see shortly in the next example. Receive, on the other hand, will be written like this:
There are two points of interest here: the registration of the EventingBasicConsumer, i.e., the handler to which the receiving event will be bound and the method to be invoked whenever the queue notifies of the presence of a new message; and the BasicConsume method, in which a peculiarity of the receiver can be defined: when the message is notified, it is possible to establish two different times at which to confirm its removal from the queue:

It is possible, to put multiple consumers in competition on the same queue, in which case RabbitMQ will notify consumers with respect to the parameters they have set. Typically, in the presence of implicit Acks, the resolution is done in round robin on the consumers. If, on the other hand, the Acks are explicit, we can go and define the BasicQos (Quality of Service).channel.BasicQos(prefetchSize: 0, prefetchCount: 1, global: false);By adding this statement after the QueueDeclare, it is possible to define globally (if we want to provide these parameters to all models) or only to the specific model that is invoking the BasicQos method, two parameters: the prefetchSize and the prefetchCount.
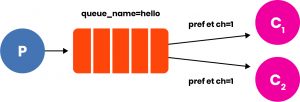
To send a Explicit Ack, normally at the end of the method used as the handler of the consumer.Received you ponechannel.BasicAck(deliveryTag: ea.DeliveryTag, multiple: false); In which the DeliveryTag indicates the message for which the Ack is being notified, while the following flag is used to handle removal policies, i.e., whether a message should be removed immediately upon first notification or whether it should be delivered to all consumers, so until a number of Acks equal to the number of connected consumers (or an Ack that does not require further waiting) is received, the message will remain in the queue (subject to any TTL-related policies). It will be RabbitMQ’s job to notify a new message consistent with the policies set to each consumer. If, for example, C1 and C2 both have to process the same messages, but C1 is much faster than C2, we will have that for each new message, C1 will receive a notification consistent with its prefetch setting, and messages will be forwarded to it not only from the head of the queue, where there are messages already delivered to it that are waiting to be notified to C2 as well or that are simply still waiting for an Ack. It is important to note that all this management would normally be very complex, but it is included among the common basic configurations of RabbitMQ, which provides this scenario without any effort or performance degradation.
Creating a distribution node in RabbitMQ (in C#)
