1. Introduci la tua esperienza professionale dall’università fino all’ingresso in ORBYTA
Mi sono laureata in giurisprudenza ad aprile 2020 in piena pandemia, momento in cui credevo che le mie speranze di trovare un lavoro fossero sotto lo zero. A dispetto di ogni aspettativa, sono invece subito entrata in Orbyta, dove ho intrapreso il mio percorso di crescita professionale: fin da subito mi sono messa in gioco, cercando di acquisire quanto più possibile da chiunque mi stesse intorno.
Spinta dalla curiosità di concludere il percorso di studi intrapreso, a marzo 2021 ho maturato l’idea di intraprendere il percorso della pratica forense per diventare a tutti gli effetti avvocato. Fin da subito Orbyta ha riposto grande fiducia in questa mia scelta, incentivandomi a non mollare.
2. Di cosa ti occupi e che valore porti all’azienda?
In Orbyta faccio parte del team Legal e mi occupo principalmente di fornire consulenza legale giudiziale e stragiudiziale. Intraprendere la pratica forense all’interno di una società permette di spaziare in diversi ambiti.
Nel corso della mia esperienza in Orbyta ho, infatti, sviluppato diverse competenze non solo nel campo giudiziale ma anche e soprattutto in ambito di tutela dei dati personali e di proprietà industriale. Orbyta mi ha aiutato nel mio percorso professionale permettendomi di seguire corsi e prender parte ad un sistema di formazione fondamentale per la mia crescita professionale ma anche personale. Cerco sempre di trasmettere ciò che apprendo in modo da esser utile al prossimo e spero di rappresentare un punto di riferimento all’interno del team e per chiunque mi stia intorno.
3. Perchè ti piace lavorare in ORBYTA?
L’ambiente giovanile e dinamico è di grande stimolo per fare meglio, mettersi in gioco e ricercare nuove sfide, soprattutto al di fuori della propria comfort zone. Orbyta è fatta di persone la cui energia positiva rappresenta il propulsore per guardare sempre avanti!
In Orbyta inoltre non mancano mai preziosi momenti di confronto con i colleghi: si ha la possibilità di esprimere le proprie idee e soprattutto di essere ascoltati, dando un valore aggiunto ad una società in forte espansione.
LIS2Speech Project and Lexis Integration
Deaf and hard-of-hearing people can communicate with each other using Sign Language, but they may have difficulties in connecting with the rest of society. Sign Language Recognition is a field of study that started to be analysed back in 1983, but only in the last decade this task gained more attention. Most of the published works are related to American, Chinese and German sign languages. On the other hand, the number of studies on the Italian Sign Language (LIS) is still scarce.
In order to solve the expressed problem, Neural Networks, Deep Learning and Computer Vision have been exploited to create an application, called LIS2Speech (LIS2S), capable of returning the Italian translation of a LIS sign, performed within a recorded video. The method relies on hands, body and face skeletal features extracted from RGB videos without the need for any additional equipment, such as colour gloves. Since the goal is to embrace as many people as possible, LIS2S has been developed as a Progressive Web App, which is able to be run on any device, be it a computer or a smartphone, equipped with a camera.
The results obtained with the described approach are in line with those obtained by automatic tools that have been developed for other sign languages, allowing the model to correctly understand and discriminate between signs belonging to a vocabulary of 50 words, which is in accord with the size of other corpora for isolated sign language recognition. In addition, a new dataset for Continuous Sign Language Recognition (CSLR) has been created and is being constantly expanded, to create a publicly available benchmark for this kind of task.
Social problem
Spoken languages and sign languages are different in a number of important ways: the former make use of the “vocal – auditory” channel, since the sound is produced with the mouth and perceived with the ear; the latter instead use the “corporal – visual” channel, signs are produced with the body (hands, arms, facial expressions) and perceived with the eyes.
There are several flavours of sign languages, due to the fact that they are not international, and even inside a national sign language different dialects are present. They are natural languages, since they evolved spontaneously wherever communities of deaf people had the possibility of communicating mutually, and are not derived from spoken languages, because they have their own vocabulary and grammatical structures.
The fundamental building block of a sign language is a gloss, which combines manual and non-manual features and represents the closest meaning of a sign. Based on the context, a specific feature can be the most important factor in the interpretation of a gloss: it may change the meaning of a verb, provide spatial or temporal information and discriminate between objects or people.
As known, there is an intrinsic difficulty in the communication between the deaf community and the rest of the society (according to ANSA, in 2018 there were more than 72 million people all over the world using sign languages), so the design of robust systems for automatic sign language recognition would largely reduce this gap.
The definition of Sign Language Recognition (SLR) can be expressed as the task of deducing glosses performed by a signer from video recordings. It can be considered some way related to human action or gesture recognition, but automatic SLR exhibits the following key additional challenges:
The interpretation of sign language is highly affected by the exact position in the surrounding space and context. For example, there are no personal pronouns (e.g., “he”, “she” etc.), because the signer points directly to any involved actor.
Many glosses are only discernible by their component non-manual features and they are usually difficult to be detected.
Based on the execution speed of a given gloss, it may have a different meaning. For instance, signers would not use two glosses to express “run quickly”, but they would simply accelerate the execution of the involved signs.
Machine Learning (ML) and Deep Learning (DL) mechanisms are the base of the so-called Computer Vision (CV); it is an interdisciplinary scientific field that deals with how computers can gain high-level understanding from digital images or videos. SLR is a task extremely related to CV; it takes advantage from the significant improvement in performance gained by many video-related tasks, thanks to the rise of deep networks.
LIS2Speech’s goal is to produce a tool useful for improving the integration of deaf people with the rest of the society; this tool should be easily accessible by anyone, and this is why the choice of developing an application able to be run on laptop or even smartphones has been taken.
State of the art
The past decade has seen the rapid expansion of DL techniques in many applications involving spatio-temporal inputs. The CV is an incredibly promising research area, with ample room for improvement; in fact video-related tasks such as human action recognition, gesture recognition, motion capturing etc. have seen considerable progress in their development and performance. SLR is extremely related to CV, since it requires the analysis and processing of video chunks or sequences to extract meaningful information; this is the reason most approaches tackling SLR have adjusted to this direction.
SLR can play an important role in addressing the issue of deaf people integration with the rest of the society. The attention paid by the international community to this particular problem has been growing during the last years; the number of published studies, but also the quantity of available data sets is increasing. There are different automatic SLR tasks, depending on the detail level of the modelling and the subsequent recognition step; these can be approximately divided in:
Isolated SLR: in this category, most of the methods aim to address video segment classification tasks, given the fundamental assumption that a single gloss is present.
Sign detection in continuous streams: the objective of these approaches is to recognize a set of predefined glosses in a continuous video flow.
Continuous SLR (CSLR): the goal of these methods is to identify the sequence of glosses present in a continuous or non-segmented video sequence. The characteristics of this particular category of mechanisms are most suitable for the requirements of real-life SLR applications.
This distinction is necessary to understand the different kinds of problems present for each task; historically, before the advent of the deep learning methods, the focus was on identifying isolated glosses and gesture spotting, so this is why studies on isolated SLR are more common. In the following image the trend of isolated and continuous recognition studies can be observed in blocks of five years up until 2020; the growth looks exponential for isolated studies, while it is close to linear for continuous studies. This can reflect the difficulty of the continuous recognition scenario and the scarcity of available training datasets. In fact, on average it can be observed that there are at least twice as many studies published using isolated sign language data.
In terms of vocabulary size, the majority of isolated SLR works model a very limited amount of signs (i.e., below 50 signs), while this is not the case when comparing CSLR, where the overall studies are more or less evenly spread across all sign vocabularies. This trend can be observed in the next figure.
Technologies and architectures
LIS2S application is mainly made of two parts: on the client-side there is a Progressive Web Application (PWA), which will be used by the admins and users to access the functionality provided by the software; and the Back-end, which will be managed by a server process constantly listening for requests coming from the application. Whenever a new request is received from the server, it will run a new instance of a Docker container: this will be in charge of processing the data coming with the request and returning back the translation to the client. At the prototypal stage, the server was hosted on a proprietary machine, while, at the final stage, Lexis cluster will be used to provide an highly scalable and performant service.
Moving on towards the back-end section of the LIS2S application, the core of the translation mechanism is performed by the processing of the received videos. This particular task has been realized exploiting the potentiality of the Python programming language, which offers a complete set of tools and libraries extremely useful for Computer Vision and data manipulation. Going more into the details, OpenCV and MediaPipe packages have been mainly used to process videos of our dataset and extract skeletal information about hands, face and upper body of the subject. Here on the right there are some examples of the data extracted from single frames.
The core of the LIS2S application stands in the ability of recognizing the sign performed by the user in his video. To accomplish this not trivial goal, Deep Learning (DL) mechanisms and methodologies need to be used; As the years go on, DL improvements allow us to build technologies that previously were not even imaginable. To make use of these technologies, several frameworks have been developed: among them, the most known are Keras, PyTorch and TensorFlow. TensorFlow is the oldest one, while over the last couple of years, the two major DL libraries that have gained massive popularity, mainly due to how much easier to use they are over TensorFlow, are Keras and Pytorch. The PyTorch framework has been chosen since it provides a perfect balance between ease of use and control over the model training and testing.
Pipeline for Sign Language Recognition
Moving on towards the actual Sign Language recognition, the development team, after an accurate analysis, highlighted the need for four different models. Actually, the developed prototype focuses only on the first two models, which deal with the extraction of skeletal data and the isolated sign recognition; the last two are reported to give indications for future improvements, in order to expand the use cases to which this application could be applied. In the following picture, a diagram of the proposed pipeline is shown.
In the first model skeletal data are extracted from the subject instead of using videos directly: this was decided in order to reduce the dimensionality of the data to manipulate, and to demonstrate that using only lighter data like skeletal data it is possible to obtain state-of-the-art results.
In the proposed architecture, after the features extraction it is possible to find the actual neural network, which is in charge of understanding the temporal information held inside features it is fed with, and return the predicted sign. To do so, first let introduce Recurrent Neural Networks: these are particular networks which are designed to take a series of input with no predetermined limit on size; in this way, the input is considered as a series of information, which can hold additional meaning to what the network is training on. A single input item from the series is related to others and likely will have an influence on its neighbours; RNNs are able to capture this relationship across inputs meaningfully. In fact, they are able to “remember” the past and make decisions based on what they have learnt from the past.
The biggest limitation of this system is that the input must be segmented, since this project is focused on isolated sign language recognition, and in addition the translation is not in real-time. During the development of the project, another model has been considered to effectively switch from isolated to continuous sign language recognition. This model is actually under development and will be, together with the real-time implementation of this application, the next step to reach. Specifically, what the third model should perform is the sign segmentation of sign language sentences.
Finally, in order to make the translation more readable by non-deaf users, the model that has been thought as the final one should perform a type of rephrasing, manipulating the raw translation and converting it into a correct Italian sentence.
Collaboration with Lexis and IT4Innovations
With High Performance Computing (HPC) we refer to the technologies used by cluster computers to create processing systems capable of providing very high performance in the order of PetaFLOPS, typically used for parallel computing.
LIS2Speech project will benefit from a HPC system that requires significant investments and whose management requires the use of high-level specialized personnel. The intrinsic complexity and rapid technological evolution of these tools also requires that such personnel interact deeply with the end users (the experts of the various scientific sectors in which these systems are used), to allow them to use the tools efficiently.
The LEXIS [3] (Large-scale EXecution for Industry & Society) project is building an advanced engineering platform at the confluence of HPC, Cloud and Big Data, which leverages large-scale geographically-distributed resources from the existing HPC infrastructure, employs Big Data analytics solutions and augments them with Cloud services. Further information about the HPC Lexis project can be found at https://lexis-project.eu/web/.