Much more interesting is the ability to create distribution nodes (called Exchanges) and define their routing policies. It is fair to disclose that the images seen just now are actually the conceptualization of point-to-point communication, but in reality the implementations all involve the introduction of a distribution node between the producer and the delivery queue. Note then, in reference to the previous Send, that those two properties left hanging for a moment (exchange: “”, routingKey: “hello”) go to indicate that we have not named the exchange (although it exists by construction, but which we disregard as part of the inner workings of RabbitMQ) and optionally a routingKey. Such a routingKey is unnecessary in the example but allows us to say that if we want to we can specify to the consumer that they must know the routingKey of the messages in order to listen to them, and although it does not represent a security mechanism, it is useful to always define one to avoid errors and not have the wrong messages delivered to a consumer we are testing.
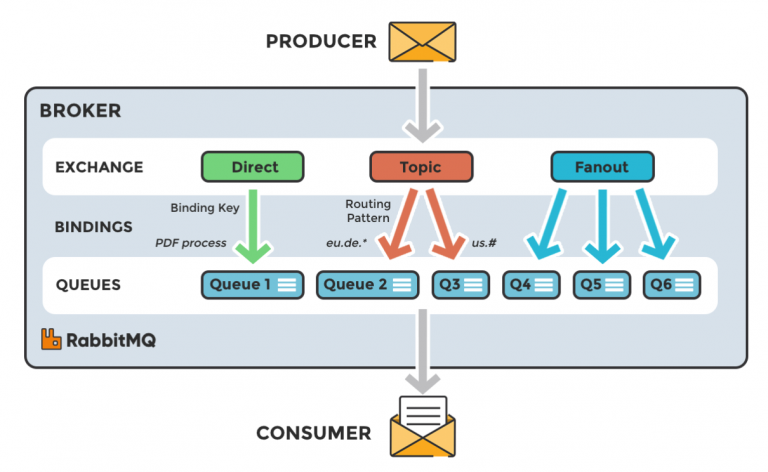
That node, called Exchange, becomes very important in case the distribution is not on one queue only, but on a number of Subscribers; in fact, consumers who connect a queue to a distribution node are called subscribers. Nodes in RabbitMQ are of 4 types, and well or poorly we find similar concepts in other software, though with different names:
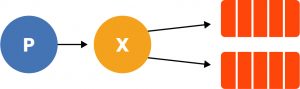
Taking an example similar to the previous one, we will have a producer made like this:
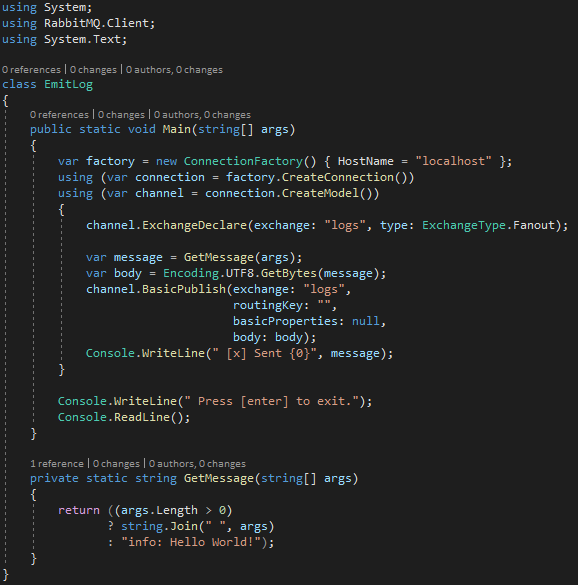
Basically, the only difference is the use of ExchangeDeclare in place of QueueDeclare. One of the subscribers, on the other hand, will have this form:
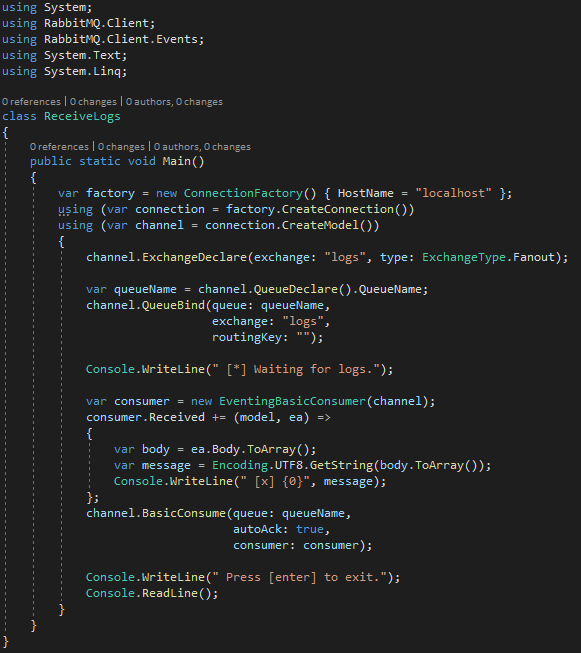
The points of interest here are as follows:
The subscriber connects the newly created queue to the node (with the QueueBind operation). In this way we go on to design the network structure that we will later use for message distribution. In particular in RabbitMQ note that the QueueBind has to be repeated for each RoutingKey you want to receive on that subscription, while other brokers allow multi-key subscriptions (passing arrays of strings, for example).
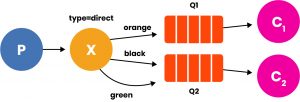
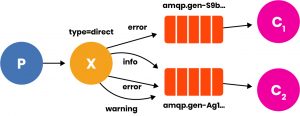
This could, for example, be the topology of a level-differentiated log system. And finally an example of Topic, in which sorting is done by special characters:
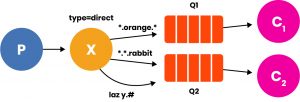
In RabbitMQ we have that:
By adopting these special characters with these meanings, by construction the Routing Keys take the form of sentences separated by period.
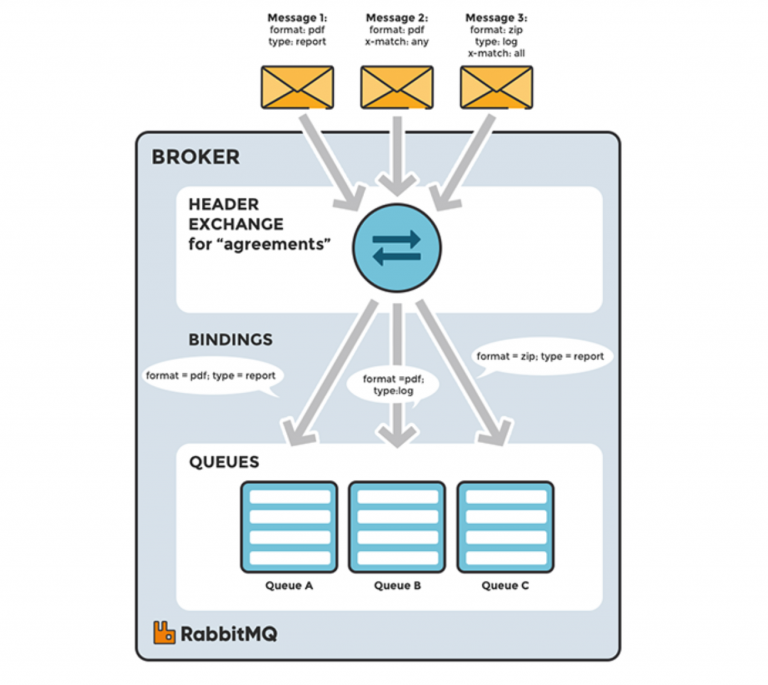
Finally, wanting to schematize a header-type exchange, it is worth pointing out that the extreme power in defining routing rules is paid for by a degradation in the final throughput of the system.
Speaking of performance
Each message broker has strengths that it tries to leverage to gain prominence in a specific industry. Kafka focuses on the number of messages transmitted, ActiveMQ aims to be the best compromise between message size, message numbers, and overall latency without excelling at anything, RabbitMQ focuses on the extreme flexibility of its routing capability without it impacting too much on the end result. Before adopting one, it is always a good idea to document yourself and look for benchmarks that reflect your use case, and not try to solve every problem with the same tool. Almost all message brokers can handle small messages (1Kb) on normal development PCs can reach 50,000 messages per second, a decent value for any kind of testing. Just to give an idea of the kind of analysis that can be done on a message broker, let’s briefly look at some of the published results of tests done with RabbitMQ.
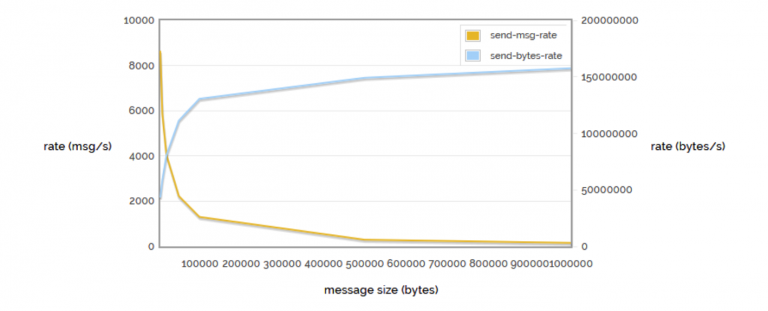
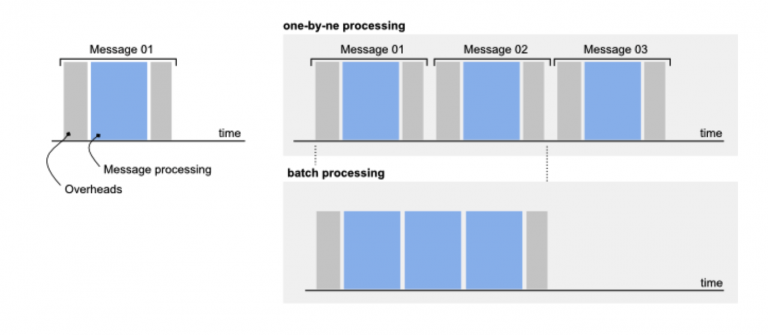
A very important test is the comparison between messages sent and bytes sent. Sending many messages of a few bytes incurs considerable overhead, resulting in performance degradation, while sending a few messages of a few megs proves particularly deleterious because of the number of messages that can be delivered. Should one be in the former condition, one possible strategy is to send lists of messages, so as to approach the trade-off intersection. With the graph shown, for example, we see that we have the possibility of sending 4000 messages of about 256 bytes. If our messages were 20 bytes, properly serialized they would allow us an end result of 4000 messages from 240-byte lists (thus taking advantage of a multiplicative factor of 12, bringing the number of actual messages sent to 48,000)
This technique is part of thebatch processing approach, and significant multipliers can be achieved if well exploited.