LIS2S has allowed a collaboration with the Lexis Project – High Performance Computing (HPC) in Europe, that has provided Orbyta Team with access to the Barbora cluster.
Barbora is a supercomputer supplied by Atos IT Solutions and Services[2]. It has an extension of the existing Anselm supercomputer, which was commissioned in 2013. It was officially taken over by IT4Innovations National Supercomputing Center and commissioned in late September 2019. “Our goal is to regularly renew our computing resources so that our users have access to state-of-the-art computing systems, and to be able to meet their growing requirements as much as possible,” says Vít Vondrák, Director of IT4Innovations National Supercomputing Center.
IT4Innovations are the leading research, development, and innovation center active in the field of high-performance computing (HPC), data analysis (HPDA), and artificial intelligence (AI). They operate the most powerful supercomputing systems in the Czech Republic, which are provided to Czech and foreign research teams from both academia and industry [4].
The Barbora cluster[1] on which LIS2S has been migrated thanks to the LEXIS team consists of 201 compute nodes, totaling 7232 compute cores with 44544 GB RAM, giving over 848 TFLOP/s theoretical peak performance.
Nodes are interconnected through a fully non-blocking fat-tree InfiniBand network, and are equipped with Intel Cascade Lake processors. A few nodes are also equipped with NVIDIA Tesla V100-SXM2. The cluster runs with an operating system compatible with the Red Hat Linux family.
Lexis team installed the needed deep learning Python packages that are accessible via the modules environment. The PBS Professional Open Source Project workload manager provides computing resources allocations and job execution.
Offline ML Training Calculation Platform in order to train all the models (new trainings are required for improvements and updates and for dictionary enlargement)
Offiline video processing platform for data augmentation
Runtime Real-time user usage (Post and get requests of multiple users for real time translation and get feedback data from users).
Runtime/Offline Admin usage (Service handling (e.g. Temporary interruption), Post request for video adding to dictionary, Get request for performance and usage supervision)
Data Storage (Permanent and temporary structured alphanumeric data, permanent and temporary raw videos and processed videos)
Other collaborations
From 2020 we collaborate with the Department of Automation and Information Technology of the Politecnico di Torino[7] and with the Ente Nazionale Sordi in order to get a larger Dataset and to test our application[6].
Innovation
At the current state, LIS2S already has multiple points of innovation compared to the current state of art:
the application does not require special equipment (Kinect, gloves …) but only a video camera and can be run on any device, smartphone, tablet or PC;
the use of skeletal data instead of raw video is innovative and allowed us to get a network that is easier to train
our study focuses not only on hand data, but also on body posture and eye, lip and brow movements, unlike most studies in the same area
the number of words in the vocabulary is greater than in other LIS studies, but the performance is almost identical. The new LIS dataset has been created in which not only the single signs are present but entire sentences with the indication of the signs that compose them
the study and the dataset have been constructed in such a way that the network is signer-independent, i.e. it is independent of who is making the sign and is able to recognize the gesture in most visual conditions
the application can also be used to acquire new signs from all admin users, allowing the dictionary to grow over time independently. Also included is a process of re-training the periodic model in order to allow the application to learn these new signs.
the application will present a LIS translation feedback collection system
the application will present the possibility to modify the translation based on whether a right-handed or a left-handed person is using it
Regardless of what has been done for the other states, there is currently no application available that focuses on the translation from LIS to Italian, and we also plan to return the translation both written and spoken. Once in Italian we can therefore also include the translation from LIS into English or other languages. Following the same logic, it would be possible, in a possible subsequent phase, to translate from LIS to other sign languages with appropriate animations.
We aim to translate not a single sign, but entire sentences in correct Italian. In fact, it must be remembered that LIS has a different syntactic structure than Italian.
Orbyta Team is working hard in order to improve LIS2S over time and to expand its functionalities and we will share our progress with the research community and our followers.
[5] Slides: Workflow Orchestration on Tightly Federated Computing Resources: the LEXIS approach, EGI 2020 Conference, Workflow management solutions, M. Levrier and A. Scionti, 02/11/2020
Giuseppe Mercurio and Carla Melia, data scientists at Orbyta Tech Srl, 10.06.2021
Isolation levels on SSMS
“La palla è mia!” “Non è vero, l’ho vista prima io!” “Sì, ma io corro più veloce e l’ho presa per primo!”
Se potessimo parlare la lingua del database, probabilmente sentiremmo in continuazione discussioni come questa. Nel mondo ideale gli utenti accedono ai nostri dati in buon ordine, uno alla volta, e poi chiudono la porta quando escono, ma nel mondo reale può capitare che gli stessi dati vengano interrogati o addirittura modificati da persone differenti nel medesimo momento.
Cosa succede allora in questi casi? Chi ha la precedenza? Quello che ha acceduto per primo al dato? O quello che l’ha modificato per primo? E cosa viene visualizzato da una query che interroga un dato modificato da un altro? Si vede sempre lo stato più aggiornato?
L’intento di questo articolo è di fornire qualche risposta a
simili domande.
Le transazioni
Per prima cosa dobbiamo prendere confidenza con un’entità
fondamentale per il discorso che stiamo per affrontare, vale a dire la transazione.
Con transazione si intende una serie di operazioni che vengono raggruppate tra
loro: in questo modo, se anche solo una di esse va in errore, vengono annullate
tutte quante così da lasciare i dati in uno stato consistente, cioè com’erano
prima che cominciasse la prima delle operazioni della transazione.
Aiutiamoci subito con un esempio pratico: Emma deve
effettuare un bonifico a Marta. L’operazione di trasferimento di denaro da un
conto all’altro si articola in due semplici passaggi, cioè
prelevare la somma dal conto di Emma
versarla sul conto di Marta
Non serve un gigantesco sforzo di immaginazione per capire che queste due operazioni non possono essere disgiunte una dall’altra; o vanno a buon fine entrambe (e allora viene eseguita l’operazione di commit) o devono fallire entrambe (e allora viene eseguito un rollback, che riporta tutto a com’era prima). Supponiamo infatti che per un problema tecnico non si riesca a versare il denaro sul conto di Marta: se le due operazioni non fossero legate (quindi raggruppate in una transazione), potremmo avere la sgradevolissima situazione in cui, al verificarsi di un errore tra l’operazione a. e l’operazione b., i soldi non sarebbero né sul conto di Emma né sul conto di Marta perché prelevati da un conto ma non ancora versati sull’altro.
Le proprietà ACID
Perché una transazione si possa definire tale deve
rispettare le proprietà ACID, ovvero
Atomicità
Consistenza
Isolamento
Durabilità
L’atomicità è la proprietà che abbiamo appena visto, ovvero
l’impossibilità di un’esecuzione parziale delle operazioni raggruppate nella
transazione. È nota anche come la regola del “o tutto o niente”.
Consistenza significa che una transazione deve lasciare i
dati in uno stato coerente, quindi rispettando, per esempio, i vincoli di
integrità.
L’isolamento consiste nel separare una transazione da quello
che sta succedendo con le altre transazioni eseguite parallelamente, in modo
che una transazione fallita non impatti sulle altre transazioni in esecuzione
(e questo sarà il punto principale sviluppato in questo articolo).
Durabilità (o persistenza) significa non perdere i dati una volta che sono stati scritti, o meglio, non perderli dal momento in cui la base dati si impegna a scriverli.
Scegliere un isolation level
Un livello di isolamento inferiore (quindi più permissivo) aumenta
la capacità di accedere ai dati contemporaneamente da parte di più utenti, ma
aumenta il numero di effetti di concorrenza, come la dirty read che
vedremo in dettaglio più avanti. Al contrario, un livello di isolamento più
elevato riduce i tipi di effetti di concorrenza che gli utenti potrebbero
riscontrare, ma richiede più risorse di sistema e aumenta le possibilità che
una transazione ne blocchi un’altra. Il livello di isolamento più alto infatti
garantisce che una transazione recuperi esattamente gli stessi dati ogni volta
che viene ripetuta un’operazione di lettura, ma lo fa eseguendo dei blocchi (lock)
che potrebbero avere un impatto su altri utenti nei sistemi multiutente.
Effetti di concorrenza
In questa sezione vedremo i tre principali tipi di scenari
che possono presentarsi in un livello di isolamento non elevato quando due
transazioni sono in concorrenza tra loro.
Dirty read
Questa eventualità può verificarsi se la transazione 1 ha la
possibilità di visualizzare un dato modificato dalla transazione 2 quando quest’ultima
non è stata ancora confermata (ovvero non è stato eseguito un commit). Se
qualcosa nella transazione 2 va storto, la transazione 1 avrà avuto accesso a
un dato che in teoria non è mai esistito. Avendo la possibilità di guardare
dati non ancora validati dal marchio di una commit, in una dirty read la
lettura non viene fatta dal disco o dalla cache, ma direttamente dal
transaction log.
Es. Supponiamo che il redattore di un giornale possa leggere
l’articolo di un suo giornalista mentre questi lo sta scrivendo. Il giornalista
aggiunge una frase, il redattore stampa l’articolo per guardarselo a casa, il
giornalista ci ripensa e toglie la frase di prima. Il redattore avrà quindi
stampato l’articolo con una frase che non verrà mai pubblicata.
Nonrepeatable read
In questo caso la transazione 1 legge un dato, la
transazione 2 lo modifica e viene chiusa, la transazione 1 (che è sempre
rimasta aperta), riesegue la stessa query ottenendo un risultato differente
rispetto a quello ottenuto in prima istanza.
Es. Riprendendo l’esempio di prima, il redattore (sempre con
la capacità di vedere in tempo reale le modifiche ai pezzi che i giornalisti
stanno scrivendo), deve stampare due copie di un articolo da distribuire ai
suoi due assistenti. Il redattore stampa la prima copia, il giornalista
aggiunge una frase, il redattore stampa la seconda copia che invece contiene la
frase appena aggiunta. I due assistenti si troveranno così per le mani due
versioni diverse dello stesso articolo.
Phantom read
Lo scenario qui è quasi un caso particolare della
nonrepeatable read, ovvero: la transazione 1 esegue una query che ritorna un
set di dati, la transazione 2 inserisce dei nuovi record, la transazione 1 (che
anche in questo caso non è mai stata chiusa) riesegue la query di prima trovando
dei dati in più rispetto all’interrogazione precedente.
Es. Il redattore vuol fare avere ai suoi due assistenti una
copia di tutti gli articoli pubblicati da uno dei suoi giornalisti. Il
redattore stampa gli articoli per il primo assistente, nel mentre il
giornalista in questione pubblica un nuovo articolo; quando il redattore stampa
la seconda copia del plico per l’altro assistente, questo conterrà un articolo
in più. Di nuovo i due assistenti avranno in mano dei dati discordanti. Il caso
è molto simile a prima ma la vera differenza sta nel fatto che mentre la
nonrepeatable read riguardava l’aggiornamento di un articolo (ovvero l’update
di un record) ma entrambi gli assistenti avevano in mano lo stesso numero totale
di articoli, la phantom read implica una differenza nel numero di articoli totali
in possesso dei due assistenti (ovvero del numero totale di record).
In breve
Parlando di isolamento delle transazioni, questi tre casi
sono rappresentati in una specie di ordine gerarchico, dal più sporco al meno
sporco. Un livello di isolamento in cui si può verificare uno dei tre casi
implica a cascata che si possano verificare anche quelli “meno sporchi”, per il
principio secondo cui se rapini una banca probabilmente non ti fai molti
scrupoli a parcheggiare in divieto di sosta. Un livello di isolamento che
consente dirty read consentirà pertanto anche phantom read, ma non vale il
viceversa.