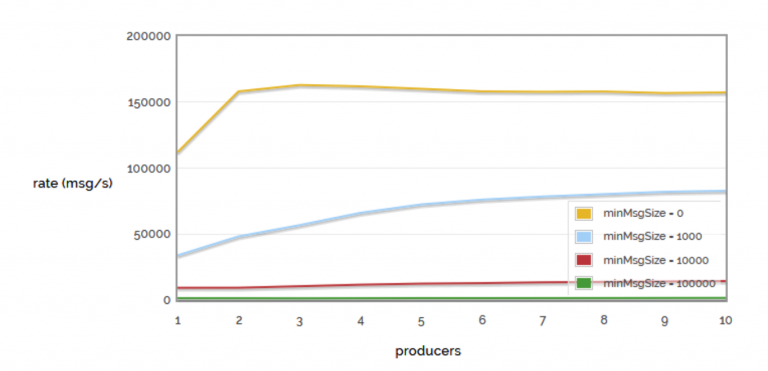
Another test involves evaluating message rate versus message size in bytes as the number of producers increases.
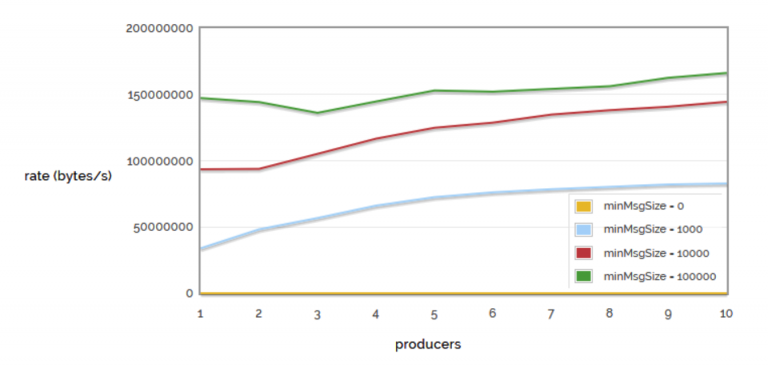
To be compared with the corresponding trend in data traffic when analyzing bytes transmitted rather than individual messages.
Pulling the strings
In conclusion, the advantages in using message brokers are to be found in thehigh efficiency and scalability they can provide within a distributed architecture and in the rapidity of software development according to the microservices approach, a solution in which the conversation part between processes can be largely delegated to message broking services.
The disadvantages are mainly two:
This leaves a variety of tasks for which the developer is still required to implement interfaces and communication protocols, although even for this scenario there are now good libraries that make life much easier (e.g., gRPC).
As a corollary and for the sake of completeness, it is worth making some clarifications: the Message Oriented approach does not necessarily have persistence as a requirement. There are cases in which transient communication is preferable. Parallel systems are a special case of distributed systems, and in the case of parallel systems there are peculiarities that can be optimized with specific solutions. There is no clear line of demarcation between what is distributed computing and parallel computing, but looking at the extremes of the definitions, we can say that in distributed processes a single problem is divided into several tasks, and each task is performed by a specific component, which dialogues in a more or less continuous flow with other components. In parallel applications, each component performs the same task by focusing on a subset of the available data. The communication needs in these two scenarios are different, and so it is preferable to adopt a message exchange system that does not take advantage of queues and their persistence, such as Message Passing Interface (MPI), where the message is more of a coordination system than a true input to other components.
For those who want to learn more, a good text that presents the different scenarios of the paradigms mentioned is: S. Tanenbaum, M. Van Steen, “Distributed Systems. Principles and paradigms,” Pearson Education Italia, 2007. While to delve into the details of RabbitMQ: https://www.rabbitmq.com/documentation.html, https://www.cloudamqp.com/
Finally, an excellent example of a comparative test between RabbitMQ and Kafka: https://arxiv.org/pdf/1704.00411.pdf
Condividi tramite