I livelli di isolamento
Non è affatto detto che vedere sempre un dato al massimo livello di aggiornamento sia un fatto negativo, ma ci sono dei casi in cui la priorità è avere un set di dati stabili, indipendentemente da quello che stanno facendo le transazioni concorrenti. Per questo motivo su SSMS abbiamo la possibilità di settare cinque diversi livelli di isolamento a seconda delle nostre esigenze, ciascuno dei quali consente o inibisce il verificarsi degli scenari descritti prima.
Dirty Read
Nonrepeatable
Read
Phantom
Read
Isolation
level
Read
uncommitted
Permesso
Permesso
Permesso
Read committed
Non permesso
Permesso
Permesso
Repeatable
read
Non permesso
Non permesso
Permesso
Serializable
Non permesso
Non permesso
Non permesso
Snapshot
Non permesso
Non permesso
Non permesso
Su SSMS il comando per settare il livello di isolamento è il seguente
SET TRANSACTION ISOLATION LEVEL <TuoLivello>;
Read uncommitted
Come si può notare dalla tabella, questo livello di
isolamento è il più permissivo di tutti, dato che consente addirittura la dirty
read, ovvero la lettura di dati modificati da un’altra transazione attualmente
in corso. Guardiamo con un esempio quello che succederebbe con due
transazioni in concorrenza tra loro.
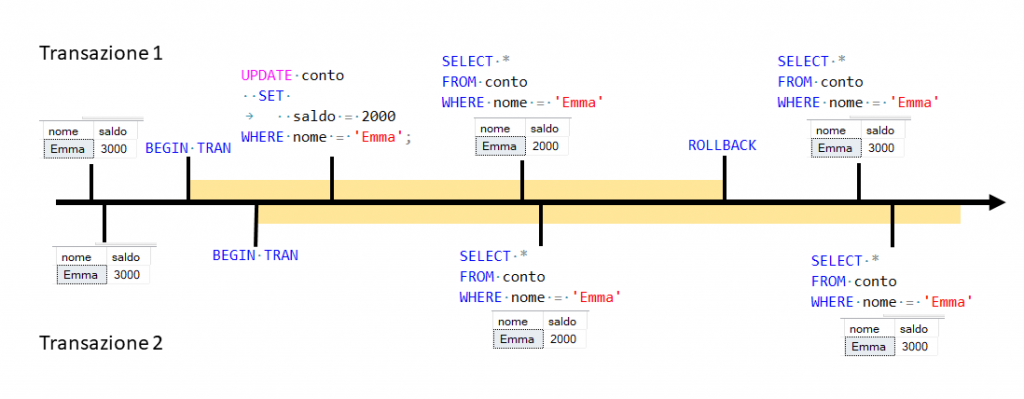
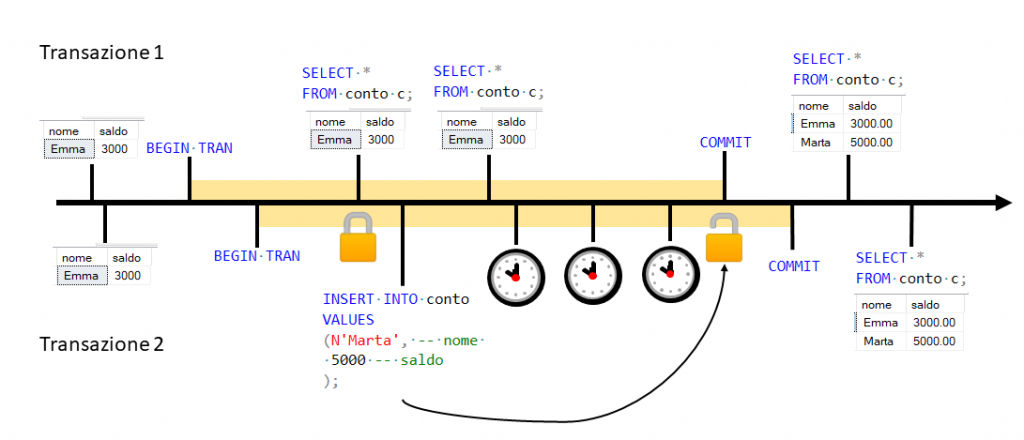
Figura 1
All’inizio sul conto di Emma ci sono 3000 €. La banca apre prima transazione, la seconda transazione è aperta da Emma che vuol vedere lo stato del suo conto. A questo punto la banca preleva i soldi dal conto di Emma per trasferirli su un altro conto. Con il livello di isolamento Read Uncommitted Emma è in grado di sapere in tempo reale quello che succede, ragion per cui vedrebbe il suo conto scendere a 2000 € anche se l’operazione non è stata ancora confermata. Supponiamo che qualcosa nella transazione vada storto e l’operazione sia annullata. A questo punto Emma vedrebbe i soldi sul suo conto tornare magicamente a 3000 €; veder fluttuare il proprio saldo senza apparente motivo è un’eventualità che molto probabilmente non piacerebbe a nessun utente.
Read committed
Questo è il livello predefinito del Motore di database di
SQL Server: in tale livello non è possibile per una transazione leggere i dati
modificati da un’altra transazione ma non ancora committati, scongiurando in
questo modo il pericolo di dirty read. La conseguenza di questa strategia è che
l’operazione di lettura di un dato modificato da un’altra transazione rimarrà
in attesa fino a quando la prima transazione non sarà stata committata.
Tuttavia a una transazione è consentito di visualizzare i
dati precedentemente letti (non modificati) da un’altra transazione senza
attendere il completamento della prima transazione. Questo, come vedremo, non ci
salvaguarda dall’eventualità che possano ancora verificarsi dei casi di
nonrepeatable read o phantom read.
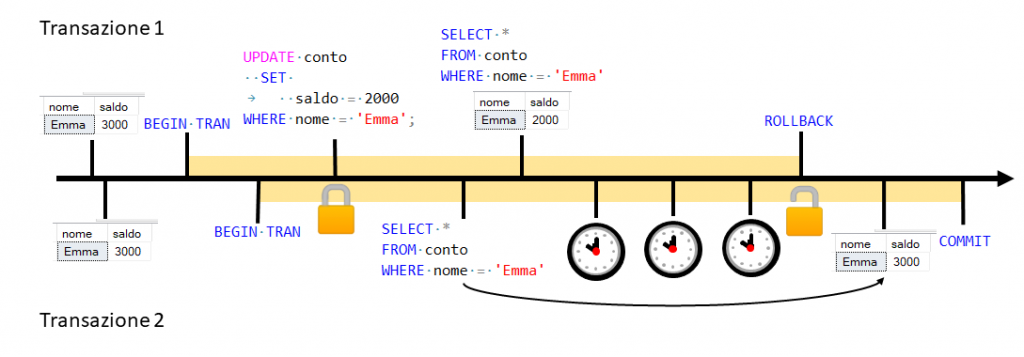
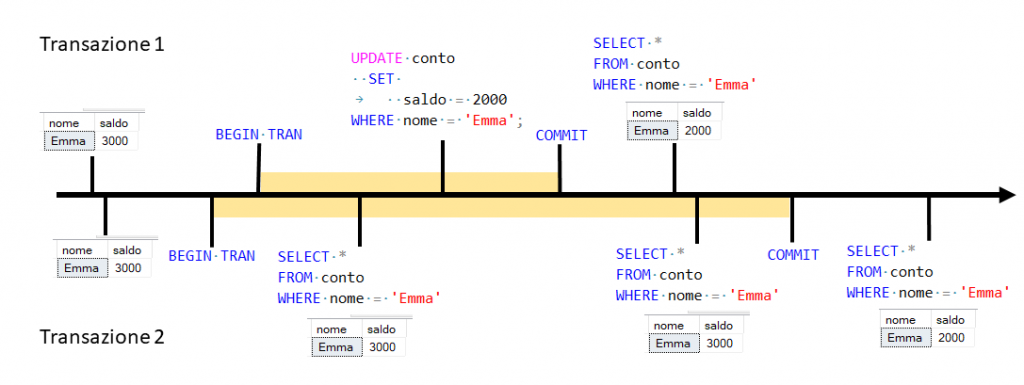
Figura 2
Figura 1
Qui siamo nello stesso caso di prima, ovvero la banca apre
la transazione per prelevare i soldi dal conto di Emma, Emma apre la seconda
transazione, ma dal momento in cui la prima transazione ha effettuato
un’operazione di modifica sul suo conto, Emma non può più vedere quello che sta
succedendo finché l’operazione concorrente non si conclude. In questo caso,
come nel caso illustrato prima, per qualche motivo l’operazione fallisce, ma
Emma non vedrà mai il suo conto in uno stato inconsistente. Il prezzo da pagare
ovviamente consiste nel dover aspettare che l’operazione di modifica da parte
della banca sia confermata da un commit o annullata da un rollback.
Figura 3
Se invece l’operazione va a buon fine abbiamo un caso lampante di nonrepeatable read, dato che Emma vede il valore del proprio saldo cambiare all’interno della sua transazione dopo che la banca conferma l’operazione con un commit. È importante rendersi conto che questo è un caso diverso dalla dirty read del primo esempio, dato che alla fine della sua transazione, pur se diverso dall’inizio, Emma ha davanti agli occhi un dato reale e confermato.
Repeatable Read
Qui il motore di database di SQL Server mantiene i lock di
lettura e scrittura sui dati selezionati fino alla fine della transazione. Pertanto
basta che una transazione sia aperta in lettura su un dato per fare sì che
questo dato non sia modificabile da altre transazioni, rendendo impossibile il
verificarsi di non-repeatable read. I casi di phantom read sono però ancora
possibili, come illustrato nell’esempio qui sotto: la stessa query infatti fornisce
due set di dati con un numero diverso di record totali all’interno della stessa
transazione.
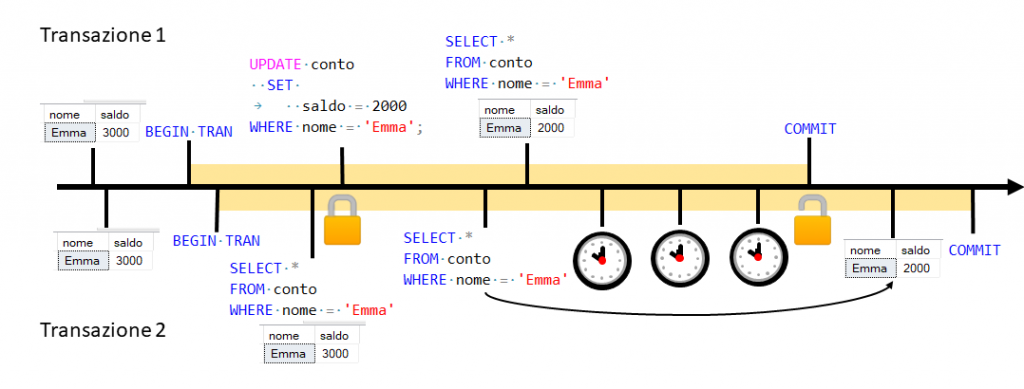
Figura 4
La transazione 1, aperta dall’impiegato 1 della banca, richiede di visualizzare tutti i conti attualmente attivi, ottenendo come risultato che l’unica correntista è Emma (probabilmente non si tratta di una banca molto grande). Nello stesso momento però l’impiegato 2 apre un nuovo conto a nome di Marta e conferma con un commit. Se a questo punto l’impiegato 1 inoltra nuovamente la richiesta di vedere i conti attualmente attivi, leggerà un record in più rispetto a quanto letto a inizio transazione (phantom read).
Serializable
Questo è il livello più alto di isolamento, in cui le
transazioni sono completamente isolate l’una dall’altra. Qui abbiamo che
Un dato non potrà essere letto se ci sono
transazioni in corso che hanno modificato quel dato
Nessuna transazione potrà modificare un dato che
sta venendo letto da una transazione in corso
Nessuna transazione potrà effettuare operazioni
di insert che soddisfino le condizioni di select di un’altra transazione in
corso
Il costo di un livello di isolamento così blindato consiste
nell’avere l’impatto più elevato sulle performance rispetto a tutti gli altri
livelli.
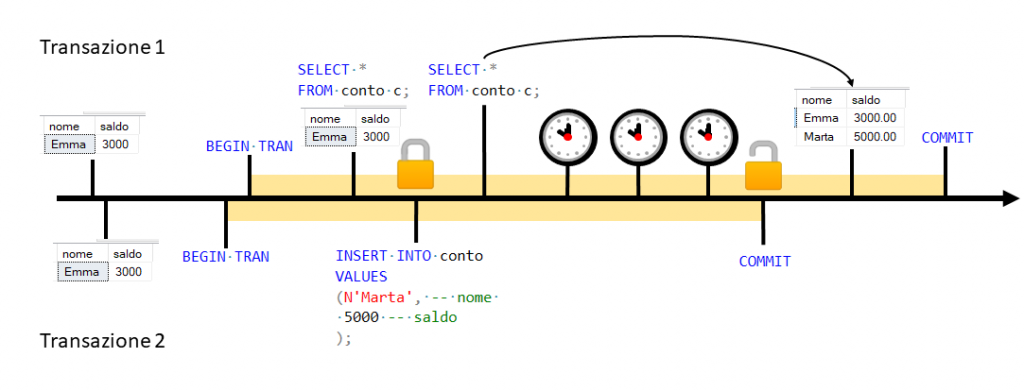
Figura 5
In questo esempio l’impiegato 1 (nella transazione 1)
effettua esattamente come prima un’operazione di visualizzazione dei conti
attivi. L’impiegato 2, che invece sta aprendo un nuovo conto a nome di Marta
(nella transazione 2), deve aspettare che l’impiegato 1 chiuda la sua
transazione per poter finalizzare la creazione del nuovo conto. A questo
livello di isolamento vediamo che è sufficiente compiere una select per
bloccare un’operazione di insert da parte di una transazione concorrente.
Snapshot
Il livello di isolamento snapshot utilizza il controllo
delle versioni delle righe per fornire coerenza di lettura a livello di
transazione. Se è impostato il livello snaphot, in caso di transazioni
concorrenti verrà letta la versione consistente più recente da quando è
iniziata la transazione, senza bloccare l’azione di lettura su un dato modificato
da un’altra transazione (come invece avviene nel livello serializable). In
comune con il livello serializable ha però il fatto di proteggerci
dall’eventualità di dirty read, nonrepeatable read e phantom read.
Figura 6
Qui Emma apre una transazione per sapere qual è il saldo del suo conto. Diversamente da prima la banca ha la possibilità di modificare tale saldo durante la transazione concorrente. Dopo l’aggiornamento da parte della banca (e conseguente commit), Emma continuerà a visualizzare la stessa cifra che vedeva all’inizio, prima che questa venisse modificata. La cifra aggiornata sarà disponibile alla lettura da parte di Emma solo dopo che anche lei avrà chiuso la sua transazione. L’inconveniente evidente del livello snapshot è che due utenti che stanno estraendo lo stesso dato nello stesso istante, potrebbero trovarsi di fronte a due valori differenti.
Conclusioni
Ma allora qual è il sistema migliore da adottare? La
risposta è, come al solito: dipende.
Quello che dobbiamo tenere presente è sempre il bilancio
costi / benefici, che si può esprimere essenzialmente in due modi dai nomi
variopinti, ovvero la concorrenza pessimistica e la concorrenza ottimistica.
Concorrenza pessimistica
È la via più intransigente: nel momento in cui un utente
compie un’operazione che porta ad un lock, gli altri utenti non possono
compiere nessuna operazione che vada in conflitto con quel lock finché non
viene rilasciato. Si chiama concorrenza pessimistica perché si basa sul
principio che molti utenti potrebbero intervenire contemporaneamente sugli
stessi dati, e quindi il costo di proteggere i dati con dei lock è inferiore
rispetto ad effettuare il rollback delle transazioni in conflitto tra loro.
Concorrenza ottimistica
In questo caso gli utenti non bloccano i dati quando li
leggono. Quando un utente aggiorna i dati, il sistema controlla se un altro
utente ha modificato i dati dopo che sono stati letti. Se un altro utente ha
aggiornato i dati, viene generato un errore. In genere, l’utente che riceve
l’errore subisce il rollback della transazione e deve ricominciare. Questo tipo
di concorrenza è chiamato ottimistico perché viene utilizzato principalmente in
ambienti in cui vi è una bassa contesa per i dati e dove il costo del rollback
occasionale di una transazione è inferiore al costo del blocco dei dati durante
la lettura.
Introduci la tua esperienza professionale dall’università fino all’ingresso in ORBYTA.
Mi sono laureata nel 2014 presso l’Università degli studi di Torino e da subito ho iniziato a lavorare in ambito amministrativo per piccole realtà. Dopo le prime esperienze professionali da neo laureata, mi sono avvicinata al mondo delle risorse umane in un’azienda di medie dimensioni del territorio piemontese. A fine 2017 sono stata contattata da ORBYTA per occuparmi a tutto tondo di risorse umane.
In questi anni ho potuto frequentare diversi corsi di formazione e aggiornamento nel mio settore che mi hanno permesso di sviluppare le mie competenze e verticalizzarle in ambiti definiti.
Di cosa ti occupi e che valore porti all’azienda?
In ORBYTA mi occupo di gestire e coordinare l’area delle risorse umane. Il valore aggiunto che porto è determinato dalla passione e dalla costante voglia di accrescere le mie competenze e quelle del mio team.
Ci piace avere un rapporto diretto e trasparente con ogni persona in azienda e tutti i giorni diamo il massimo per portare energia e senso di appartenenza tra le pareti dei nostri uffici, ma non solo.
Credo fortemente che condividere la vision aziendale sia un requisito fondamentale per riuscire a sviluppare un forte senso di engagement tra tutti.
Perché ti piace lavorare in ORBYTA?
Ci sono diversi fattori che mi rendono fiera e orgogliosa di lavorare in ORBYTA. Il primo fra tutti è sicuramente la stima che nutro per le persone con le quali mi interfaccio quotidianamente; il continuo confronto con ciascuna di esse mi permette di migliorare professionalmente e personalmente.
Subito dopo, ma strettamente collegato, vi è la forte energia che si percepisce; non esiste un giorno uguale all’altro e sicuramente la noia non è di casa!
In ultimo, di fondamentale importanza, c’è lo spirito di condivisione: ogni traguardo, ogni sfida, ogni obiettivo viene vissuto da tutti.
Le persone sono il grande valore dell’azienda e sapere che ciascuna di loro dà il massimo è un grandissimo risultato.
Introduci la tua esperienza professionale fino al ruolo che ricopri attualmente
Sono oramai più di 20 anni che lavoro nel mondo dell’Information Technology, ricoprendo tutti i ruoli possibili, dalla consulenza, allo sviluppo software, fino al management e coordinamento strategico. Ho avuto la possibilità di collaborare non solo con colleghi e clienti nazionali, ma anche europei ed extraeuropei. Direi che dalla Laurea in Informatica conseguita negli anni 90, parliamo dello scorso millennio, l’evoluzione tecnologica ha dato l’opportunità a me, come a tante altre persone nell’ambito, di poter evolvere ed imparare sempre qualche cosa di nuovo. Mi piace pensare che la mia esperienza professionale vive di un’evoluzione dinamica costante fatta di sfide tecnologiche e nuove avventure, anche digitali.
Perché hai scelto ORBYTA?
Perché sono appassionato di astronautica e non potevo trovare azienda migliore di questa (l’alternativa poteva essere SpaceX!!) 😀 Scherzi a parte, ho scelto ORBYTA perché qui ho trovato sin da subito tutte le caratteristiche fondamentali che ho sempre cercato all’interno del mondo lavorativo, quali professionalità, trasparenza, competenza e collaborazione, tutte adeguatamente bilanciate e contornate da una sana voglia di lavorare divertendosi.
Di cosa ti occupi e che valore porti all’azienda?
Il mio ruolo è quello di supportare il gruppo ORBYTA nel raggiungere gli obbiettivi sfidanti che si è posto per gli anni a venire, organizzando e gestendo la crescita in modo adeguato a poter cogliere le sfide che il mercato ci riserverà nel prossimo futuro. Sarà un vero piacere integrare la mia esperienza all’interno di una squadra già avviata ed affiatata in un percorso sinergico di gruppo, per supportare i clienti al cambiamento, all’evoluzione ed alla crescita in un mercato sempre più complesso e globale.
Creare un podcast in automatico a partire da audio vocali e musica
Nel 2011, mentre studiavo architettura al Politecnico di Torino e vivevo nel collegio universitario di Grugliasco, mi sono imbattuto in una delle più belle esperienze della mia vita. Insieme al mio amico Angelo ho progettato e realizzato una webradio studentesca che trasmetteva direttamente dal collegio. Il progetto, durato 5 anni è stato di grande scuola per me, sia dal punto di vista umano, sia professionale. Ero il classico “tecnico tutto fare” 🧑🔧 : in quel periodo mi sono occupato di piccoli software radiofonici, della programmazione e della gestione del palinsesto, ma ovviamente anche nella manutenzione del server della radio e dello studio dal quale trasmettevamo. Ho conosciuto piu di 60 ragazzi, divisi in gruppi di lavoro, uno per tramissione!
Nell’ultimo periodo (coinciso più o meno con l’ascesa dei podcast su Spotify) è tornata la mia curiosità verso il mondo della radio. Mi sono chiesto quanto fosse possibile migliorare/ottimizzare il processo di creazione di una trasmissione radiofonica o un podcast. Avevo già trattato quest’argomento in un precedente articolo in cui mi concentravo sul come mixare la voce di uno speaker insieme ad altri suoni. In questi giorni ho realizzato un piccolo script che passo passo crea un’intera trasmissione a partire da una cartella di files.
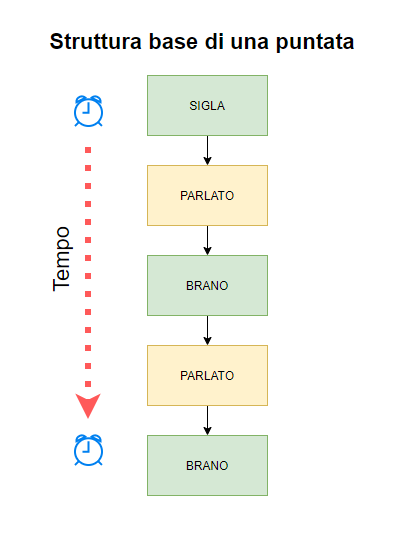
Struttura di una puntata radiofonica
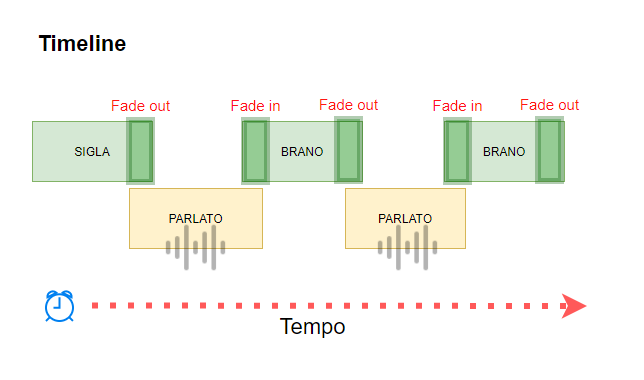
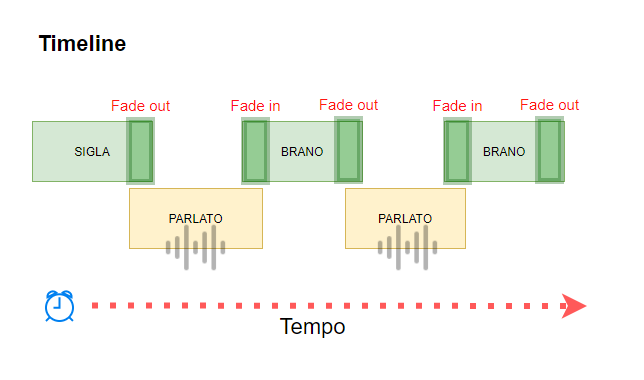
Per realizzare questo piccolo progetto ho utilizzato FFMPEG, nota libreria per la manipolazione del suono (leggi il mio articolo al riguardo con degli esempi d’uso). Questa libreria permette di applicare dei filtri al suono in maniera programmatica, quindi attraverso un linguaggio di programmazione. Studiando la ricchissima documentazione (e con l’aiuto dell’ottima community di FFMPEG) sono riuscito a realizzare questo Batch che programmaticamente mette in sequenza dei file audio, tramite l’uso di dissolvenze o somme di suoni. Vediamo uno schema:
Traducendo questo semplice schema in un codice programmabile, questo somiglia ad un array di oggetti (file audio) che dovranno essere messi in sequenza, ma a certe condizioni:
il parlato dovrà sempre avere un sottofondo leggero di musica
i brani partiranno con una dissolvenza (fade) nel momento in cui il parlato sta per finire
il parlato comincia un momento prima del termine del brano
Ecco uno schema piu preciso di quello che succederà:
Script per elaborare il parlato con un sottofondo
Questo script va eseguito con l’ultima versione di NodeJs installata, e richiede diverse librerie esterne, la piu importante è fluent-ffmpeg, ovvero un wrapper di FFMPEG per NodeJs. Lo script converte una serie di audio registrati con solo voce in diversi file in cui la voce è accompagnata da un sottofondo musicale leggero che parte e finisce in dissolvenza.
var mp3Duration = require('mp3-duration');
var ffmpeg = require('fluent-ffmpeg');
var fs = require('fs')
let array = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]; //un generico array di file audio di voce
let promises = [];
array.forEach(speech => {
let speechFile = speech + '.mp3';
let backgroundFile = 'sottofondo.mp3';
let backgroundLooped = speech + '_onlybackground.mp3';
let speechWithBackground = speech + '_.mp3'
let p = mp3Duration(speechFile, function (err, dur) {
//recupero la durata dello speech
let durataVoce = Math.round(dur);
//creo un loop della durata dello speech
ffmpeg(backgroundFile)
.inputOption("-stream_loop -1") //loop infinito del sottofondo
.audioFilters('afade=t=in:ss=0:d=8') //fadein che dura 8 secondi
.audioFilters('afade=t=out:st=' + (durataVoce - 10) + ':d=5') //fadeout che dura 8 secondi e parte 10 secondi prima della fine dell'audio
.duration(durataVoce) //taglio alla durata della voce
.audioBitrate(320)
.output(backgroundLooped)
.on('end', function () {
//faccio un mix con la voce
ffmpeg()
.addInput(backgroundLooped)
.addInput(speechFile)
.complexFilter(['[1]compand=attacks=0.4:points=-80/-80|-12.4/-12.4|-6/-8|0/-6.8|20/-2.8:gain=12:volume=-40[a1]',
'[a1]channelsplit=channel_layout=stereo:channels=FR[a2]',
'[0][a2]amix=inputs=2:dropout_transition=0.2:weights=1 10,dynaudnorm'])
.audioBitrate(320)
.save(speechWithBackground)
.on('end', function () {
//rimuovo il file del background
console.log(speech + " - Completato");
fs.unlinkSync(backgroundLooped);
});
}).run();
});
promises.push(p);
});
Script per mettere in sequenza i file audio
Una volta terminata l’elaborazione dei file audio del parlato, non ci resta che mixare il tutto seguendo lo schema precedente. I brani saranno leggermente anticipati rispetto al termine del parlato, in modo da accentuare l’effetto radiofonico finale. Ogni brano inizierà e finirà con una dissolvenza automatica di 10 secondi (impostata nella variabile fadeDuration). Inoltre verrà applicato un filtro normalizzazione audio, che consentirà di assottigliare le differenze di volume tra i brani, migliorando l’esperienza di ascolto.
var ffmpeg = require('fluent-ffmpeg');
let speeches = [
{
tipo: 'musica',
file: "sigla.mp3"
},
{
tipo: 'voce',
file: "1_.mp3"
},
{
tipo: 'musica',
file: "musica1.mp3"
},
{
tipo: 'voce',
file: "2_.mp3"
},
{
tipo: 'musica',
file: "musica2.mp3"
}
]
let command = ffmpeg();
let filters = [];
let combo = 0;
let fadeDuration = 10;
for (let i = 0; i < speeches.length; i++) {
//aggiungo l'input
speech = speeches[i];
command.addInput(speech.file);
successivo = i + 1;
//se sono all'ultimo non faccio niente perche mi interessa la combo precedente
if (i < speeches.length - 1) {
//se l'attuale è voce
if (speech.tipo == 'voce') {
//abbasso il volume della musica successiva
filters.push('[' + successivo + ']volume=0.3[low' + successivo + ']');
if (i < 1) {
filters.push('[' + i + '][low' + successivo + ']acrossfade=d=' + fadeDuration + ':c1=nofade:c2=exp[combo' + combo + ']');
} else {
output = '[combo' + (combo + 1) + ']';
if (successivo == speeches.length - 1) {
output = ",loudnorm";
}
filters.push('[combo' + combo + '][low' + successivo + ']acrossfade=d=' + fadeDuration + ':c1=nofade:c2=exp' + output);
combo++;
}
//se l'attuale è musica
} else if (speech.tipo == 'musica') {
if (i < 1) {
filters.push('[' + i + ']volume=0.4[low' + i + ']');
filters.push('[low' + i + '][' + successivo + ']acrossfade=d=' + fadeDuration + ':c1=exp:c2=nofade[combo' + combo + ']');
} else {
output = '[combo' + (combo + 1) + ']';
if (successivo == speeches.length - 1) {
output = ",loudnorm";
}
filters.push('[combo' + combo + '][' + successivo + ']acrossfade=d=' + fadeDuration + ':c1=exp:c2=nofade' + output);
combo++;
}
}
}
}
command.complexFilter(filters)
.save("totale1.mp3")
.audioBitrate(320)
.on('end', function () {
//rimuovo il file del background
console.log(" - Completato");
});
Risultato
Ho utilizzato questo piccolo script per realizzare una trasmissione di prova, a partire da un file vocale registrato con lo smartphone. Chiaramente è un progetto ancora molto semplice, ma che crea interessanti spunti su come automatizzare il processo di missaggio (mix) di puntate radiofoniche o podcast.
Articolo a cura di Carlo Peluso, 18.05.2021
Link articolo originale: https://straquenzu.p3lus0s.net/creare-un-podcast-in-automatico-a-partire-da-audio-vocali-e-musica
Introduzione alla teoria dei grafi per la teoria dei giochi
Nell’articolo
precedente (https://orbyta.it/teoria-dei-giochi/) abbiamo illustrato i principi
base della teoria dei giochi e, tramite qualche esempio, abbiamo scoperto come
può essere utilizzata per attuare la strategia più conveniente in una
situazione in cui il guadagno finale dipende dalle mosse effettuate dagli altri
giocatori.
In questo secondo articolo scopriremo cos’è la teoria dei grafi e come può essere integrata nella teoria dei giochi. Inoltre, introdurremo un altro tipo di equilibrio di Nash, ovvero gli equilibri di Nash per strategie miste.
La teoria dei grafi
I grafi possono essere utilizzati per schematizzare delle situazioni o processi e ne consentono l’analisi in termini quantitativi e algoritmici.
Tecnicamente,
un grafo
(o rete) G è una coppia (V, E) dove V
è un insieme finito i cui elementi sono detti
vertici onodi ed E è un
sottoinsieme i cui elementi, detti archi o lati, sono coppie di oggetti in
V.
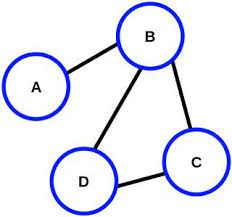
Per esempio, nella seguente immagine vediamo un grafo con vertici V={A,B,C,D} ed archi E={(A,B), (B,A), (B,D), (D,B), (D,C), (C,D), (B,C), (C,B)}.
Una
digrafo è un grafo che possiede
almeno un arco orientato, cioè un arco caratterizzato da un verso che non può essere percorso nel verso
opposto.
Per esempio modificando il grafo precedente come segue otteniamo un digrafo con archi E={(B,A), (B,D), (D,B), (D,C), (C,D), (B,C), (C,B)}.
Introduciamo ora qualche esempio pratico per capire come i grafi possono essere utilizzati nella teoria dei giochi.
Esempio numerico [4]
Consideriamo
una situazione in cui sono presenti due giocatori e il primo di essi, A,
sceglie un numero tra 1,2 e 3. Il
secondo partecipante, B, somma al numero detto
1,2 o 3. A farà lo stesso nel turno successivo
e così via finché uno dei due arriverà ad esclamare 31 vincendo.
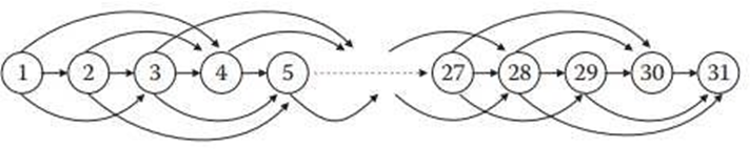
Tale
gioco può essere
rappresentato tramite il seguente digrafo:
I vertici sono i numeri
naturali dall’1 al 31 e gli archi
che partono dal vertice n entrano in quelli n+1, n+2 e n+3 se 1 ≤ n ≤ 28. Dal 29 escono degli archi entranti in 30 e 31, dal 30 in 31 e dal 31 nessuno.
Dunque, il giocatore che riesce
a dire 27 ha vinto perché il giocatore successivo potrà
selezionare solo i vertici 28, 29, o 30 e, in ognuno di questi casi, il primo
riuscirà a posizionarsi sul 31.
Possiamo quindi porci
come obiettivo di arrivare al 27 e non
al 31. Ma a questo
punto chi dirà
23 riuscirà a
vincere e, applicando il ragionamento iterativamente, concludiamo che i nodi da toccare per vincere sono X = {3, 7, 11,
15, 19, 23,
27, 31}.
Osserviamo che:
Se
un giocatore dice un numero non
appartenente a X allora l’avversario ha sempre la possibilità di farlo e dunque di vincere.
Se un giocatore dice
un numero appartenente a X allora
l’avversario non potrà
che scegliere un numero ad
esso non appartenente.
In conclusione, analizzando il grafo, scopriamo che l’obiettivo è quello di occupare sempre le posizioni di X.
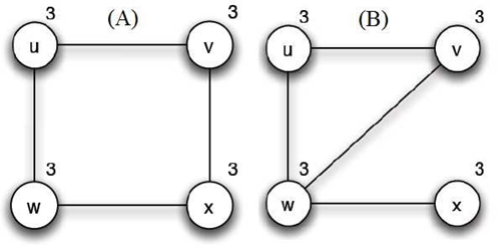
Esempio della protesta
Supponiamo di voler manifestare contro una data azione di un governo dittatoriale. Tale evento risulterà vantaggioso solo se il numero di manifestanti sarà sufficientemente elevato, d’altro canto se ciò non dovesse accadere andremmo in contro ad un payoff assai negativo in quanto potremmo supporre che, in tal caso, lo stato sederà la manifestazione in modo violento.
Supponiamo che ogni persona decida
di partecipare alla protesta solo
se sa che almeno un numero sufficiente di cittadini vi aderirà.
Supponiamo di avere 4 cittadini
e rappresentiamo il fatto che il
cittadino w conosca il comportamento
di quello u e viceversa con la presenza del lato (w,u). La cifra accanto a un
nodo indica il numero minimo
di manifestanti totali
affinché il nodo
in questione si unisca all’impresa.
Consideriamo le seguenti situazioni:
Notiamo
che nel caso A la rivolta non avrà luogo in quanto ognuno dei partecipanti non
ha modo di sapere il comportamento che adotterà il nodo ad esso non collegato.
Nel caso B invece ognuno tra u, v e w saprà che esistono almeno altri due nodi che richiedono almeno tre partecipanti totali e che a loro volta hanno questa informazione. Dunque la protesta si svolgerà, in particolare u, v e w saranno i manifestanti.
Equilibrio di Nash per
strategie miste
Esistono dei giochi in cui non sono presenti gli equilibri di Nash che abbiamo introdotto nell’articolo
precedente, ovvero quelli basati su strategia
pure. Una strategia pura infatti fornisce una descrizione completa
del modo in cui un individuo gioca una partita.
In particolare, essa determina quale scelta farà il giocatore in qualsiasi situazione che potrebbe
affrontare.
Una strategia
mista per un giocatore è una distribuzione di probabilità sull’insieme delle strategie pure che ha a disposizione. Ogni strategia pura P può essere vista come un caso
particolare di strategia mista che assegna probabilità pari a 1 a P e pari a 0
a tutte le altre strategie pure.
Abbiamo quindi due tipi di equilibri di Nash: quelli
per le strategie pure, analizzati finora, si hanno quando tutti i giocatori
hanno a disposizione solo strategie pure, altrimenti si parla di equilibri di
Nash per strategie miste.
Limitandoci ad un gioco a due partecipanti, un equilibrio
di Nash per le strategie miste è una coppia di scelte (che ora sono
probabilità) tale che ognuna sia la miglior risposta all’altra.
Introduciamo un esempio.
Esempio
dell’attaccante/difensore
Si consideri un gioco in cui c’è un attaccante A e un difensore D.
L’attaccante
può scegliere tra le strategie di attacco a1
o a2 mentre il difensore può difendersi da a1, e
quindi applicare la strategia d1, o viceversa difendersi da a2, e
quindi applicare la strategia d2.
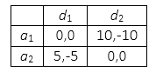
Supponiamo
che:
se D scegliesse la giusta strategia di difesa, cioè dicontro ai(i = 1, 2),
avremmo per A un guadagno di 0;
se
D scegliesse d1 e A scegliesse
a2, A otterrebbe un
guadagno di 5 e D una perdita pari;
se
D scegliesse d2 mentre A scegliesse a1, A ricaverebbe un guadagno
di 10 e D una perdita pari.
Riassumiamo la situazione del gioco nella seguente tabella indicando in ogni riquadro: a sinistra della virgola il guadagno ottenuto da A e a destra della virgola quello ottenuto da D.
Nel nostro esempio a1 e a2 sono le
strategie pure a disposizione dell’attaccante, mentre difendere da a1 e difendere da a2 quelle del difensore.
Dato che i due giocatori otterrebbero dei guadagni nettamente contrastanti potremmo
concludere che in questo
genere di giochi (detti strettamente competitivi) non esistano equilibri di
Nash.
Se
uno dei due giocatori sapesse il comportamento dell’altro allora potrebbe scegliere la strategia atta a massimizzare il suo profitto e inevitabilmente a minimizzare
quello dell’avversario. Ognuno dei giocatori cercherà
perciò di rendere
imprevedibile la propria strategia.
Sia
p la probabilità che A scelga a1 e q la probabilità che D scelga d1.
Per ora sappiamo solo che esiste
almeno un equilibrio per le strategie miste ma non quali debbano
essere i valori
effettivi di p e q.
Usiamo il principio secondo
cui un equilibrio misto sorge quando le probabilità
utilizzate da ciascun giocatore fanno sì che il suo avversario non abbia motivo
di preferire una delle due opzioni disponibili all’altra.
Se supponiamo che D abbia
una probabilità q di giocare
d1 allora
abbiamo che i possibili guadagni per A sono:
(0)(q) + (10)(1 − q) = 10 − 10q se scegliesse a1;
(5)(q) + (0)(1 − q) = 5q se scegliesse a2.
Per far in modo che per A sia indifferente scegliere tra a1 e a2 imponiamo 10−10q= 5q da cui q = 2/3.
Ora
supponiamo che A abbia una
probabilità p di mettere in atto a1. I possibili guadagni per D allora sono:
(0)(p) + (−5)(1 − p) = 5p − 5 se scegliesse d1
(−10)(p) + (0)(1 − p) = −10p se
scegliesse d2
Imponendo
5p − 5 = −10p otteniamo p = 1/3.
Quindi abbiamo
che gli unici possibili
valori di probabilità che possono
apparire nell’equilibrio per
la strategia mista sono p = 1/3 per l’attaccante e q = 2/3 per il difensore.
Si
noti inoltre che il guadagno atteso
di A nel caso in cui scelga a1
e D scelga d1 è di 10/3 e quello
di D è di -10/3.
Ciò
ci suggerisce un’analisi controintuitiva:
la probabilità di A di sferrare l’attacco più forte è di un terzo, ovvero, in un modello continuo, potremmo
immaginare che solo per un terzo
del tempo A provi ad attaccare
con a1.
Perché usare così poco la strategia più potente?
La risposta
è che se A provasse sempre ad attaccare con a1 allora D sarebbe persuaso
a rispondere spesso con d1,
il che ridurrebbe il payoff atteso da A. D’altro canto si consideri che poiché p = 1/3 fa sì che D scelga senza preferenza
una delle due strategie e abbiamo che, quando A usa tale valore di probabilità, allora, indipendentemente dalle scelte di
D, esso si assicura un payoff di 10/3.
Esempio delle imprese
Consideriamo ora il fatto che anche se un giocatore non ha una strategia dominante, esso potrebbe avere strategie che sono dominate da altre. Si consideri il seguente esempio.
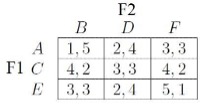
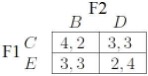
Supponiamo che due imprese, F1 e F2, stiano progettando di aprire un negozio in una delle sei città situate lungo sei uscite consecutive su una strada. Possiamo rappresentare la disposizione di queste città utilizzando un grafo a sei nodi come quello nella figura sottostante [2].
Supponiamo che F1 possa aprire il suo negozio in A, C o E mentre F2 in B, D o F. Una volta che i negozi apriranno, i clienti delle varie città faranno compere nel centro a loro più vicino. Si assuma che ogni città abbia lo stesso numero di clienti e che i guadagni dei negozi siano direttamente proporzionali al numero di clienti attirati. Otteniamo facilmente la tabella di guadagni sottostante.
Si può verificare che nessuno dei giocatori ha una strategia dominante: per esempio se F1 scegliesse la locazione A allora la risposta strettamente migliore di F2 sarebbe B, mentre se F1 scegliesse E la risposta strettamente migliore di F2 sarebbe D. Nonostante ciò notiamo che A è una strategia strettamente dominata per F1, infatti in ogni situazione in cui F1 ha l’opzione di scegliere A, esso riceverà un guadagno strettamente migliore scegliendo C. Analogamente F è una strategia strettamente dominata per F2. Abbiamo dunque che F1 non sceglierà A e F2 non sceglierà F. Possiamo a questo punto non considerare i nodi F e A, e da ciò ricaviamo la seguente tabella di payoff:
B ed E divengono
rispettivamente le nuove strategie strettamente dominate per F2 e F1 e quindi
possono essere a loro volta eliminate. Arriviamo alla conclusione che F1 sceglierà C e F2 D.
Questo
modo di procedere è chiamato cancellazione
iterativa delle strategie strettamente
dominate. Notiamo inoltre
che la coppia (C,D)
costituisce l’unico equilibrio di Nash del gioco ed infatti
questa metodologia di studio è anche utile a trovare gli equilibri
di Nash. Generalizziamo di seguito il processo
appena presentato.
Dato
un numero arbitrario di n giocatori abbiamo che la cancellazione iterativa
delle strategie strettamente dominate procede come segue:
Si
parte da un giocatore, si trovano tutte
le sue strategie strettamente dominate e le si eliminano;
Si considera
il gioco semplificato ottenuto. Si eliminano
eventuali nuove strategie strettamente dominate;
Si itera il processo finché non si trovano più strategie strettamente dominate.
Si può dimostrare che l’insieme degli equilibri di Nash della
versione originale del gioco coincide con quello della versione finale
così ottenuta.
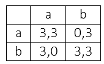
Consideriamo un problema in cui due giocatori A e B possano optare per la strategia a o b con i seguenti guadagni simmetrici:
In
questo caso a è una strategia debolmente
dominata poiché in ogni caso ogni giocatore può solo migliorare il suo
guadagno scegliendo b. Inoltre si noti che (b,b) è un equilibrio di Nash.
Quando abbiamo delle strategie debolmente dominate non è consigliabile procedere
con il metodo della cancellazione, poiché questa operazione potrebbe distruggere degli
equilibri.
D’altro canto
è intuitivo pensare che nessun
giocatore scelga di assecondare l’equilibrio (a,a) composto da strategie debolmente dominate se non ha modo di prevedere il comportamento dell’altro giocatore: perché non usare la strategia (b,b) che nel peggiore dei casi comunque non inficia
il guadagno?
In questo articolo abbiamo visto come la teoria dei grafi può essere usata in quella dei giochi andando a risolvere giochi che hanno dato risultati controintuitivi. Nel prossimo articolo, approfondiremo le reti andando a studiare situazioni più complesse che ci permetteranno di analizzare la propagazione delle strategie all’interno di una rete.
Bibliografia e sitografia
[2] D. Easley e J. Kleinberg, Networks, Crowds, and
Markets: Reasoning about a Highly Con- nected World, Cambridge University
Press, 2010.
[3] R.
Gibbons, Teoria dei giochi, Bologna, Il Mulino, 2005.
[4] E.
Martìn Novo e A. Mendez Alonso, Aplicaciones de la teoría de grafos a algunos
juegos de estrategia, numero 64 di Suma, Universidad Politécnica de Madrid,
2004.
[8] P.
Serafini, Teoria dei Grafi e dei Giochi, a.a. 2014-15 (revisione: 28 novembre
2014).
[9] I. S.
Stievano e M. Biey, Cascading behavior in networks, DET, Politecnico di Torino,
2015.
[10] I. S.
Stievano e M. Biey, Interactions within a network, DET, Politecnico di Torino,
2015.
[11] I. S.
Stievano, M. Biey e F. Corinto, Reti e sistemi complessi, DET, Politecnico di
Torino, 2015.
[12] A.
Ziggioto e A. Piana, Modello di Lotka-Volterra, reperibile all’indirizzo
http://www.itismajo.it/matematica/Lezioni/Vecchi%20Documenti%20a.s.%202011-12/Modello
%20di%20Lotka-Volterra.pdf,
consultato il 15/05/2015.
[15]
http://web.econ.unito.it/vannoni/docs/thgiochi.pdf consultato il 14/05/2015.
Articolo a cura di Monica
Mura e Carla Melia, Data Scientist in Orbyta Tech, 01.05.2021
ELISA CALCATERRA
Introduci la tua esperienza professionale dall’università fino all’ingresso in ORBYTA.
La mia esperienza professionale inizia durante il periodo universitario quando, per finanziare i miei studi presso la facoltà di Informatica, lavoravo part-time come barista.
Il mio percorso in Orbyta inizia al terzo anno di università quando ho avuto l’occasione di svolgere il tirocinio e il mio progetto di tesi in azienda.
Durante questo periodo formativo ho avuto il piacere di collaborare con persone propositive e di esperienza che mi hanno affiancato nello svolgimento delle attività.
Questo mi è bastato per decidere che Orbyta era l’azienda giusta nella qualle accrescere le mie competenze e diventare una figura professionale completa.
Di cosa ti occupi e che valore porti all’azienda?
Attualmente sono inserita all’interno del team di sviluppo mobile. Nello specifico, utilizzando Xamarin, sto sviluppando un’applicazione per Android e iOS; ho inoltre avuto l’occasione di partecipare allo sviluppo di applicazioni web approfondendo sia il lato back-end sia quello front-end.
Il valore che porto all’azienda è anche il mio punto di forza: la mia continua ricerca di nuove sfide. Non mi tiro mai indietro quando è necessario imparare nuove tecnologie per progetti innovativi.
Perché ti piace lavorare in ORBYTA?
Orbyta è un ambiente stimolante che, giorno dopo giorno, mi sta insegnato tanto sia a livello professionale sia a livello personale. Tutti i giorni ho la possibilità di accrescere le mie conoscenze e la mia esperienza nel campo ICT.
DANIELA CUTAIA
Introduci la tua carriera professionale fino al ruolo di CEO;
Tutto comincia con la mia laurea magistrale in giurisprudenza nel 2012 a seguito della quale intraprendo la pratica professionale forense, lavorando sia in ambito societario sia privatistico.
Al termine dei 18 mesi di praticantato ho sostenuto l’esame di stato per l’abilitazione all’esercizio della professione forense e così nel 2015 sono diventata avvocato.
Negli anni immediatamente successivi ho conseguito diverse specializzazioni frequentando dei master in materia di diritto societario e nel 2017 ho costituito, insieme a Fabio Aquila, la mia prima società, quella che è la attuale Orbyta Compliance.
Nel 2018 ho ceduto le mie quote della Orbyta Compliance alla capogruppo Orbyta per dedicarmi interamente alla professione forense fornendo supporto legale a tutte le società del Gruppo.
L’elevata sinergia tra le società del gruppo Orbyta e l’ambizione di offrire alle imprese servizi diversificati, ma al contempo integrati ha fatto sì che a gennaio 2021 sia maturata, insieme a Fabio Aquila e Lorenzo Sacco, l’idea di sviluppare l’area legale e di costituire la Orbyta Legal starl di cui attualmente rivesto il ruolo di CEO.
Qual è il valore che ORBYTA LEGAL ha portato al Gruppo ORBYTA?
Elemento che contraddistingue il gruppo Orbyta è il valore delle persone che ne costituiscono la linfa vitale, così come anche le competenze proprie di ciascuna delle società che lo compongono.
La presenza di una società di avvocati all’interno del gruppo offre la possibilità di essere sempre in linea con le novità normative, di disporre sempre del necessario supporto legale in ogni momento della vita societaria nonché di suggerire ai clienti le migliori soluzioni possibili con un riscontro quanto più possibile immediato ed efficace.
In che modo ORBYTA ha aiutato a realizzare i tuoi progetti?
L’ambiente stimolante e l’entusiasmo in Orbyta mi hanno aiutata molto, dandomi il supporto e la spinta motivazionale che mi serviva per compiere il grande passo dall’essere una libera professionista a diventare CEO di una Legal Firm.
Inoltre, aver avuto in questi anni il privilegio di seguire come avvocato un gruppo del calibro di ORBYTA, mi ha consentito di crescere professionalmente, e di affrontare tematiche stimolanti e di alto livello, cercando il più possibile di fornire un contributo di valore.
Se dovessi dare un consiglio a chi aspira ad aprire una società, quale sarebbe?
Il mio consiglio è di seguire sempre le proprie ambizioni. Quando si decide di intraprendere un progetto si incontrano inevitabilmente delle difficoltà, ma non bisogna arrendersi: è importante insistere sempre e credere profondamente in ciò che si fa. Sono una forte sostenitrice del potere della perseveranza e della resilienza, che credo siano decisivi per definire il successo di un progetto.
Introduzione alla teoria dei giochi: equilibri di Nash ed equilibri multipli
La teoria dei giochi è quella scienza matematica sviluppata al fine di capire quale sia la strategia migliore che un soggetto possa attuare in situazioni che mutano non solo al variare delle sue decisioni ma anche di quelle dei soggetti a esso connessi. Tale teoria, com’è facilmente intuibile, viene applicata a molti ambiti, per esempio quelli in cui ci si prefigge di studiare un piano di marketing o una politica proficua.
Un esempio che consigliamo si può trovare al seguente link:
Definiamo gioco una qualsiasi situazione in cui:
Esiste un insieme di partecipati che chiameremo giocatori;
Ogni giocatore ha a disposizione una serie di possibili opzioni di comportamento che chiameremo strategie;
Per ogni scelta di strategie ogni giocatore riceve un guadagno, detto anche payoff, generalmente rappresentato da un numero.
Ogni giocatore in generale cercherà di massimizzare il suo profitto ma non è detto che il suo unico interesse sia questo, infatti, potrebbe anche cercare si massimizzare il tornaconto di altri giocatori e, in tal caso, il concetto di guadagno andrà rivisto affinché esso descriva con completezza il grado di soddisfazione del soggetto.
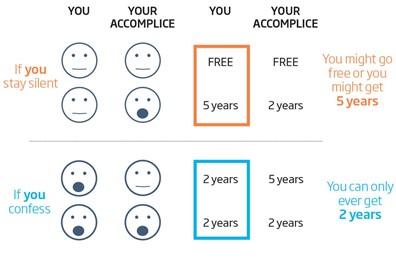
Nella teoria dei giochi è fondamentale il concetto dell’equilibrio di Nash sviluppato da John F. Nash, economista e matematico statunitense, i cui studi all’interno di questo ambito hanno portato allo sviluppo di quello che viene chiamato, il “dilemma del prigioniero”. Di seguito vediamo una sua rappresentazione schematica.
Rimandiamo al seguente video per una spiegazione più estesa di questo Dilemma:
Ora introduciamo qualche nuova definizione.
Una scelta di strategie, una per ogni giocatore, è socialmente ottimale se massimizza la somma dei guadagni di tutti i giocatori, mentre è Pareto-ottimale se non esiste un’altra combinazione di mosse tale che migliori i payoff di almeno un giocatore senza diminuire quello degli altri. Non lo dimostreremo qua per motivi di brevità ma se una soluzione è socialmente ottimale allora è anche Pareto-ottimale.
Supporremo che ogni giocatore conosca integralmente la struttura del gioco (cioè che il gioco sia completo) e quindi che sia a conoscenza di tutte le possibili strategie e guadagni di ogni partecipante. Inoltre, assumeremo che ogni partecipante sia intelligente (cioè in grado di capire, senza commettere errori, dato un insieme di strategie possibili quale sia la più conveniente) e razionale (cioè tale che, una volta riconosciuta la/le strategia/e a massimo profitto la/le preferisca alle altre [14]).
Modelli in cui tali assunzioni non vengono fatte possono divenire estremamente complicati e non li approfondiremo nel corso di questa trattazione.
Si consideri il seguente esempio tratto dal sesto capitolo di [2].
Esempio degli studenti
Uno studente deve affrontare un esame e una presentazione per il giorno seguente ma non può prepararsi adeguatamente per entrambe. Per semplicità supponiamo che egli sia in grado stimare con ottima precisione quale sarà il voto ottenuto (calcolato in centesimi) da entrambe le prove al variare della sua preparazione.
In particolare, per quel che riguarda l’esame lo studente si aspetta una votazione pari a 92 se studia e di 80 altrimenti. La presentazione, invece, deve essere fatta con un compagno e nel caso in cui entrambi lavorino su di essa la votazione relativa sarà di 100, se solo uno dei due (indipendentemente da chi) ci lavorasse di 92 e se non lo facesse nessuno di 84. Anche il compagno deve scegliere se studiare per l’esame o concentrarsi sulla preparazione e le sue previsioni sui voti sono le stesse.
Si presuma infine che i due compagni non possano comunicare e quindi mettersi d’accordo sul da farsi. L’obiettivo per entrambi è quello di massimizzare il valore medio delle due votazioni che poi andrà a costituire il voto definitivo. Schematizziamo di seguito i possibili risultati:
Se entrambi preparassero la presentazione prenderebbero 100 in essa e 80 nell’esame ottenendo quindi una votazione finale di 90;
Se entrambi studiassero per l’esame prenderebbero 92 in esso e 84 nella presentazione per una media di 88;
Se uno studiasse per l’esame e l’altro preparasse la presentazione avremmo che quest’ultimo prenderebbe 92 in essa ma 80 nell’esame arrivando a una media di 86, mentre l’altro prenderebbe anch’esso 92 per la presentazione (poiché ci avrebbe lavorato l’altro) e 92 all’esame ottenendo una media di 92.
Cos’è meglio fare quindi? Possiamo ragionare in questo modo:
Se si sapesse che il compagno studierà per l’esame, lo studente dovrebbe scegliere di fare lo stesso in quanto ciò gli permetterebbe di ottenere una votazione media di 88, mentre focalizzarsi sulla presentazione di 86;
Se si sapesse che il compagno preparerà la presentazione, lo studente dovrebbe scegliere di studiare perché così otterrebbe una media finale di 92 mentre in caso contrario di 90.
Possiamo dunque concludere che la miglior cosa da fare sarebbe, in ogni caso, studiare per l’esame.
Quando, come nell’esempio presentato, un giocatore ha una strategia strettamente più conveniente delle altre, indipendentemente dal comportamento degli altri giocatori, chiameremo tale scelta strategia strettamente dominante e, supponendo la razionalità del soggetto, daremo per scontato che la adotti.
Nell’esempio precedente, per la stessa natura del problema, ci aspettiamo un comportamento simmetrico da parte dei due giocatori che dunque sceglieranno entrambi di studiare ottenendo la votazione complessiva di 88.
È interessante però notare che se gli studenti avessero potuto accordarsi sul preparare entrambi la presentazione il risultato finale non sarebbe variato, infatti, in tal caso, lo studente si sarebbe aspettato un voto medio di 90 e dunque avrebbe deciso di studiare per l’esame sapendo che l’altro avrebbe preparato la presentazione, infatti ciò gli permetterebbe di raggiungere il 92.
In realtà, tale piano non avrebbe funzionato perché, a una più attenta analisi, ci si accorge che anche il compagno, in un’ottica meccanicamente razionalistica incentrata sulla massimizzazione del proprio profitto, avrebbe attuato allo stesso modo e dunque entrambi avrebbero ottenuto un punteggio medio di 88, mentre, non giocando razionalmente, avrebbero potuto raggiungere la votazione di 90.
Un’ultima “definizione” prima di spiegare un tema centrale della teoria dei giochi: senza entrare in tecnicismi diremo che in pratica la miglior risposta è la scelta più conveniente che un giocatore, che crede in un dato comportamento degli altri giocatori, possa fare.
Equilibrio di Nash
Consigliamo vivamente di guardare questo video tratto dal celeberrimo film “A Beautiful Mind” prima di proseguire.
Dato un gioco, se nessuno dei partecipanti ha una strategia strettamente dominante, per predire l’evolversi della situazione, introduciamo il concetto di equilibrio di Nash secondo cui, in una situazione del genere, dobbiamo aspettarci che i giocatori usino le strategie che danno le migliori risposte le une alle altre.
Si rimanda a [13] per una definizione più precisa, ma in pratica, se un gioco ammette almeno un equilibrio di Nash, ogni partecipante ha a disposizione almeno una strategia S1 alla quale non ha alcun interesse ad allontanarsi se tutti gli altri giocatori hanno giocato la propria strategia Sn. Questo perché se il giocatore i giocasse una qualsiasi altra strategia a sua disposizione, mentre tutti gli altri hanno giocato la propria strategia se, potrebbe solo peggiorare il proprio guadagno o, al più, lasciarlo invariato. Poiché questo vale per tutti i giocatori se esiste uno e un solo equilibrio di Nash, esso costituisce la soluzione del gioco in quanto nessuno dei giocatori ha interesse a cambiare strategia.
In altre parole si definisce equilibrio di Nash un profilo di strategie (una per ciascun giocatore) rispetto al quale nessun giocatore ha interesse ad essere l’unico a cambiare.
Esistono però giochi che presentano più equilibri di Nash.
Equilibri multipli: giochi di coordinazione
Si supponga, riprendendo l’esempio precedente, che gli studenti debbano preparare, una volta essersi divisi il lavoro, le slide della presentazione. Lo studente, senza possibilità di comunicare col compagno, deve decidere se creare le slide col programma A o col programma B considerando che sarebbe molto più facile unirle a quelle del compagno se fossero fatte con lo stesso software.
Un gioco di questo tipo è detto di coordinazione perché l’obiettivo dei due giocatori è quello di coordinarsi. In questo caso notiamo che ci sono più equilibri di Nash, cioè (A,A) e (B,B). Cosa bisogna aspettarsi?
La teoria dei punti focali (detti anche punti di Schelling) ci dice che possiamo usare caratteristiche intrinseche del gioco per prevedere quale equilibrio sarà quello scelto, cioè quello in grado di dare a tutti i giocatori un guadagno maggiore. Thomas Schelling ne “La strategia del conflitto” descrive un punto focale come: “l’aspettativa di ogni giocatore su quello che gli altri si aspettano che lui si aspetti di fare[7].
Per esempio, ritornando al gioco degli studenti, se lo studente S1 sapesse che il compagno S2 predilige A, allora sceglierà A, infatti sapendo che S2 a sua volta sa che lui è a conoscenza di questo fatto assumerà che quest’ultimo sceglierà effettivamente A sapendo che S1 si conformerà di conseguenza.
Schelling illustra questo concetto tramite il seguente esempio: “domani devi incontrare un estraneo a New York, che luogo e ora sceglieresti?”
Questo è un gioco di coordinamento, dove tutti gli orari e tutti i luoghi della città possono essere una soluzione di equilibrio. Proponendo il quesito a un gruppo di studenti constatò che la risposta più comune era: “alla Grand Central Station a mezzogiorno”. La GCS non è un luogo che porterebbe a un guadagno maggiore (il giocatore potrebbe facilmente incontrare qualcuno al bar, o in un parco), ma la sua tradizione come luogo di incontro la rende speciale e costituisce, perciò, un punto di Schelling. Nella teoria dei giochi un punto di Schelling è una soluzione che i giocatori tendono ad adottare in assenza di comunicazione, poiché esso appare naturale, speciale o rilevante per loro.
La teoria dei giochi ben si combina con quella dei grafi e la introdurremo nei prossimi articoli per vedere altri esempi di come possa esistere un possibile conflitto tra razionalità individuale, nel senso di massimizzazione dell’interesse personale, ed efficienza, ovvero la ricerca del miglior risultato possibile, sia individuale sia collettivo.
Abbiamo anche visto che applicando una strategia individualistica si ottiene a volte un esito inferiore rispetto a quanto ottenibile nel caso in cui si possa raggiungere un accordo e che se esiste un equilibrio di Nash ed è unico, esso rappresenta la soluzione del gioco poiché nessuno dei giocatori ha interesse a cambiare strategia.
Bibliografia e sitografia
[1] R. Dawkins, Il gene egoista, I edizione collana Oscar saggi, Arnoldo Mondadori Editore, 1995.
[2] D. Easley e J. Kleinberg, Networks, Crowds, and Markets: Reasoning about a Highly Con- nected World, Cambridge University Press, 2010.
[3] R. Gibbons, Teoria dei giochi, Bologna, Il Mulino, 2005.
[4] S. Rizzello e A. Spada, Economia cognitiva e interdisciplinarità, Giappichelli Editore, 2011.
[5] G. Romp,Game Theory: Introduction and Applications, Mishawaka, Oxford University Press, 1997
[6] T. C. Schelling, The Strategy of Conflict, Cambridge, Massachusetts: Harvard, University Press, 1960.
[7] P. Serafini, Teoria dei Grafi e dei Giochi, a.a. 2014-15 (revisione: 28 novembre 2014).
Articolo a cura di Carla Melia e Lucia Campomaggiore, Data Scientist in Orbyta Tech, 25.03.2021
Su questo sito utilizziamo cookie tecnici necessari alla navigazione e funzionali all’erogazione del servizio. Utilizziamo i cookie anche per fornirti un’esperienza di navigazione sempre migliore, per facilitare le interazioni con le nostre funzionalità social.
Puoi esprimere il tuo consenso cliccando su ACCETTA TUTTI.
I cookie necessari sono assolutamente essenziali per il corretto funzionamento del sito web. Questi cookie garantiscono le funzionalità di base e le caratteristiche di sicurezza del sito web, in modo anonimo.
Cookie
Durata
Descrizione
__hssrc
session
This cookie is set by Hubspot whenever it changes the session cookie. The __hssrc cookie set to 1 indicates that the user has restarted the browser, and if the cookie does not exist, it is assumed to be a new session.
cookielawinfo-checkbox-analytics
11 months
Questo cookie è impostato dal plug-in GDPR Cookie Consent. Il cookie viene utilizzato per memorizzare il consenso dell'utente per i cookie nella categoria "Analytics".
cookielawinfo-checkbox-functional
11 months
Il cookie è impostato dal consenso cookie GDPR per registrare il consenso dell'utente per i cookie nella categoria "Funzionali".
cookielawinfo-checkbox-necessary
11 months
Questo cookie è impostato dal plug-in GDPR Cookie Consent. I cookie vengono utilizzati per memorizzare il consenso dell'utente per i cookie nella categoria "Necessari".
cookielawinfo-checkbox-others
11 months
Questo cookie è impostato dal plug-in GDPR Cookie Consent. Il cookie viene utilizzato per memorizzare il consenso dell'utente per i cookie nella categoria "Altri.
cookielawinfo-checkbox-performance
11 months
Questo cookie è impostato dal plug-in GDPR Cookie Consent. Il cookie viene utilizzato per memorizzare il consenso dell'utente per i cookie nella categoria "Prestazioni".
JSESSIONID
session
Utilizzato da siti scritti in JSP. Cookie di sessione della piattaforma per scopi generici che vengono utilizzati per mantenere lo stato degli utenti attraverso le richieste di pagina.
viewed_cookie_policy
11 months
Il cookie è impostato dal plug-in GDPR Cookie Consent e viene utilizzato per memorizzare se l'utente ha acconsentito o meno all'uso dei cookie. Non memorizza alcun dato personale.
I cookie funzionali aiutano a eseguire determinate funzionalità come condividere il contenuto del sito Web su piattaforme di social media, raccogliere feedback e altre funzionalità di terze parti.
Cookie
Durata
Descrizione
__cf_bm
30 minutes
Questo cookie, impostato da Cloudflare, viene utilizzato per supportare la gestione dei bot di Cloudflare.
__hssc
30 minutes
HubSpot imposta questo cookie per tenere traccia delle sessioni e per determinare se HubSpot deve incrementare il numero di sessione e i timestamp nel cookie __hstc.
bcookie
2 years
LinkedIn imposta questo cookie dai pulsanti di condivisione di LinkedIn e aggiunge tag per riconoscere l'ID del browser.
lang
session
Questo cookie viene utilizzato per memorizzare le preferenze di lingua di un utente per fornire contenuti in quella lingua memorizzata la prossima volta che l'utente visita il sito web.
lidc
1 day
LinkedIn imposta il cookie lidc per facilitare la selezione del data center.
I cookie per le prestazioni vengono utilizzati per comprendere e analizzare gli indici di prestazioni chiave del sito Web che aiutano a fornire una migliore esperienza utente per i visitatori.
I cookie analitici vengono utilizzati per capire come i visitatori interagiscono con il sito web. Questi cookie aiutano a fornire informazioni sulle metriche del numero di visitatori, della frequenza di rimbalzo, della sorgente del traffico, ecc.
Cookie
Durata
Descrizione
__hstc
1 year 24 days
This is the main cookie set by Hubspot, for tracking visitors. It contains the domain, initial timestamp (first visit), last timestamp (last visit), current timestamp (this visit), and session number (increments for each subsequent session).
_ga
2 years
Il cookie _ga, installato da Google Analytics, calcola i dati di visitatori, sessioni e campagne e tiene anche traccia dell'utilizzo del sito per il report di analisi del sito. Il cookie memorizza le informazioni in modo anonimo e assegna un numero generato casualmente per riconoscere i visitatori unici.
_gat_gtag_UA_162571803_1
1 minute
This cookie is set by Google and is used to distinguish users.
_gid
1 day
Installato da Google Analytics, il cookie _gid memorizza informazioni su come i visitatori utilizzano un sito web, creando anche un report analitico delle prestazioni del sito web. Alcuni dei dati raccolti includono il numero di visitatori, la loro fonte e le pagine che visitano in modo anonimo.
CONSENT
16 years 3 months 10 days 7 hours 5 minutes
Questi cookie vengono impostati tramite video di YouTube incorporati. Registrano dati statistici anonimi su ad esempio quante volte viene visualizzato il video e quali impostazioni vengono utilizzate per la riproduzione. Nessun dato sensibile viene raccolto a meno che non accedi al tuo account google, in tal caso le tue scelte sono legate al tuo account, ad esempio se fai clic su "mi piace" su un video.
hubspotutk
1 year 24 days
Questo cookie viene utilizzato da HubSpot per tenere traccia dei visitatori del sito web. Questo cookie viene passato a Hubspot all'invio del modulo e utilizzato durante la deduplicazione dei contatti.
I cookie pubblicitari vengono utilizzati per fornire ai visitatori annunci e campagne di marketing pertinenti. Questi cookie tengono traccia dei visitatori sui siti Web e raccolgono informazioni per fornire annunci personalizzati.
Cookie
Durata
Descrizione
bscookie
2 years
Questo cookie è un cookie ID del browser impostato dai pulsanti di condivisione collegati e dai tag degli annunci.
IDE
1 year 24 days
I cookie di Google DoubleClick IDE vengono utilizzati per memorizzare informazioni su come l'utente utilizza il sito Web per presentargli annunci pertinenti e in base al profilo dell'utente.
test_cookie
15 minutes
Il test_cookie è impostato da doubleclick.net e viene utilizzato per determinare se il browser dell'utente supporta i cookie.
VISITOR_INFO1_LIVE
5 months 27 days
Un cookie impostato da YouTube per misurare la larghezza di banda che determina se l'utente ottiene la nuova o la vecchia interfaccia del lettore.
YSC
session
Il cookie YSC è impostato da Youtube e viene utilizzato per tenere traccia delle visualizzazioni dei video incorporati nelle pagine di Youtube.
yt-remote-connected-devices
never
YouTube imposta questo cookie per memorizzare le preferenze video dell'utente utilizzando il video YouTube incorporato.
yt-remote-device-id
never
YouTube imposta questo cookie per memorizzare le preferenze video dell'utente utilizzando il video YouTube incorporato.
yt.innertube::nextId
never
Questi cookie vengono impostati tramite video di YouTube incorporati.
yt.innertube::requests
never
These cookies are set via embedded youtube-videos.